当大模型开始画答案
1. 引言
最近发现很多AI服务都开始支持画答案,所谓画答案是指AI的回复不再是纯文字,而是支持以图文并茂的形式输出。
在我印象中,可视化真正的鼻祖可以算是ChatGPT,在GPT-4o的年代,ChatGPT针对用户提问的回复,有时会嵌入网络图片。这使得其在一众服务中脱颖而出,毕竟当时其余AI服务的回复都是纯文字。
之后发现Grok 4也会在回复中嵌入网络图片,这种可视化形式的回复,在面对日常提问时体验良好。
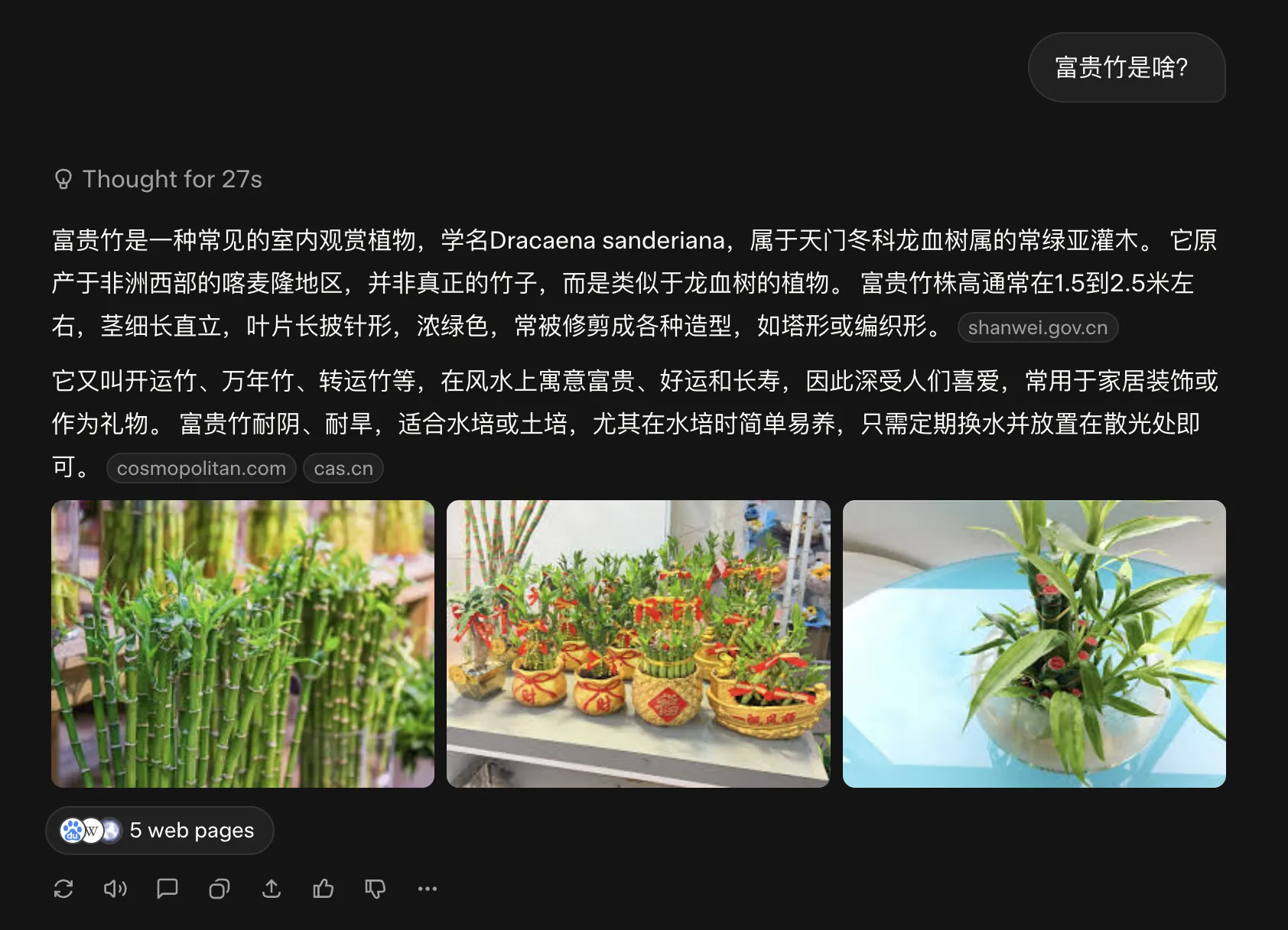
国内的元宝在讲解微信公众号文章时,会内嵌文章图片来进行讲解。
