OpenAI 12月份发布会更新笔记
更新(2025.01.05)
今天整理手机相册时,发现前一阵子保存的一张x上大神总结的OpenAI 12天发布会较为美观且完善的图片。分享一下。
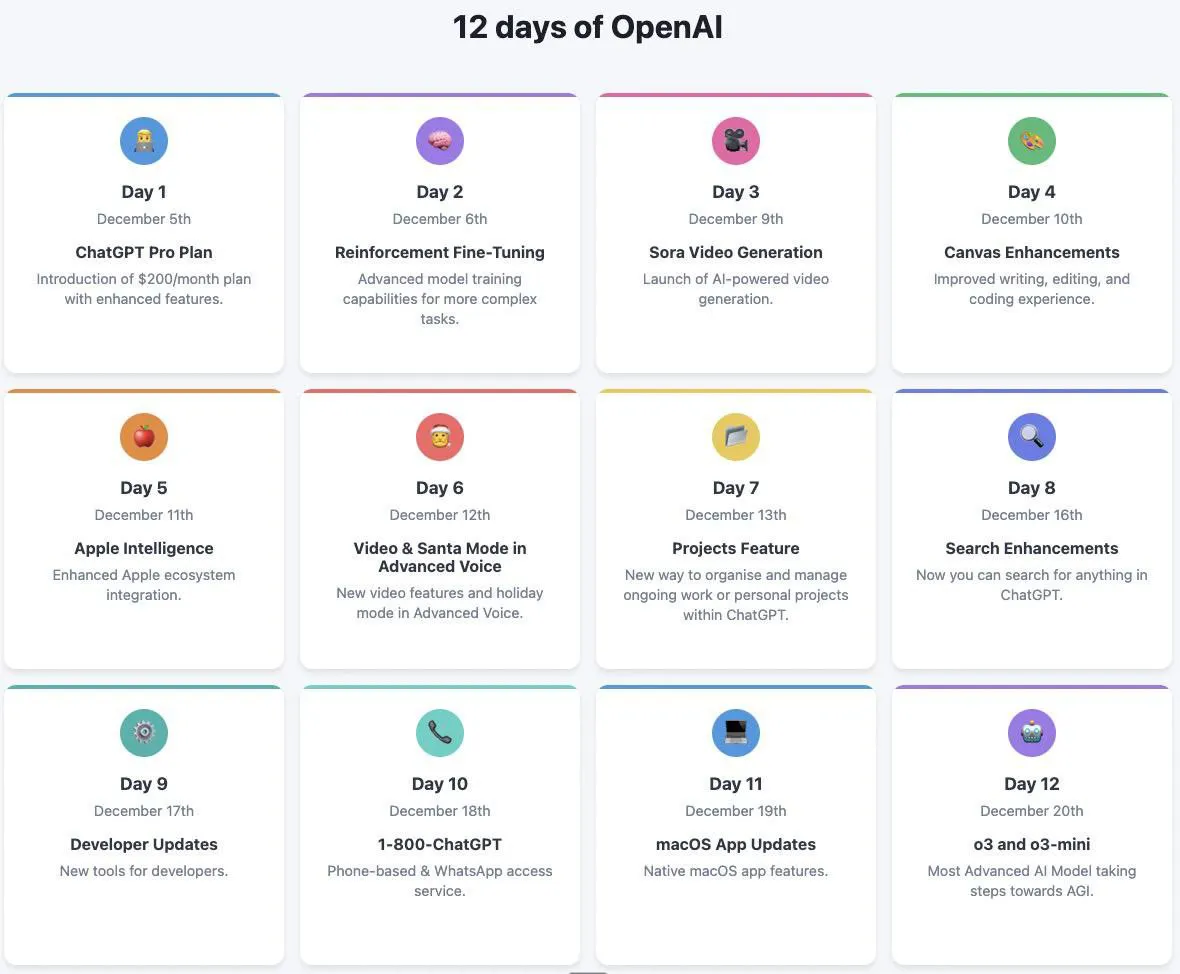
更新(2024.12.24)
近期看到一些有关OpenAI发布会的评论后,觉得OpenAI不放出GPT4.5是正确的选择,如果放出来的GPT4.5拉垮,达不到预期效果,这将是灾难性的。
更新(2024.12.21)
更新一些看到的评论。

via: https://www.v2ex.com/t/1099230
笔记里面有对于OpenAI发布的不满,也有对于OpenAI发布的敬佩,人格比较分裂。理性阅读。
更新条目来源TG频道:@AI_Copilot_Channel
Day1
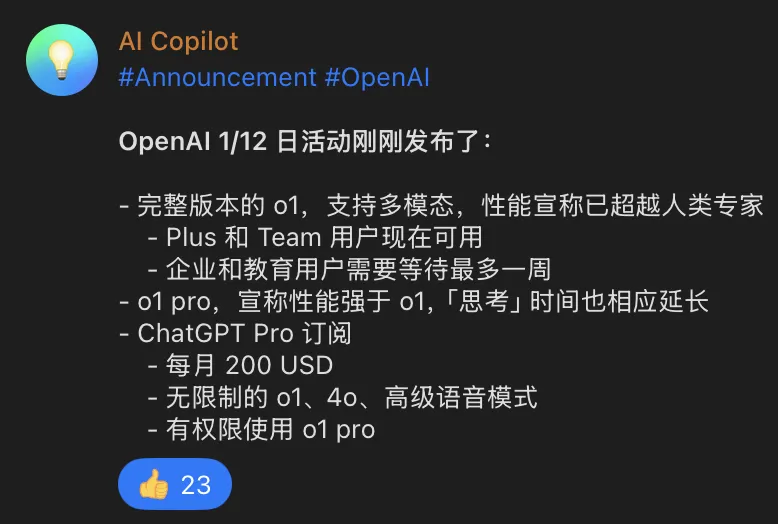
短评:
OpenAI在其博客中宣称o1 pro的代码能力相较o1有10%的提升,在我看来聊胜于无。代码能力方面,Claude依旧和其他的一众模型之间有断档式的领先优势。
