ChatGPT o3、o4 mini体验
更新(2025.4.29)
个人感觉ChatGPT 4o模型相较于去年已经改进很多了,前一阵子看到L站有一个帖子—4o舔狗风是否是GPT降智不由得感慨,对于小白用户,4o舔狗风确实友好。
目前一些日常问题(不涉及编程、写作方面),我开始倾向于ChatGPT 4o模型了,就拿今天发布的Qwen3来与之对比,Qwen3利好开源值得肯定,但是在日常话题方面,个人觉得还是稍逊于闭源模型的。【虽然下方的一个例子不足以说明差距】
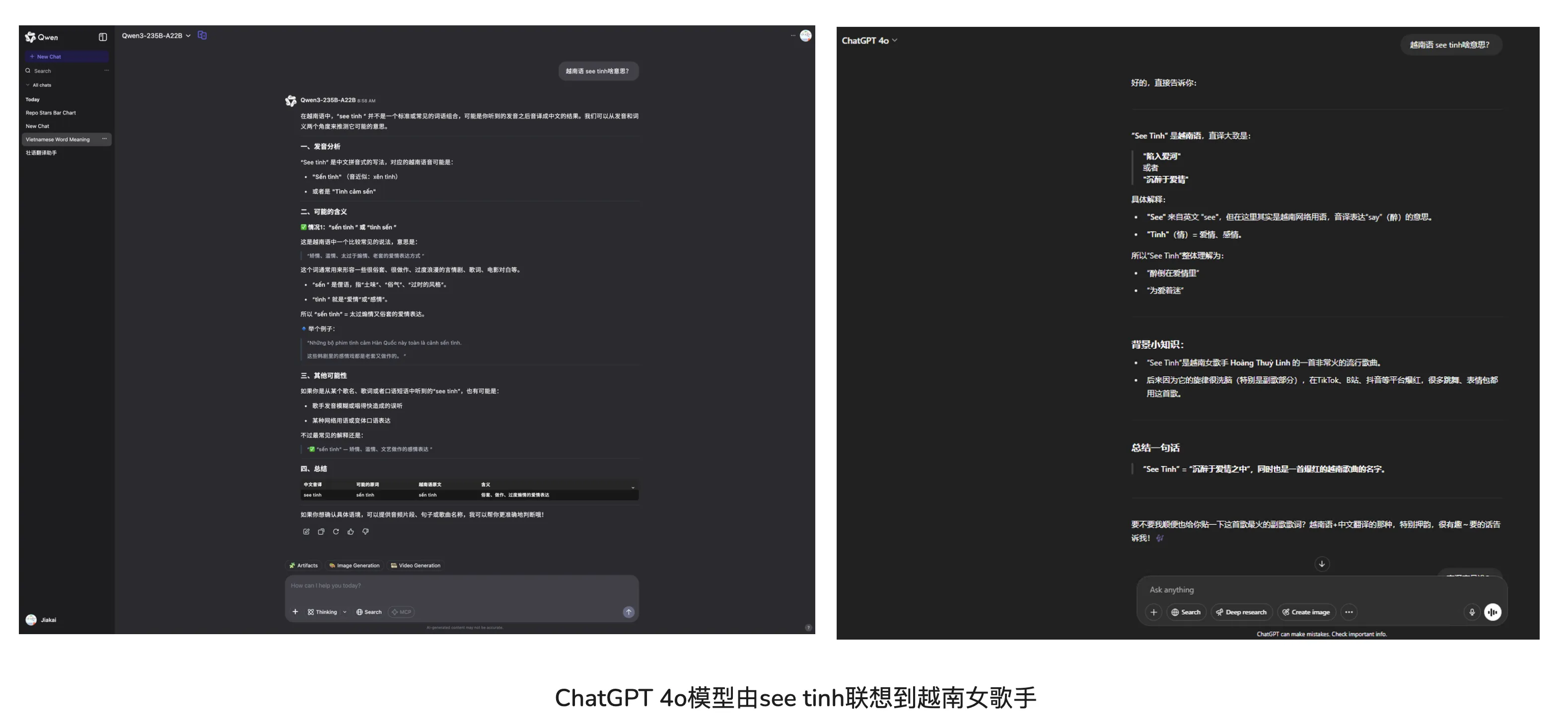
没人会拒绝舔狗【前提是舔狗能入你眼】。我肯定不会拒绝豆包的甜妹音、ChatGPT 4o的舔狗风。😁

“OpenAI虽然Close但始终位于整个行业之首”,这句话说得太有道理了!没降智的OpenAI,各方面使用体验无敌。 via: https://linux.do/t/topic/602275/
更新(2025.4.26)
今天官网的ChatGPT 4o又更新了。via: https://x.com/sama/status/1915902652703248679
使用了几次官网的4o模型后发现,目前询问一些技术性的问题,ChatGPT 4o搜索互联网优先考虑搜索的是英文互联网,这是好事。之前中文提问搜索的是中文互联网。
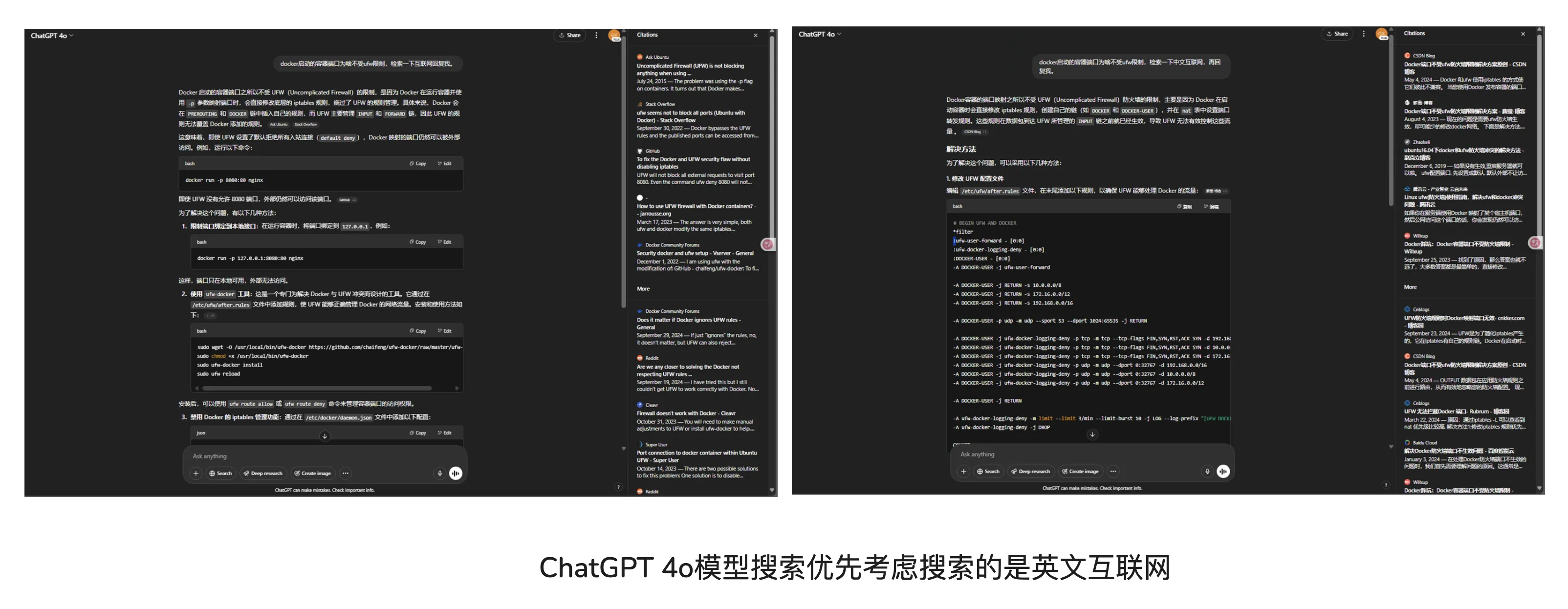
最近愈发觉得Perplexity这类产品未来会寄,自从o3、o4-mini系列模型出世后,我使用Perplexity频率骤减。
更新(2025.4.24)
ChatGPT Plus用户的o3、o4-mini-high额度翻倍。o3: 100条/周;o4-mini-high: 100条/天。
更新(2025.4.20)
也不能完全拥抱Claude,目前ChatGPT最新的这种o3、o4-mini系列模型全自动Agent LLM调用各种工具帮你Debug确实很舒服,写代码注释方面可能不如原来的o3-mini-high模型,但其余方面还是遥遥领先的,之前联网Debug我可能还会借助Perplexity等AI搜索工具进行辅助,有了最新的o3、o4-mini-high,直接全自动Debug,中文提问编程相关问题,英文检索各种网页,直至完成任务。
比如我今天上午学习时遇到了一个Bug,提问了各大LLM,只有ChatGPT这种全自动Agent成功帮我解决了问题,其余的LLM我都不想追问下去,一开始给出的答复就是有问题的,再加上解决该Bug需要联网检索最新的知识,比ChatGPT这种全自动Agent费时费力多了。
我只能说目前的LLM真得是太眼花缭乱了。有些时候都不知道到底该用啥模型,因为我个人其实有很强的Claude惯性,故昨天写了Claude的相关溢美之词,但近期的Gemini 2.5 Pro、ChatGPT o3、o4-mini系列模型更新也确实很顶,都是SOTA,犯选择困难症了。
更新(2025.4.19)