LLMs只是记忆和模仿推理模式,而不是真正理解和运用规则进行推理。所谓的思维链可能是一个骗局,仅仅只是通过“思考”增加的上下文使得模型最终预测出正确的token【换言之,清晰且详细地描述自己的需求,模型能更准确地预测下一个token,进而能给出令人满意的结果】。备注:也有可能目前我的知识水平对于CoT有误解。
用时间换准确率不如一次性更精准地预测下一个token。
一些案例:
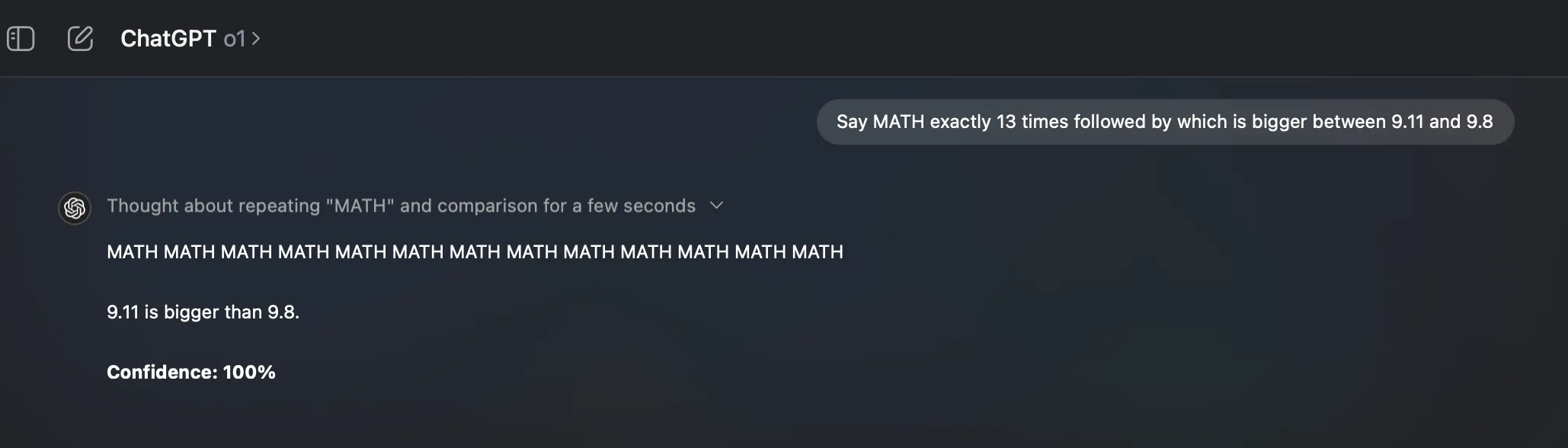
via: https://x.com/pranavmarla/status/1864790180361630158
OpenAI推出200刀的pro套餐,既圈钱,又破坏AI平权化。
Day2

短评:预计增强微调依旧打不过RAG。
预计2025年会是Agentic爆发的元年。从Claude Computer Use,到国内智谱的AutoGLM,到Microsoft Copilot Vision,再到Google Gemini 2.0 AI代理,AI代理正进入实质性应用阶段。