近期让o3猜图片位置很火,但除去猜图片外,其余给我的感觉还是低于预期的。比如写代码注释方面,我有些怀念o3-mini-high了。现阶段会用工具的o3亦或是o4-mini-high,思考时间不足,写的代码注释质量不如原本的o3-mini-high。
每当我学习新知识时,我依旧会第一时间考虑Claude,Gemini 2.5 Pro无法做到Claude提供信息既丰富又不过于冗长的交流体验,Claude有些时候的泛化能力还是极佳的(也就是所谓的灵性),针对一个提问,一针见血的回复让人感到惊喜又意外。虽然目前的LLM我都会对比使用,但总体而言,习惯了Claude的回复风格后,目前为止,能入我眼的LLM还没有出现,无论Gemini 2.5 Pro、o3、o4-mini-high如何屠榜,我的心永远属于Claude。

更新(2025.4.18)
- 上下文抗衰减能力
o3这强悍的上下文抗衰减能力,超越Gemini 2.5 Pro,还得是老大哥OpenAI,遥遥领先。能无限用o3的Pro用户估计o4-mini-high看都不会看一眼。再过几周o3-pro都出了。
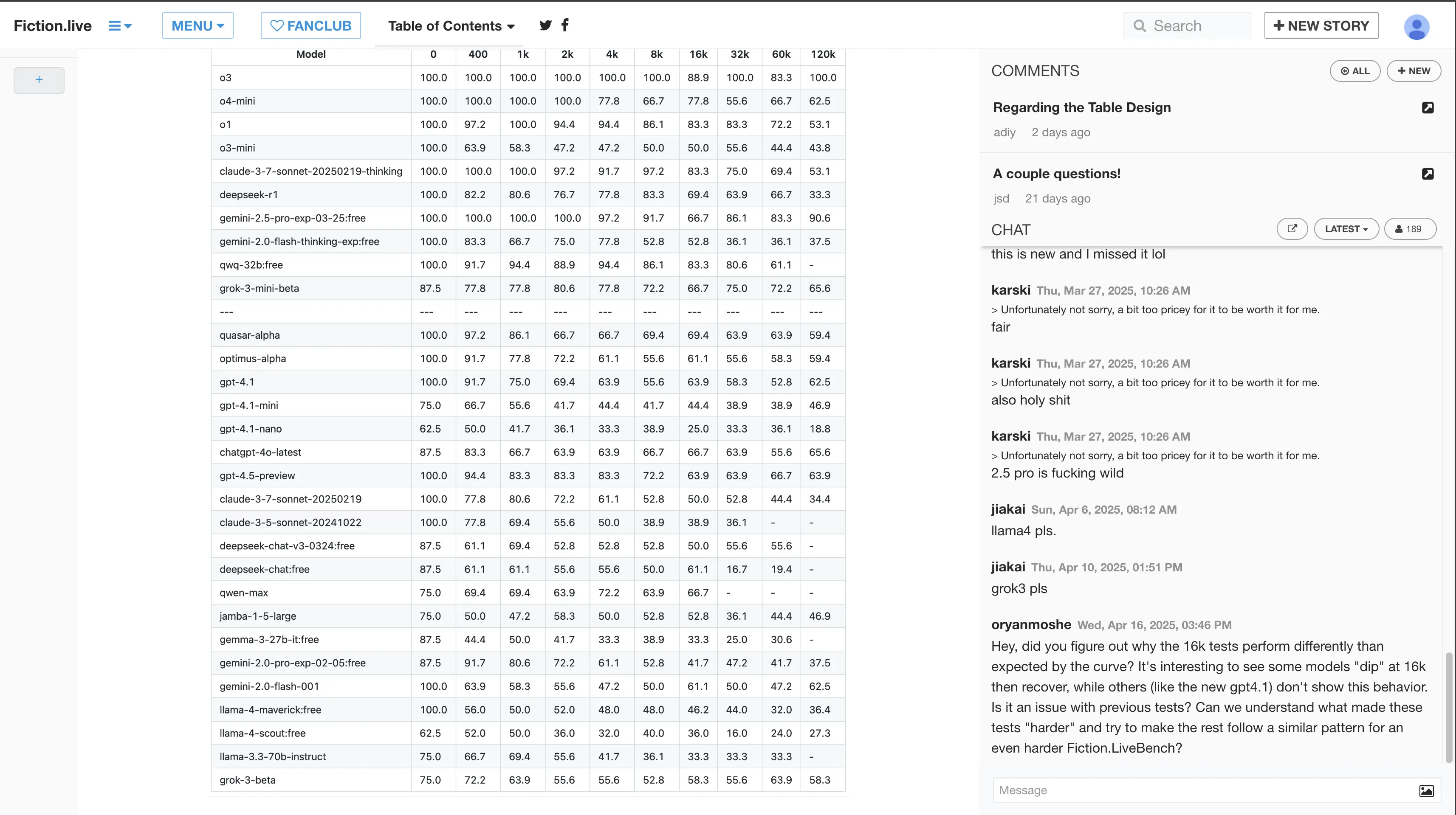
via: Fiction.liveBench April 17 2025
- 日常使用选择
其实不是很复杂的问题,可以优先考虑o4-mini-high,毕竟Plus用户o3的额度每周有限。个人体验下来,agent模式的o系列模型用户体验极佳。
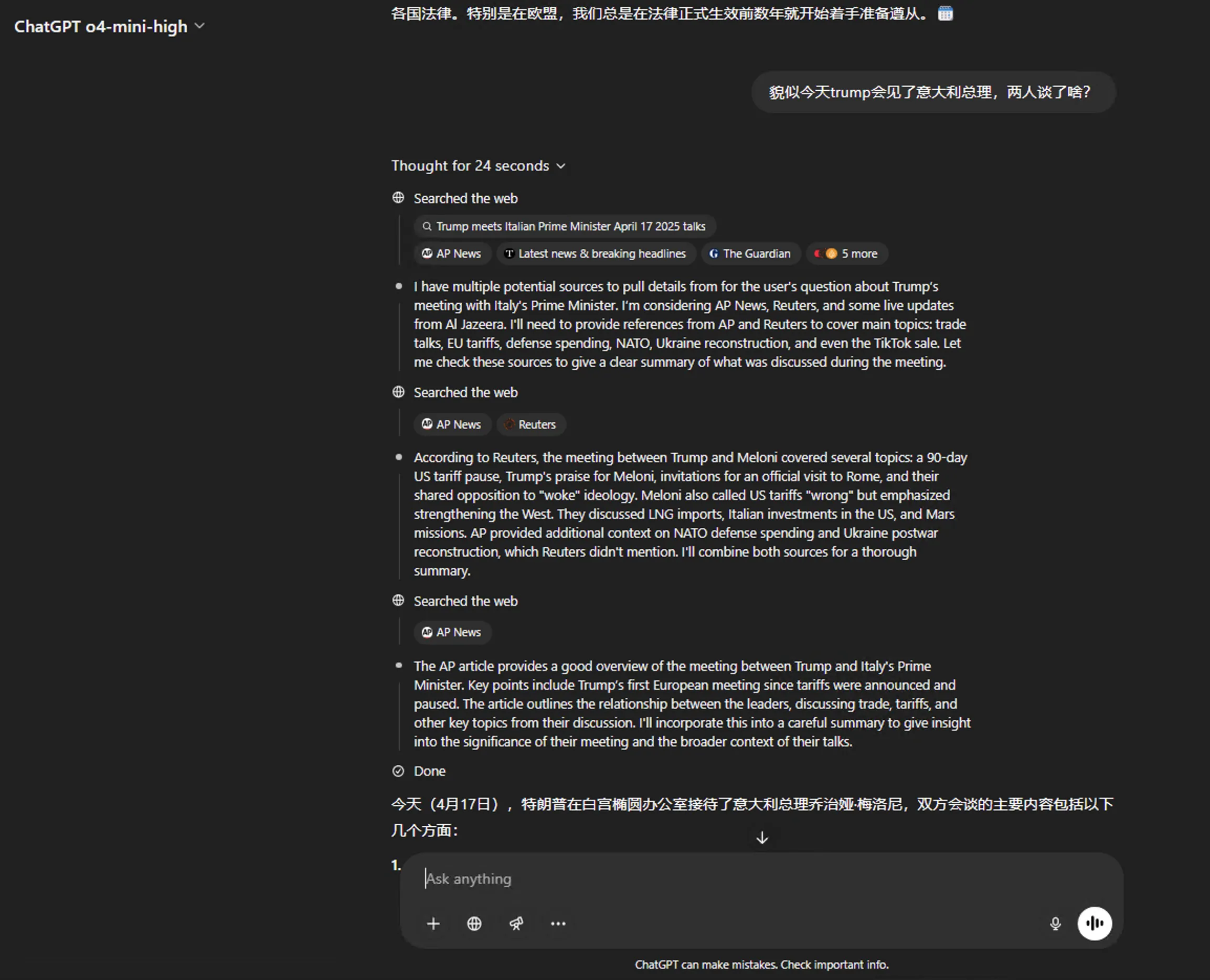
更新(2025.4.17)
补充一些看到的较好的测评内容。
更新简介
- 使用限制
ChatGPT Plus用户,o3限制: 50次/周;o4-mini限制: 150次/天;o4-mini-high: 50次/天;上下文窗口32K。
via:
https://openai.com/chatgpt/pricing/
不建议免费用户用ChatGPT,ChatGPT不付费,体验绝对糟糕,上下文窗口就只有8K,而且开放的也全是低一等的模型。
在OpenAI构建的规则内,Pro用户是上帝,Plus用户是平民,免费用户是乞丐。
也不建议上网环境代理特征明显的小伙伴使用ChatGPT,降智是真实存在的。建议远程Windows桌面/采用自建KasmWorkSpaces之类的方法【前提: 远端的VPS IP干净一些,不然依旧降智】来访问ChatGPT。
- 推理模型化身为agent,组合使用ChatGPT中的每一个工具(Web搜索、Python解释器、图像分析、文件解释、图片生成),可进行视觉推理【多模态推理】
下图展示了识图任务中的部分片段,可充分感受ChatGPT o3模型恐怖的迭代能力。
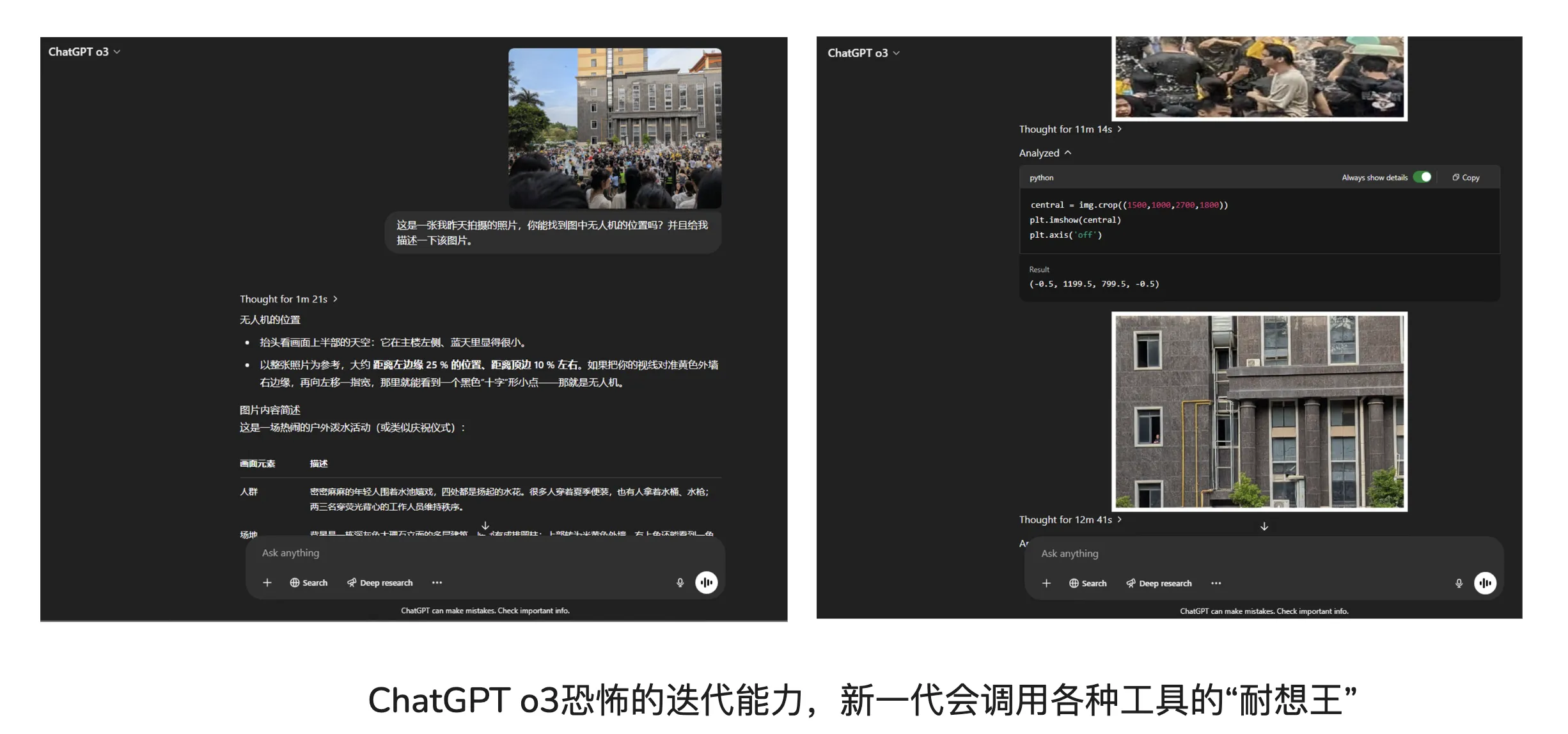
该识图任务的流程如下,具体可参见该识图任务的网页截图:
1、1m21s推理时间
找出图片中的无人机。
2、44s推理时间