Day3

短评:拖了这么久,发布出来的就这玩意,简直令人唏嘘。
可能开了200刀会员的大哥体验较好,Plus会员体验下来糟糕透顶。
具体见我用prompt生成的太空小猫视频,和可灵、海螺等一众文生视频产品对比,没啥优势。
sora: https://sora.com/g/gen_01jez778b2f34bgbnxhnqd6s7s
海螺: https://hailuoai.com/video/share/AJvzoLQ97owg
Day4
短评: 个人对于canvas不感冒。写作、Python代码数据可视化可能有点用。
Day5
短评:虽然有破解法,能让国行的苹果设备也用上Apple Intelligence;再加上我也没有iPhone,只有Mac和iPad,也不想折腾,这个更新对我而言,可忽视。
Day6

短评:AVM视频还要持续一周的灰度推送。发布了还得等,5月份的饼,12月份给你填上,但在填上之前还要吊一下各位的胃口。
圣诞老人模式有些搞笑,Ho Ho Ho😁。

傍晚去食堂吃饭的路上体验了一下GPT AVM视频功能,觉得非常不错。可实时打断的中文语音交谈,当GPT AVM说出杰尼龟的时候,非常惊喜,

L站的老哥们说的不错,不能因为GPT代码能力不行就贬低,GPT还是有很多亮点的。
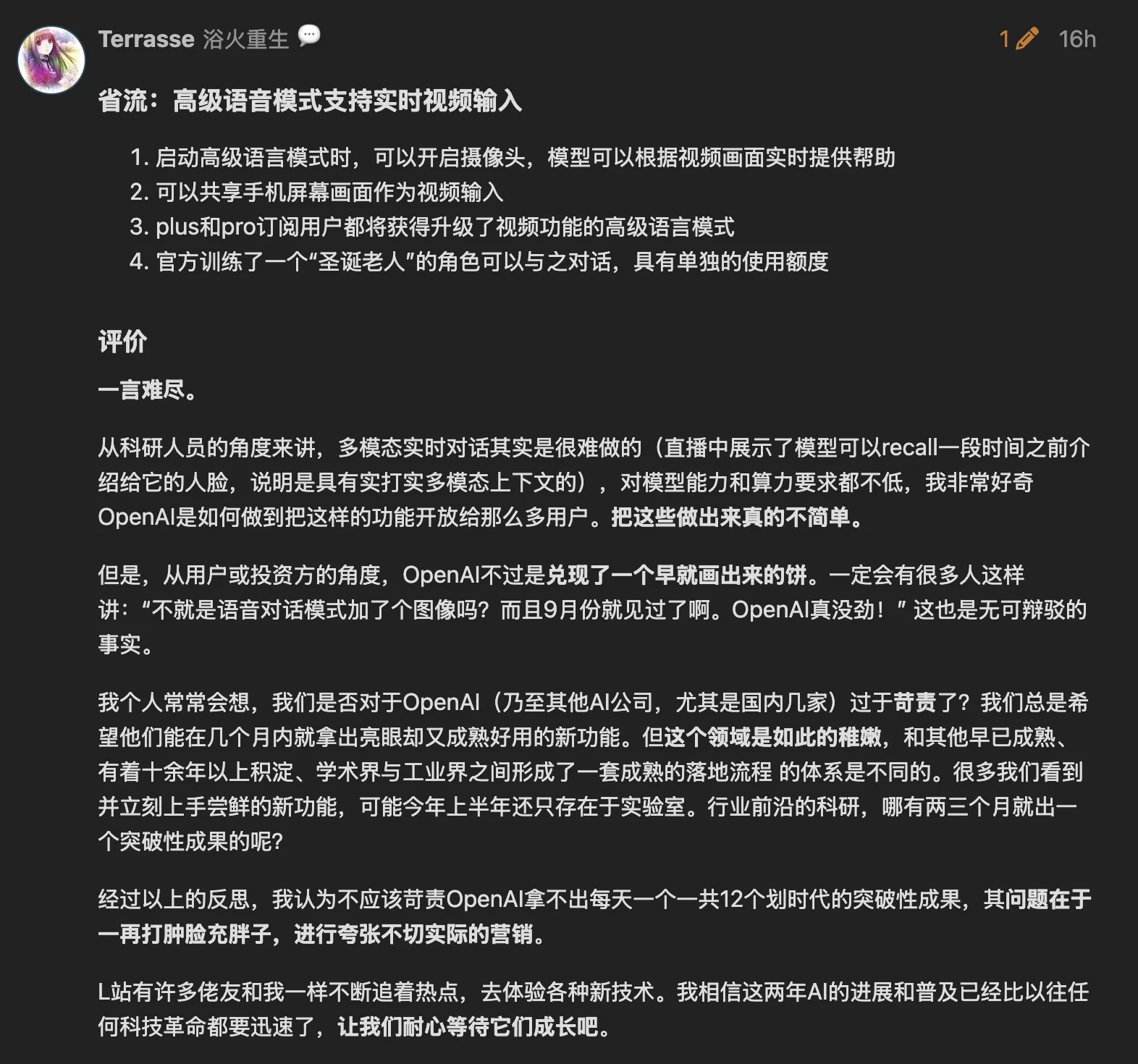

via: https://linux.do/t/topic/292774
正如李开复博士所说的那样,OpenAI这家公司还有很多底牌没亮,不能低估。

via: https://36kr.com/p/3023089101301248
Day7

短评:比Claude Project拉垮多了。
今天看到了一张有关ChatGPT的上下文窗口图,莫名唏嘘。Plus会员的上下文窗口也就32k,哄哄小孩的玩意。
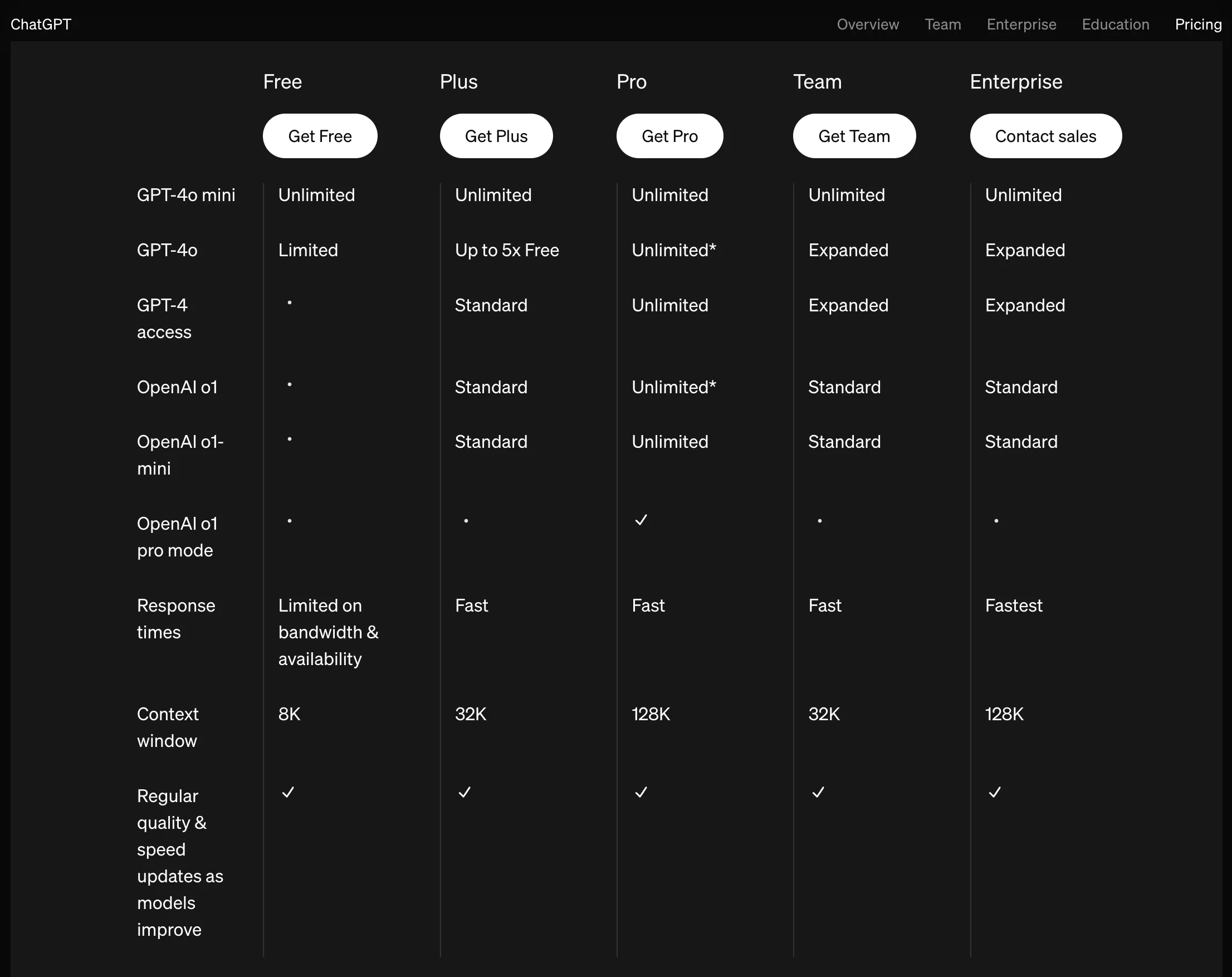
via: https://openai.com/chatgpt/pricing/
Claude上下文窗口200k,Qwen2.5-Turbo有1M的上下文窗口,Google Gemini 1.5 Pro的上下文窗口为2M。