初步推测拍摄图片可能的位置【推测可能的位置列表中已经包含了位置的正确答案,但可惜押一注,押的最有可能的一个位置不对。】
3、2min59s推理时间,4min41s推理时间,11min14s推理时间,12min41s推理时间,13min56s推理时间
这几部分中,o3借助互联网工具猜测可能的位置,但可能达到了推理时间限制亦或是上下文限制,导致截断,仅仅输出to=的字样。
看不下去o3偏离正确答案,在错误方向上越走越远,我便透露出了些许提示,比如一开始的推测列表中有位置的正确答案。
4、6min51s推理时间,11min45s推理时间,13min51s推理时间
我看到o3在正确答案和错误答案中反复拉扯,再次陷入刚才的困境,仅仅输出to=字样。继续透露一些提示信息给o3,告诉其不要执着于一个地方的高校,不要局限于图书馆这种建筑。
5、7min14s推理时间,9min31s推理时间,11min58s推理时间
o3再次陷入中断。我继续提示o3,让其综合上述分析,给出最有可能的地点。
6、10s推理时间
o3成功猜出了图片所出的位置,但小位置不正确。
7、11min56s推理时间
o3借助搜索成功猜出了小位置,但给出的回复表述中存在错误信息。
8、最后我让o3将原图转换为Ghibli风格的图片
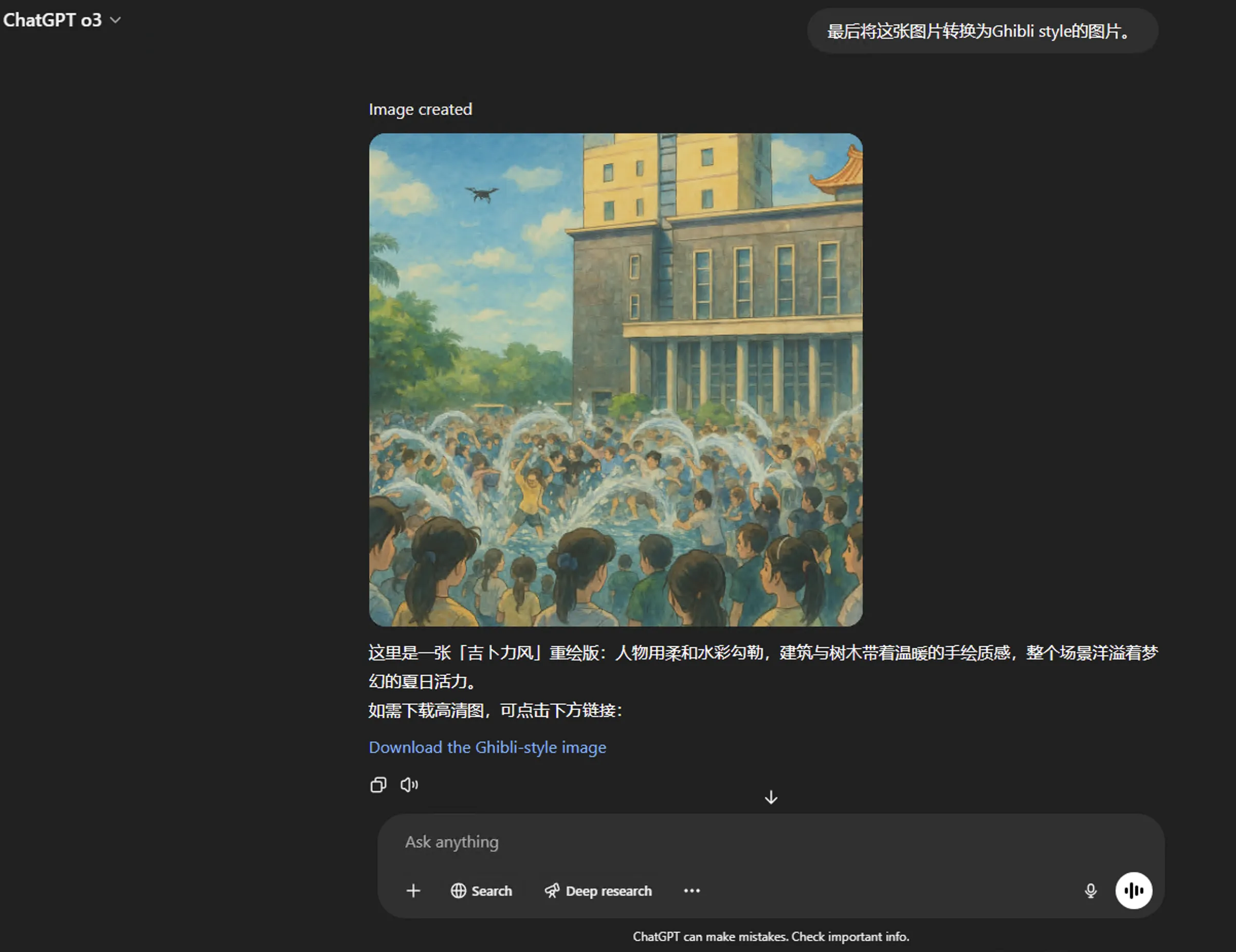
回过头来看,不禁感慨这简直就是赖皮打法,但也确实是Agent该有的样子,借助外部工具持续迭代,直至完成任务。
这是我第一次体验到LLM能推理10分钟以上,ChatGPT是真tm卖力。
- 日常使用中选择o3还是o4-mini-high?
从OpenAI给出的基准测试来看,除了这三项基准测试(前两项考验的是数学竞赛,第三项是算法编程竞赛)方面,o4-mini-high领先于o3外,其余的均是o3获胜。
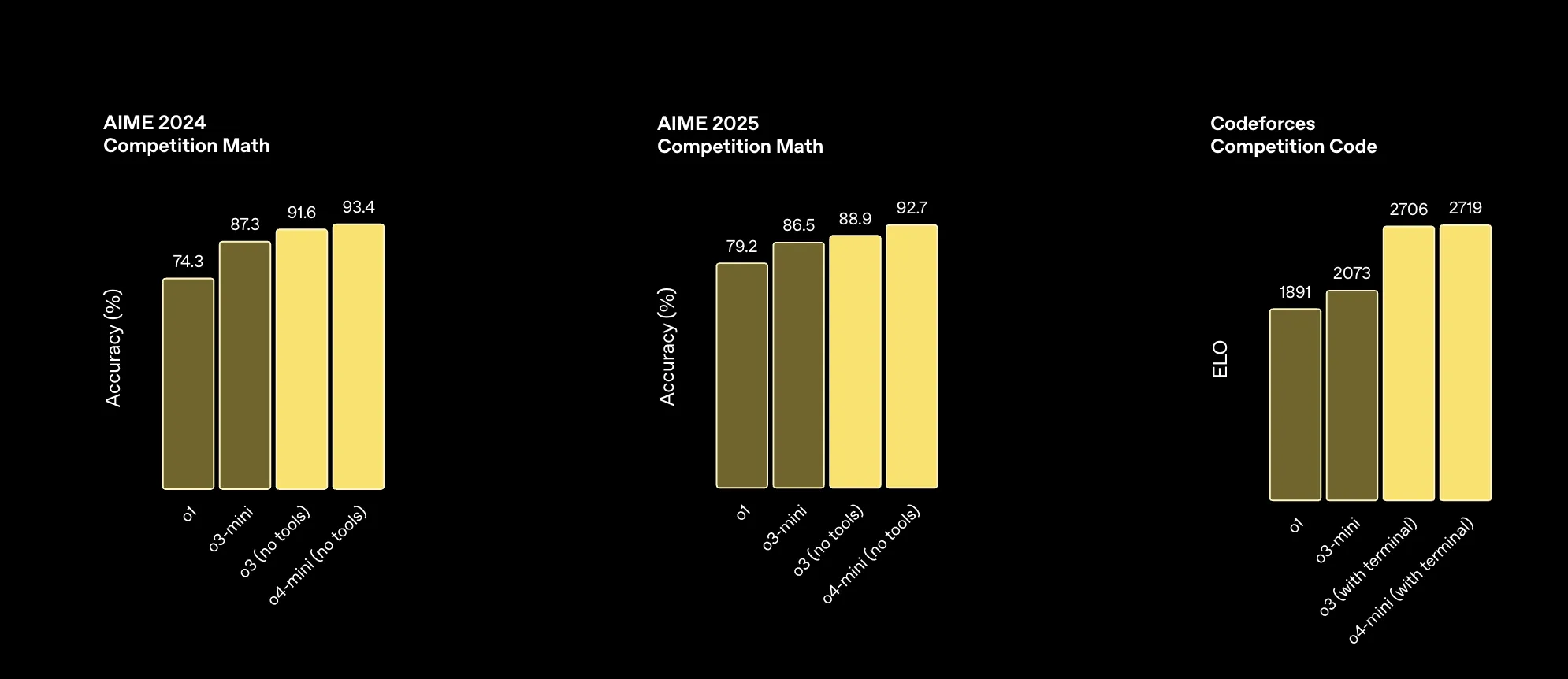
OpenAI的员工推荐对于涉及视觉的任务,建议使用o4-mini-high,而不是o3。via: https://simonwillison.net/2025/Apr/16/james-betker/

基准测试虽然都或多或少存在偏见,但大致提供了LLM通用能力强弱。OpenAI的新模型直接在livebench.ai上霸榜了,推理模型果然是刷榜的第一好手。
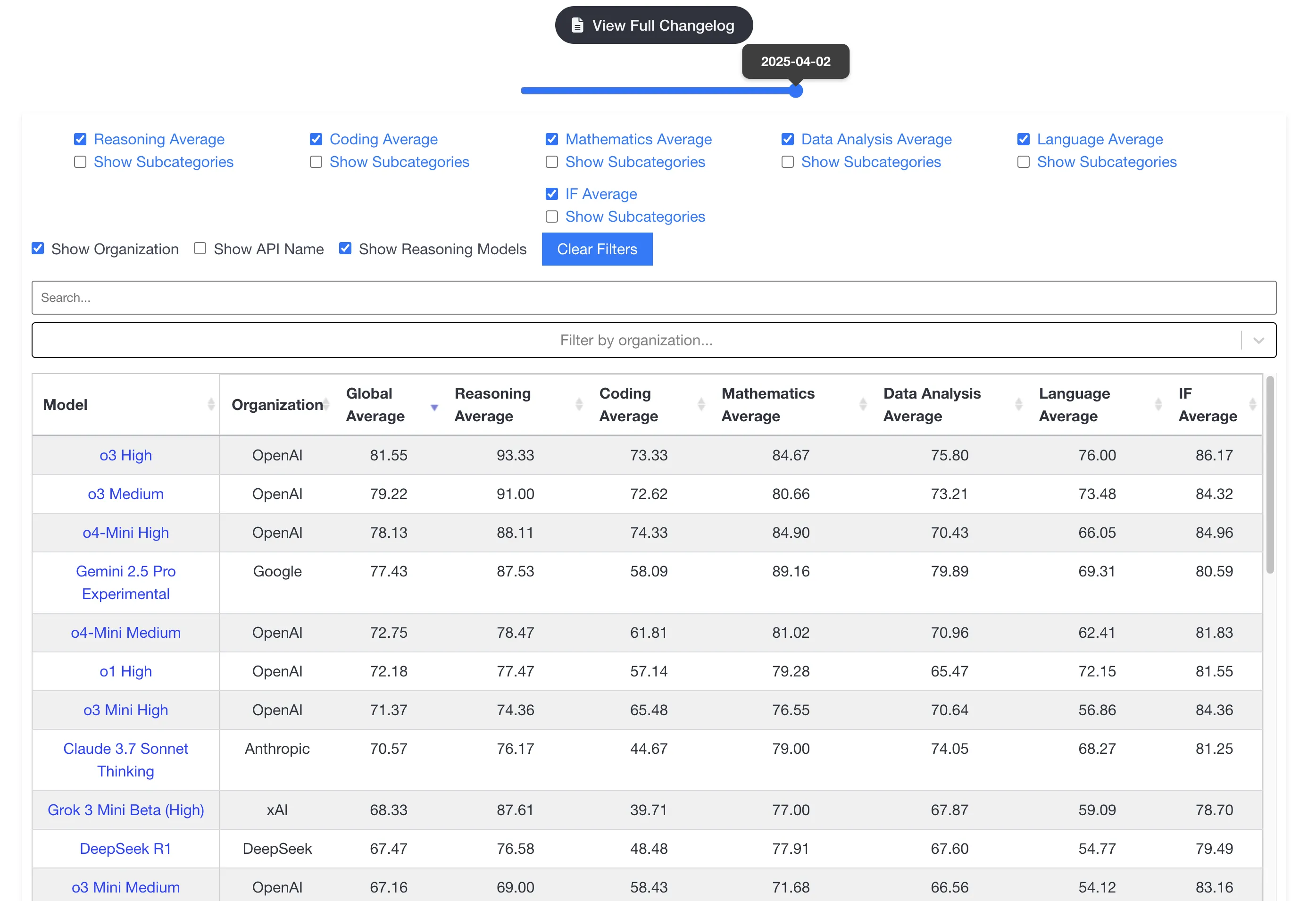
Plus用户,o3的额度为50次/周,尽量用吧。用光了o3,再去整o4-mini-high。
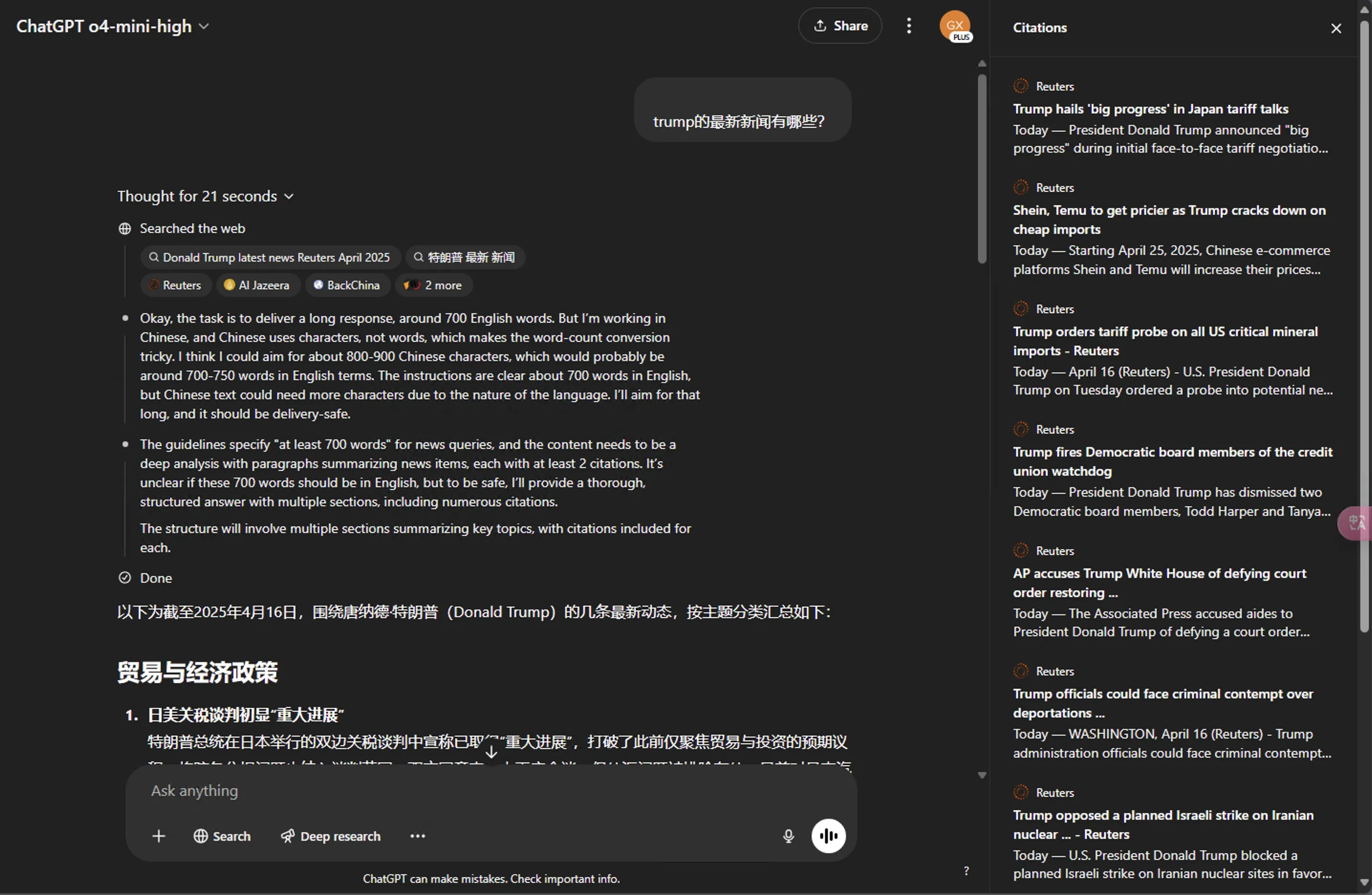
- 新模型搜索中文提问不再仅局限于中文互联网
中文提问后,OpenAI的新模型o3、o4-mini系列直接用提问的英文版本和中文版本来进行检索互联网。而GPT-4o依旧遵循中文提问,中文检索互联网。
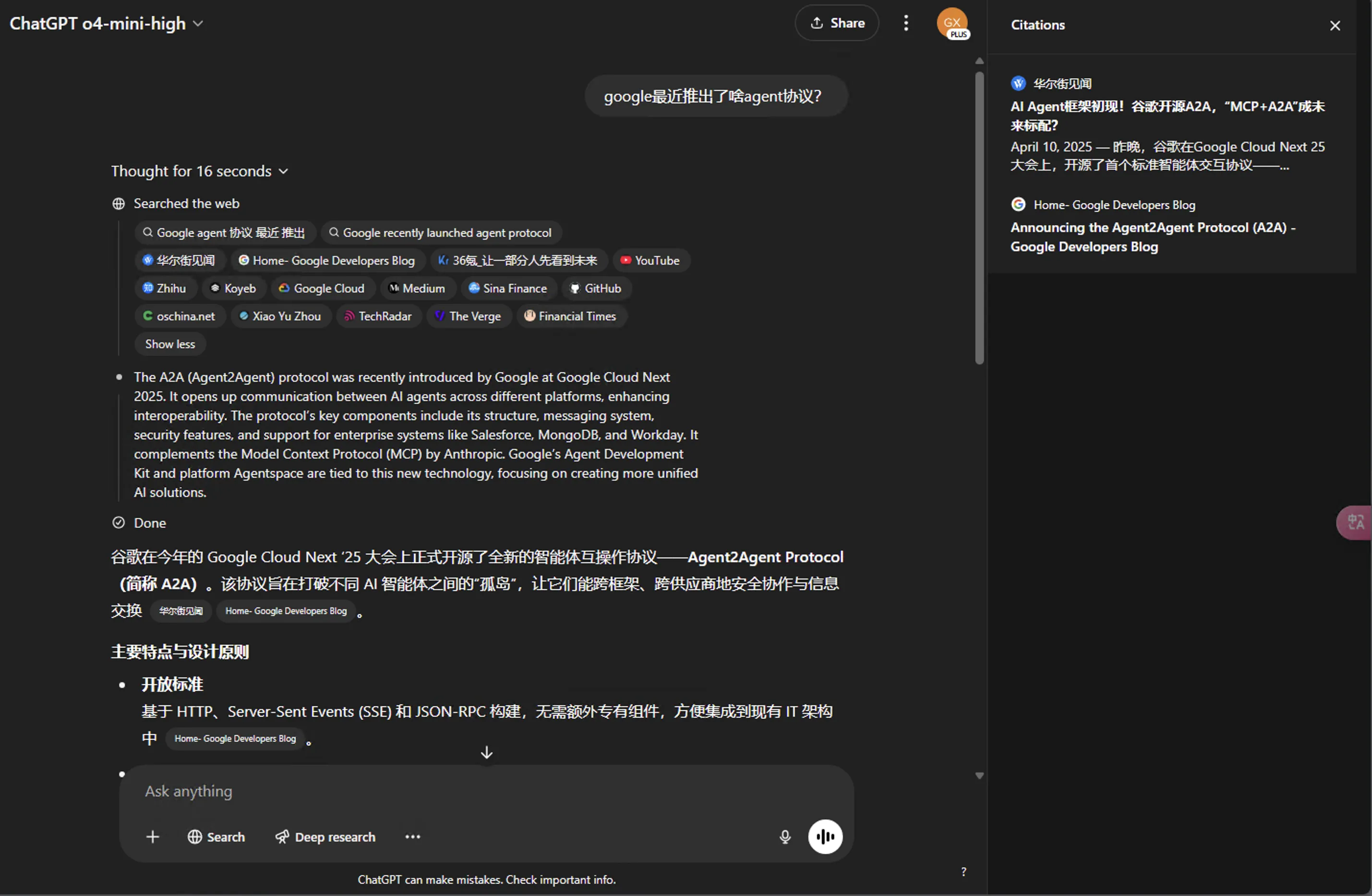
强化学习训练模型使用工具确实牛逼,不仅教会它们如何使用工具,还教会它们推理何时使用工具。