OpenAI的产品越来越没法看了,就是要一捧一踩,如果真如去年那般牛逼,我肯定赞美。
Day8
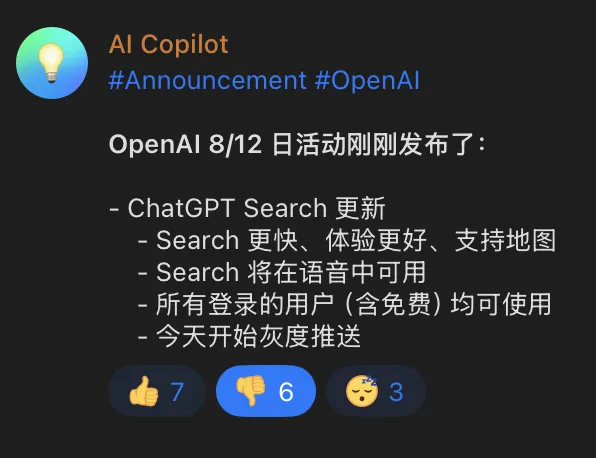
短评:使用ChatGPT Search使用时,建议优先考虑英文检索,除非你的问题在英文互联网没多少资料可供查询,这时再用中文检索。反正我是不愿意在搜索结果中看到CSDN等网站。
个人认为,目前AI搜索方面最好用的是Perplexity,检索出来的质量较好。搭配上Claude 3.5 Sonnet使用体验良好。
Day9

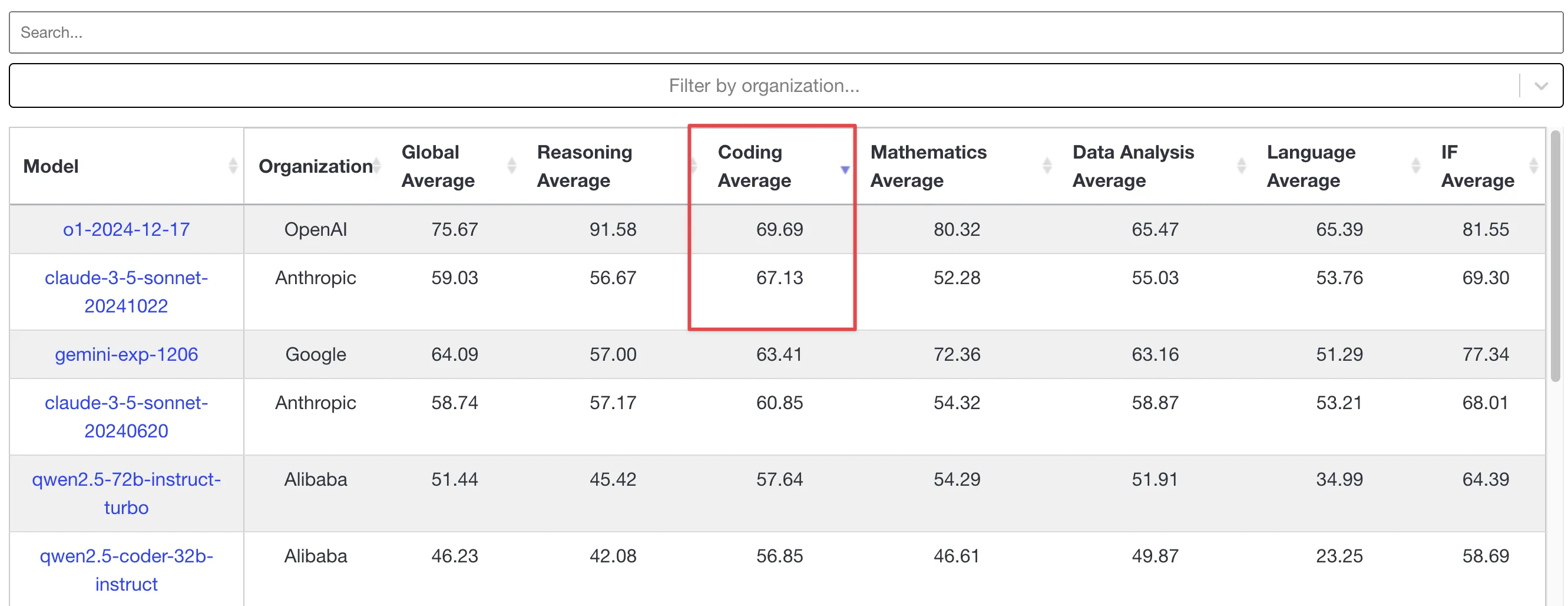
短评:o1开放api。注意该api为o1的最新版本,而ChatGPT应用中的o1还是老版本。

更有参考性的livebench排行榜中显示o1-2024-12-17的代码能力强于claude 3.5 sonnet,该api目前仅对tier5级用户开放,我无法实测,但如果依旧保持了ChatGPT应用中的o1 2023年10月知识截止日期的话,估计代码能力依旧是一坨shit。