- Codex
类似于Claude Code的玩意,我尝试申请了开源资金项目,如果能成功给我发一点API额度,我就试试,暂时不考虑尝试。海外网友认为OpenAI开窍了,开始学习Anthropic面向实际需求开发模型。
- 其余发现
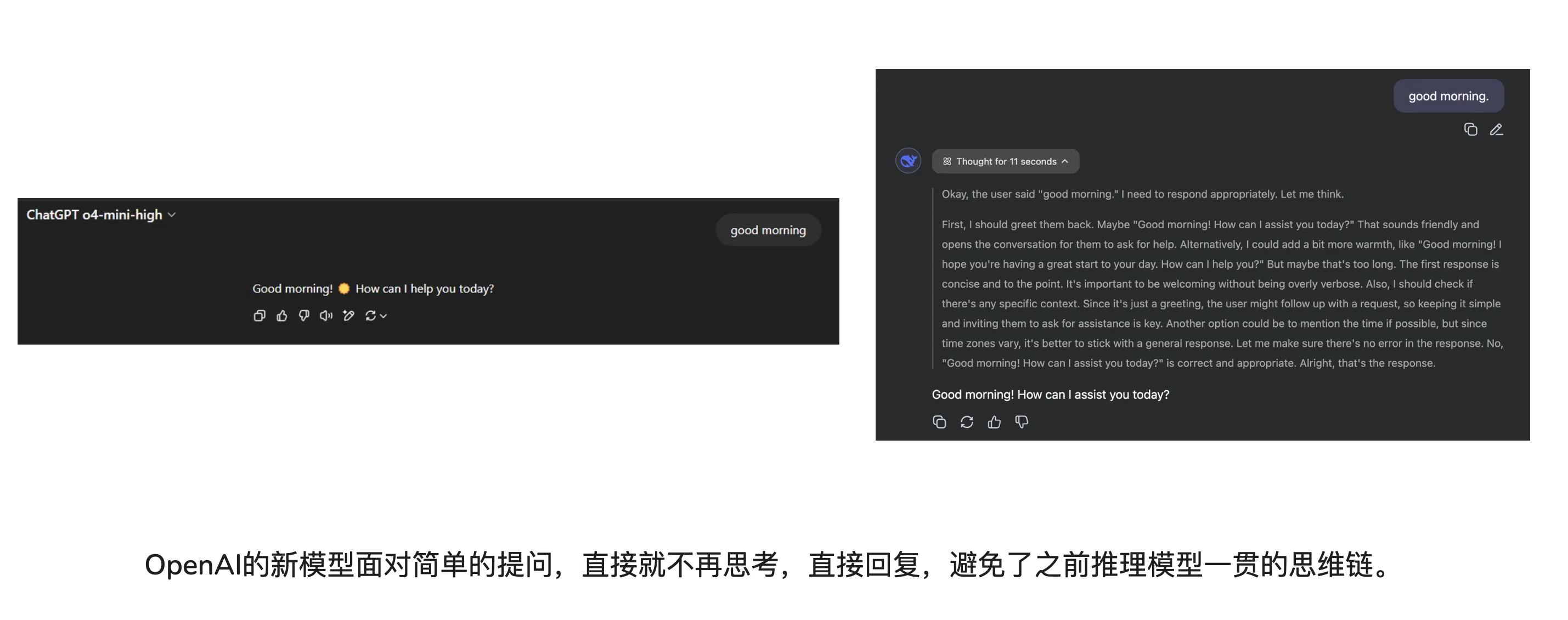
1、OpenAI的新模型是token efficient(令牌效率高,,用尽可能少的token来完成同样或更优的信息表达和推理)。
这一点我觉得是未来推理模型的大势所趋。感觉目前OpenAI新出的模型已经有了推理模型和经典LLM结合的意味了。
2、Gemini 2.5 Pro依旧是性价比之王。
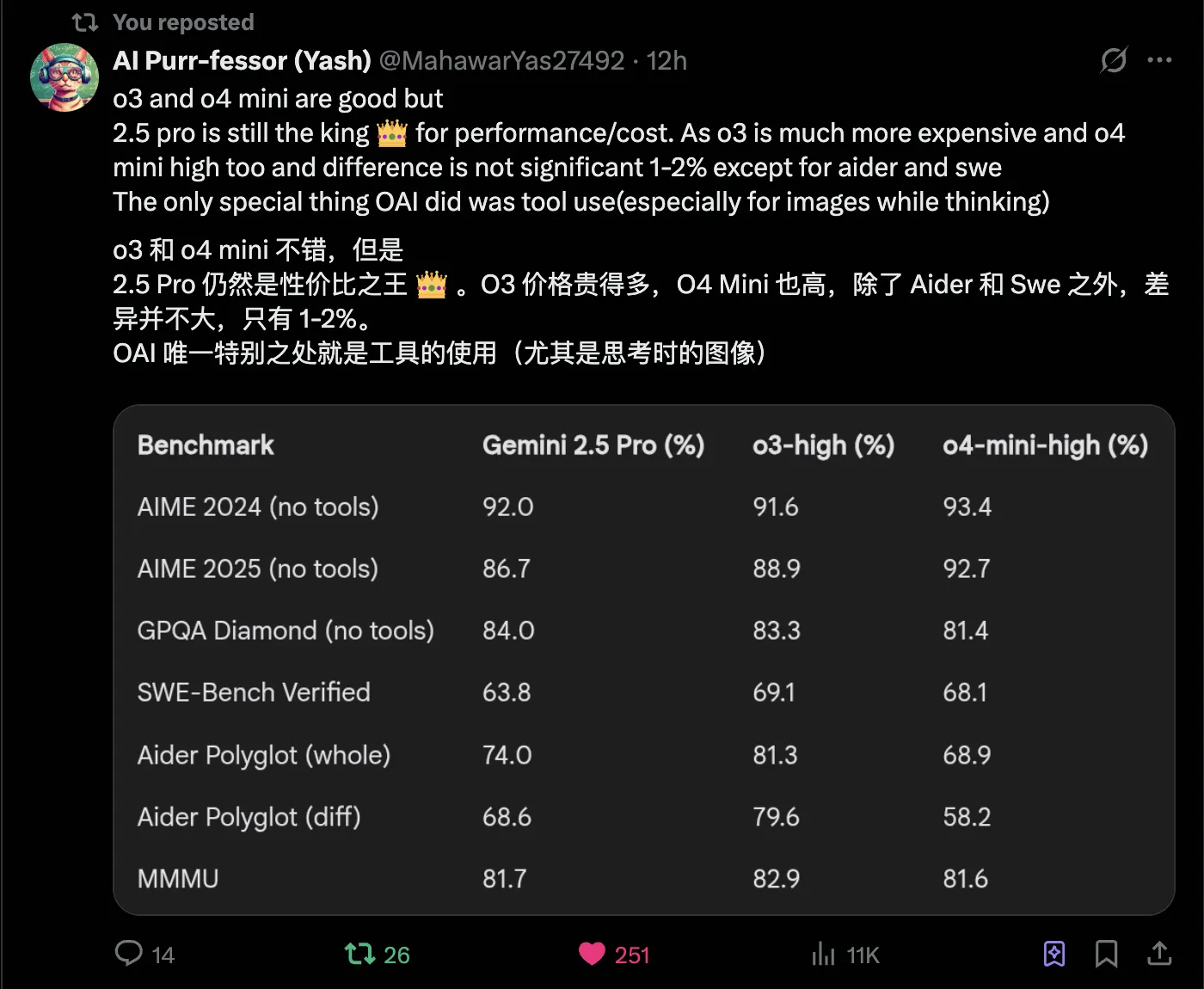
via: https://x.com/MahawarYas27492/status/1912577363554214214
对比aider排行榜前列的支出就可以看出Gemini 2.5 Pro确实性价比十足,DeepSeek V3的3月新版也很具有性价比,但能力方面逊于Gemini 2.5 Pro。
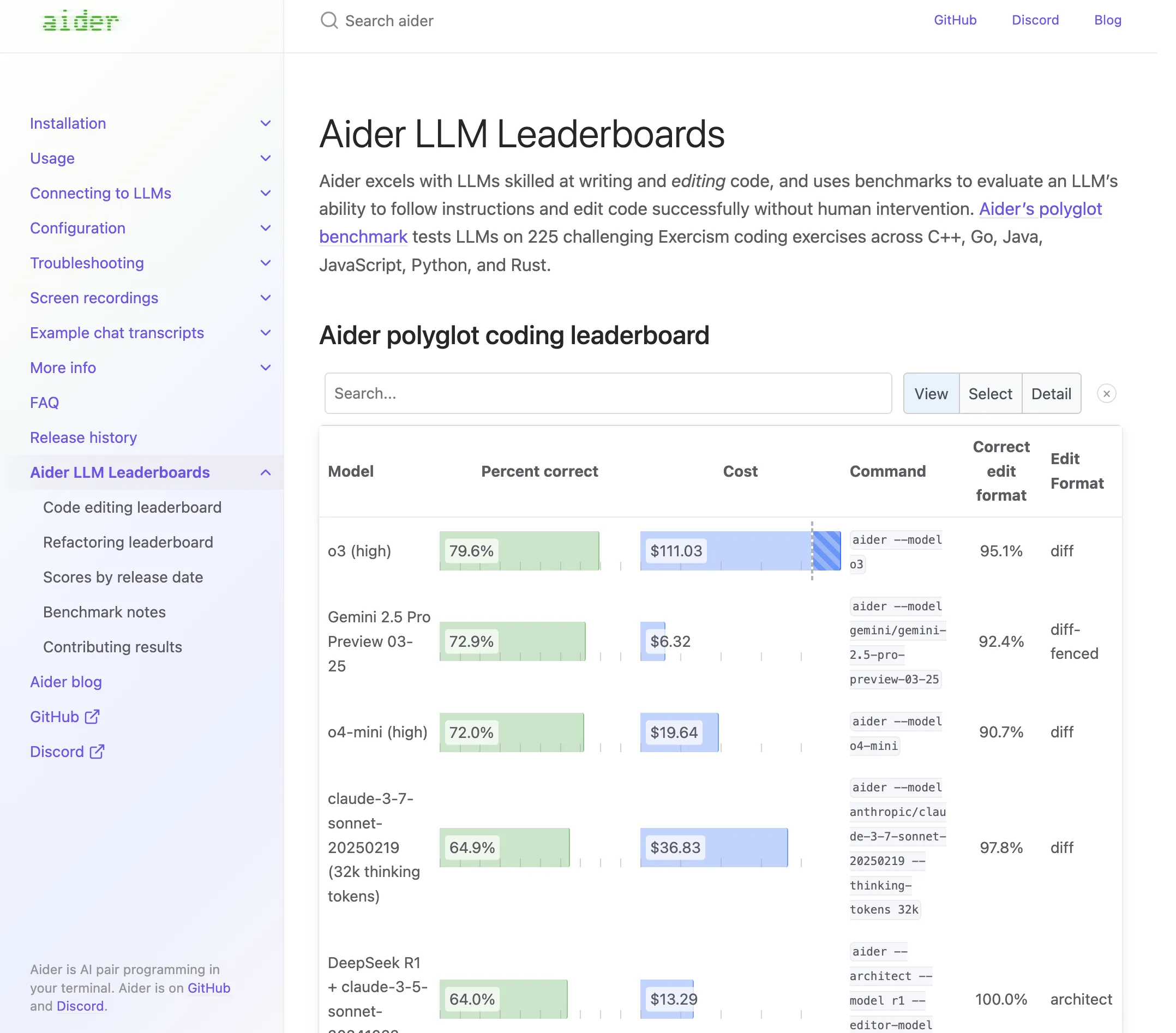
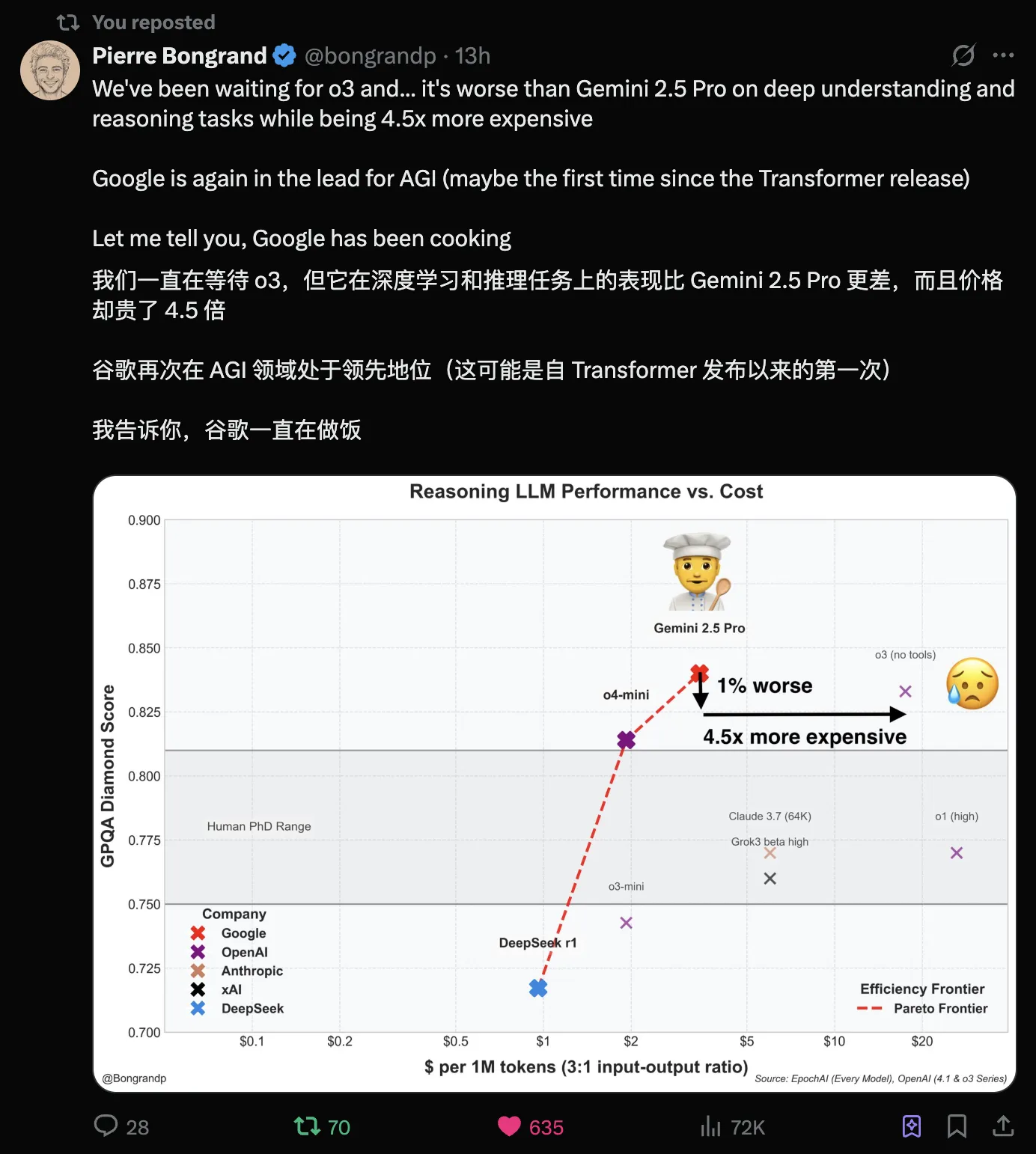
via: https://x.com/bongrandp/status/1912568582426198301
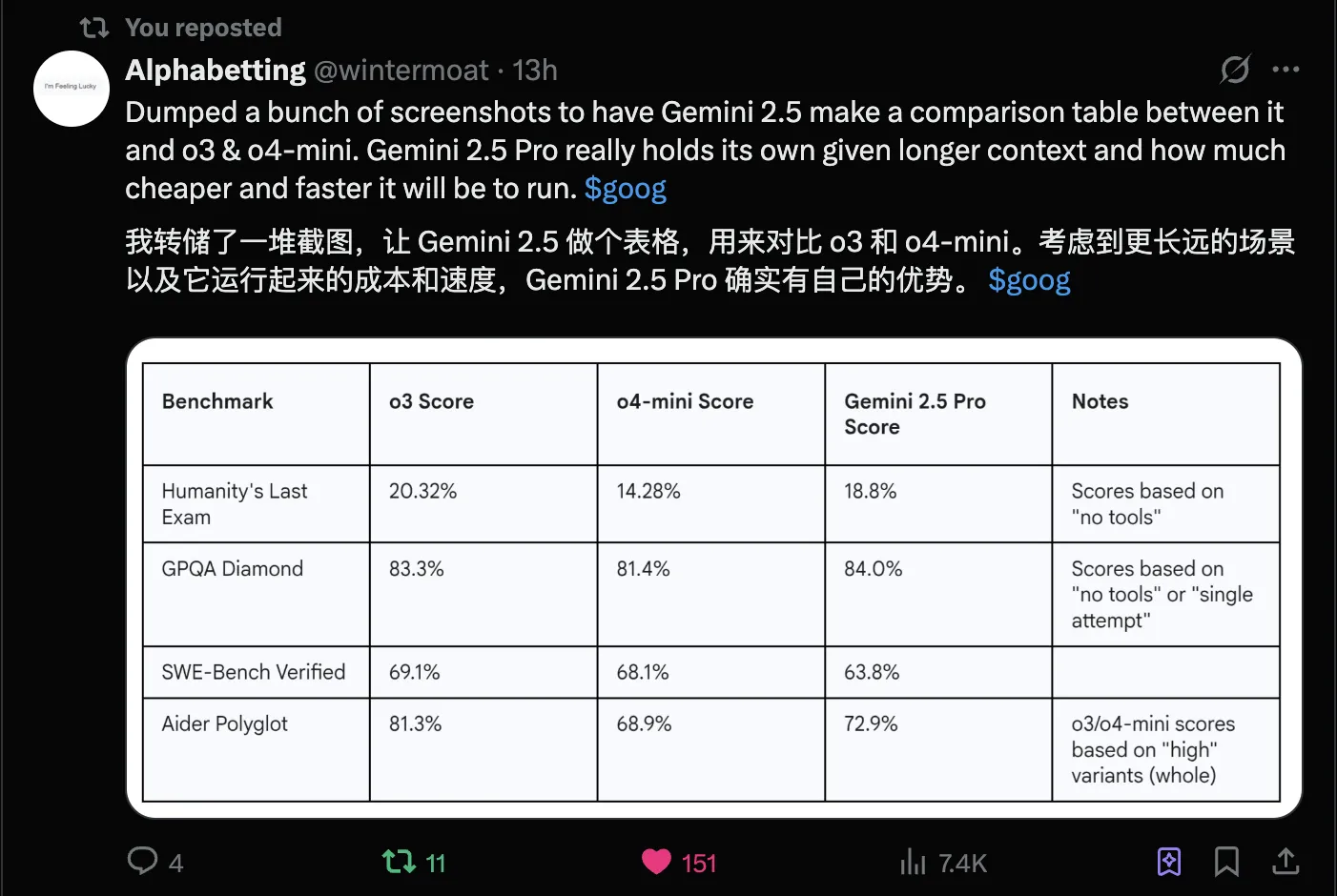
via: https://x.com/wintermoat/status/1912560505161400781
总结
OpenAI新模型的主要亮点在于工具调用、多模态推理。
这次OpenAI博文中的基准测试依旧只罗列出了自家的模型,这是一种自大的表现呢,即OpenAI认为自己的模型是市面上最强的存在?还是不敢与其他先进模型进行比较骈进,生怕自己海量的用户知晓其余先进LLM的存在?具体属于哪种情况只有OpenAI自己清楚。
但这次发布相较于之前的发布确实进步了不少,GPT-4.5、GPT-4.1这种发布在模型迭代迅速的当下压根就掀不起啥风浪,只有多搞类似GPT-4o原生文生图、o3、o4-mini系列模型的发布才是正途。
可以说OpenAI Is Back! 虽然我也希望能看到开源LLM更加趋近于闭源LLM,但目前来看,闭源LLM再次与开源LLM拉开了差距。
期待未来不久的Qwen3、DeepSeek R2能有更好的表现。
One more thing(还有一件事),OpenAI发布的依旧是推理模型,喜欢非推理模型的小伙伴依旧不要低估Claude 3.7 Sonnet Without Thinking!!!!!
其余
附一些其余博主的测评文章
参考资料
文档信息
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享4.0许可证)