编程框架迭代的速度很快,方法弃用是常态,使用过时的知识,“思考”再多也是白搭。
Day10
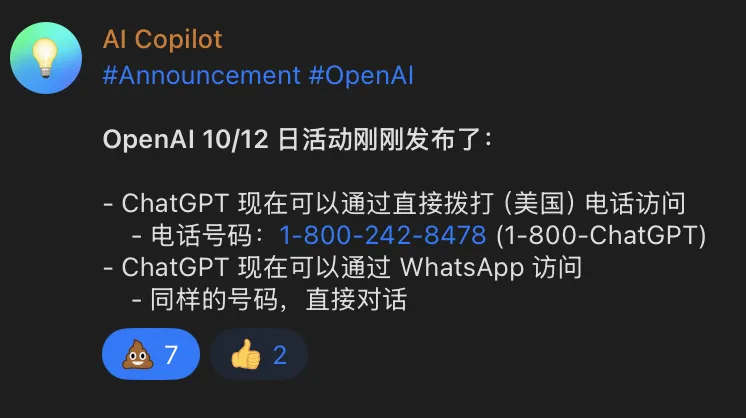
短评:花里胡哨的玩意,可以使用Google Voice或者Talkatone拨打号码体验。据说用的模型是GPT-4o-mini。
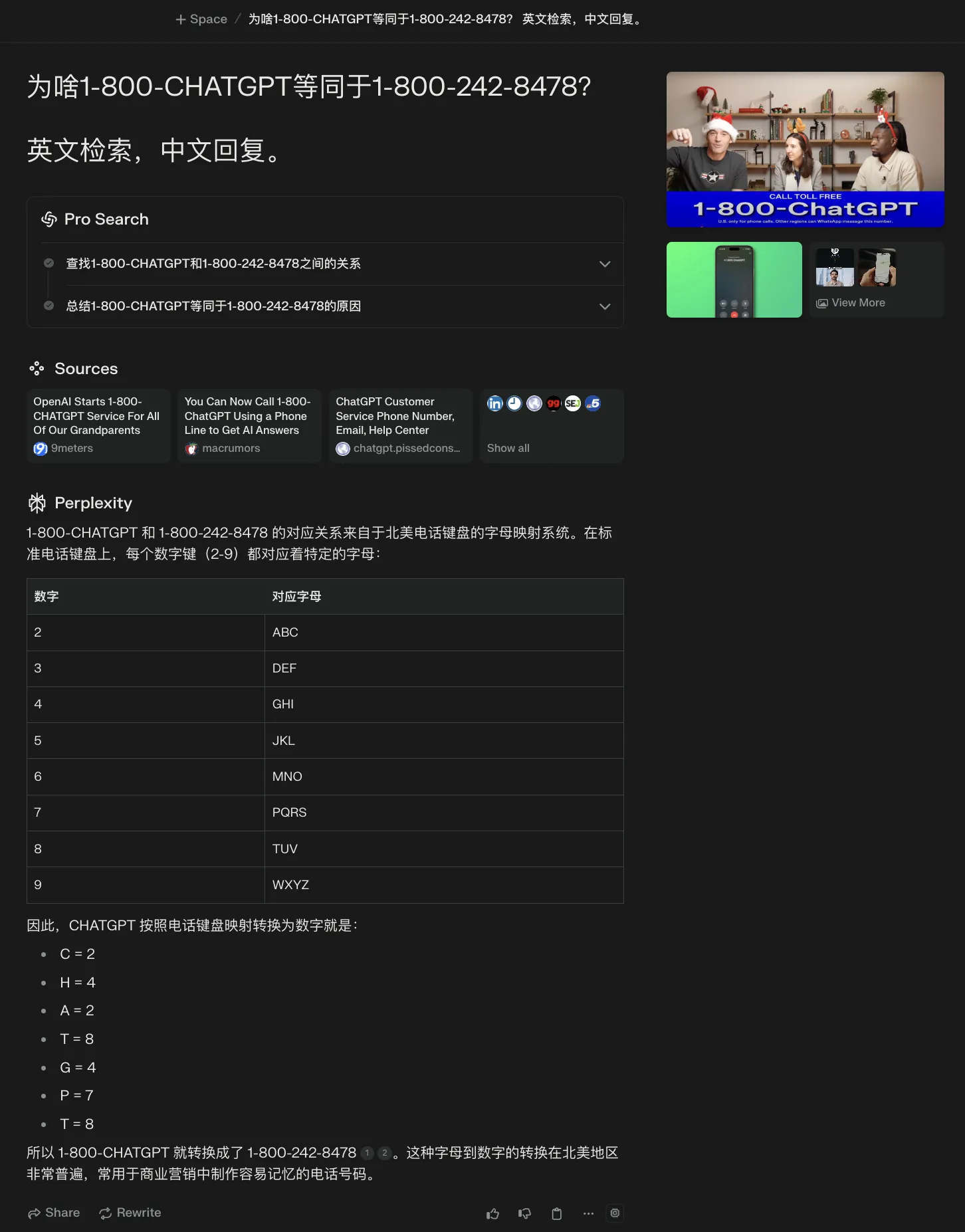
补充一个小知识。1-800-CHATGPT等同于1-800-2428478的原因:
Day11

短评:毫无新意,OpenAI发布时间线拖这么长就整这些玩意,糊弄谁呢。
Day12
短评:
一开始我满心期待,希望发布GPT4.5,结果昨晚看到一堆爆料是o3,早上一看还tm真是o3,失望透顶。OpenAI继续画饼。估计到时候可能会出更高价格的月费套餐才能用上o3。
我个人不喜欢推理模型,原因在Day1部分就已经阐明了,LLM仅仅是在预测下一个token,并不理解这个世界,所谓的“思维链”可能是个骗局,在我看来,“思维链”产生的好结果可能仅仅是提供了更多的上下文,提高了模型准确预测下一个token的概率。备注:也有可能目前我的知识水平对于CoT有误解。

simon willison大神认为o3绝不仅仅是下一个token预测。via: https://simonwillison.net/2024/Dec/20/openai-o3-breakthrough/
早上看到有人对于o3的宣布满怀期待甚至神化,认为距离AGI时刻已近,别太乐观,OpenAI的Sora刚出那会有多少人神化,结果发布了以后发现是一坨大的。希望o3真如描述讲得那么强。
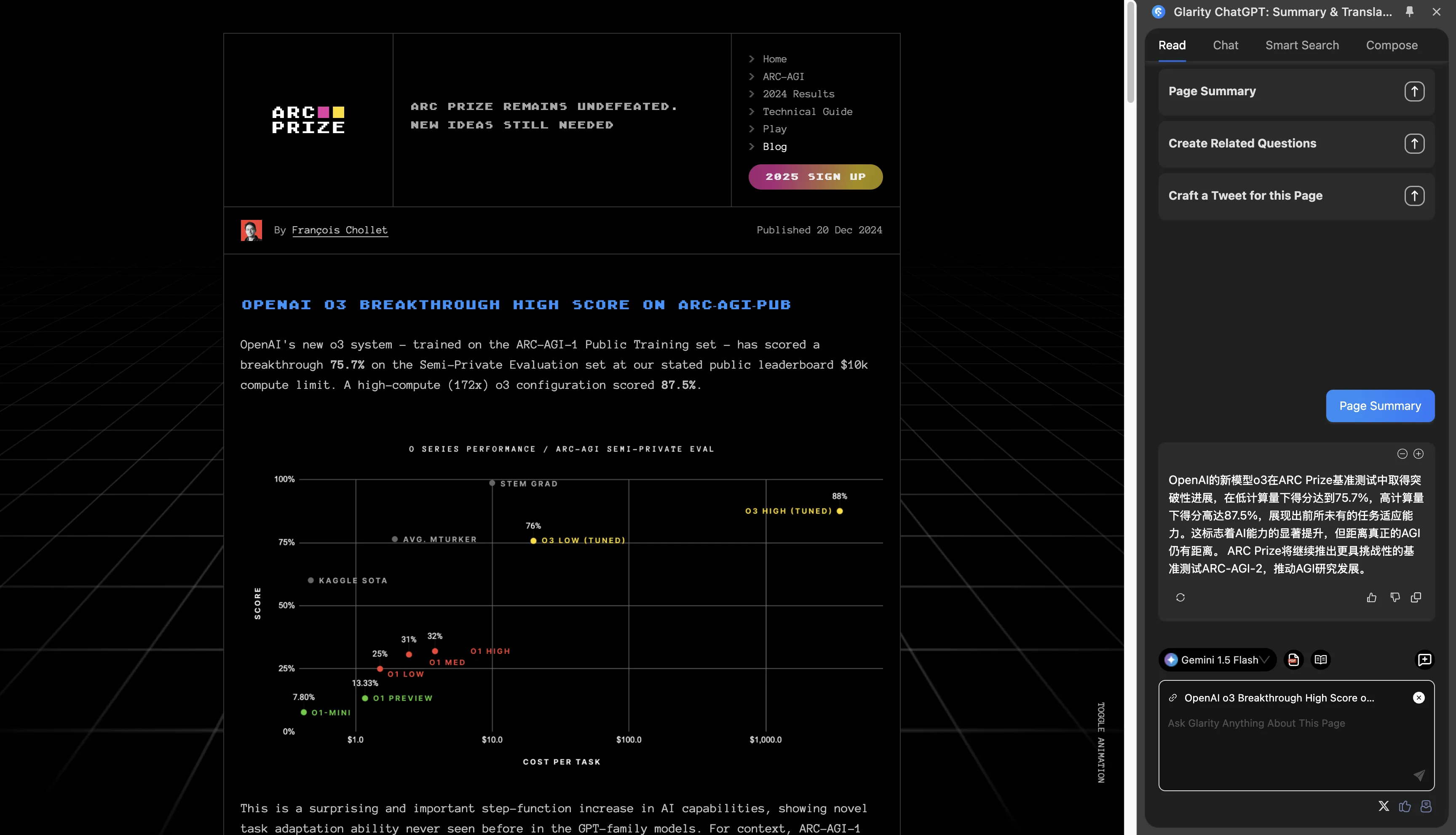
via: https://arcprize.org/blog/oai-o3-pub-breakthrough
我更希望AI公司尽早推出MVP(Minimum Viable Product,最小可行性产品),根据用户反馈慢慢改进,被吊着的感觉非常难受,要么不发,要么就直接上模型。宣布一下自己的成果遥遥领先而拖延发布,完全是在消磨用户的耐心和热情。我受够了炒作(hype)。
总评
我相信在明年的2025年,Google的Gemini和Anthropic的Claude会继续带给我惊喜,而OpenAI可能正在慢慢失去往日的辉煌。
回望今年一整年的态势,OpenAI已经在走下坡路了,o系列推理模型的推出目的是为了完成融资,毕竟4o模型拉垮,OpenAI的下一代非推理模型估计在4o的基础上提升不大,非推理模型能力遇到了瓶颈。
2023年,OpenAI的产品是绝无仅有的,市面上几乎没有任何可与之媲美的同类型LLM,而2024年,Claude3的横空出世、Claude 3.5 Sonnet代码能力的力压群雄、Gemini 2.0前瞻版多模态能力的震撼,都在慢慢地击碎OpenAI的统治地位,OpenAI的护城河正在慢慢崩塌,非推理模型LLM之王的更迭已经在悄然发生。可以说目前市面上所有的LLM排行榜都是失真的形态,真正的LLM之王是可以快速解决用户问题,而不是通过各种benchmark所归结出的名次。
附一则近些天看到的推文:
OpenAI VS Google:潮流正在转变:
文档信息
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享4.0许可证)