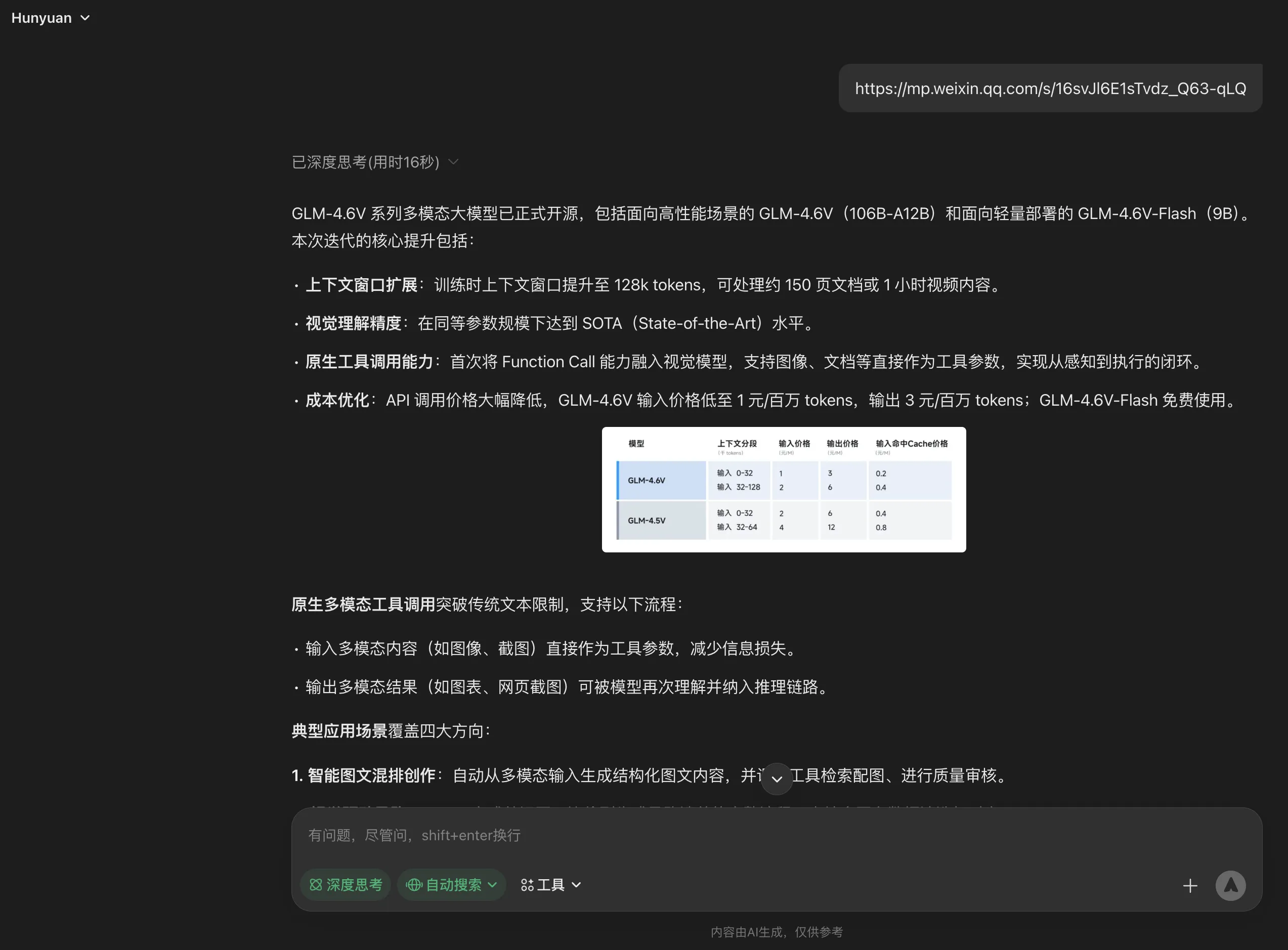
近期Google AI Mode支持中文提问,其也支持内嵌网络图片。在Gemini 3 Pro的加持下,有时甚至生成一个小程序来进一步辅助理解。
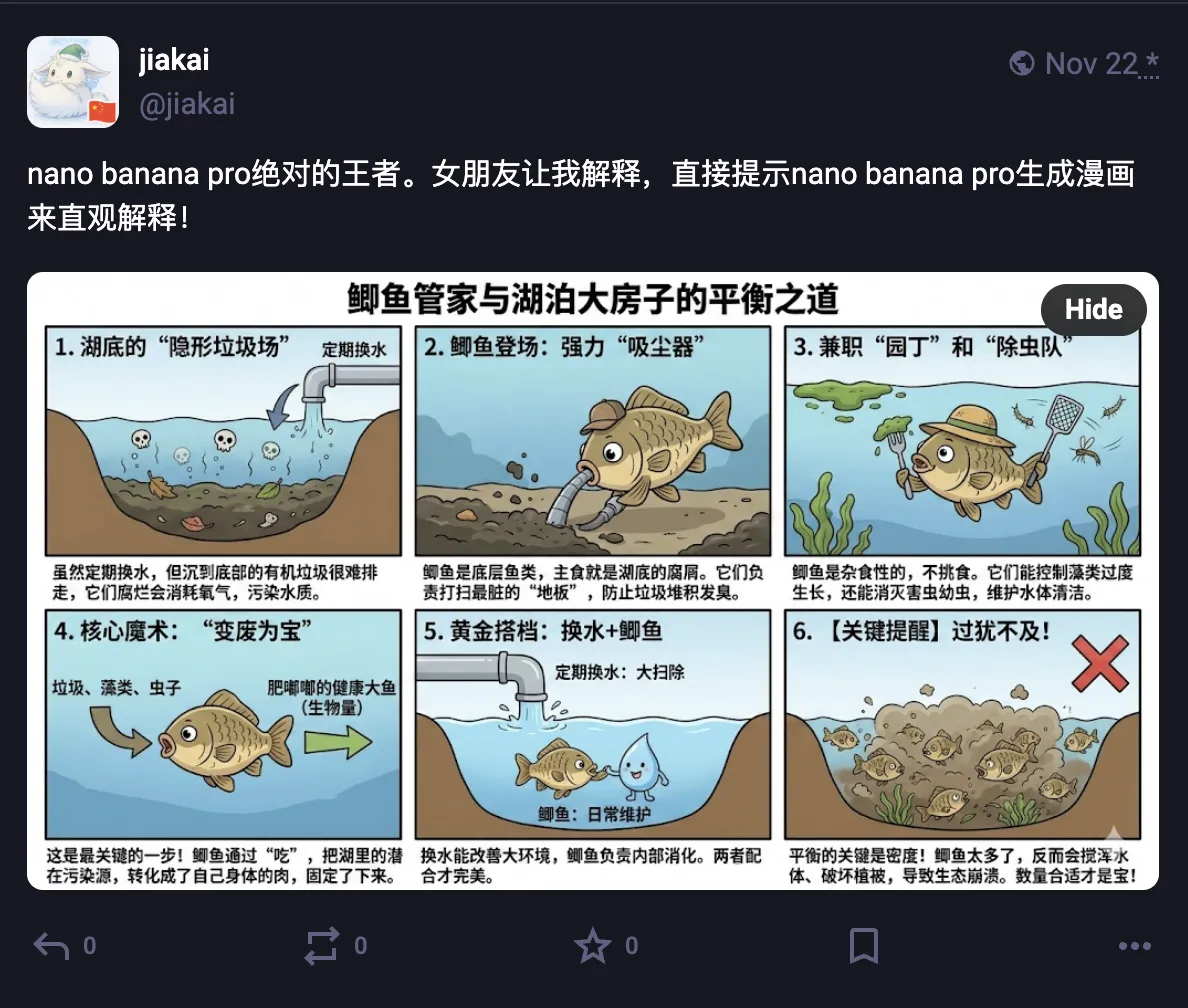
与此同时,Google的Nano Banana Pro文生图模型,凭借其SOTA的实力,可很好地弥补无现成网络图片可引用时的尴尬。
Gemini App中的Visual Layout则进一步丰富了可视化的内容,内嵌Youtube视频等Google生态内容,进一步扩展了可视化的边界。【个人认为目前AI Mode的体验稍好于Visual Layout】

如果Google后续能好好打磨产品,提升用户体验,未来他家的AI产品绝对是顶尖的存在,毕竟其生态是其余任何一家都无法比拟的。
前几天在Gmail中发现一封来自Phind 3的促销邮件,他们更新了全新的界面,可根据问题动态生成交互式UI。

我很好奇在Claude Opus 4.5的加持下,Phind的可视化展示能做到啥程度,于是乎花费了5刀开通Phind Ultra会员进行体验。

其可视化效果类似于Gemini App中的Visual Layout。下图展示可见此链接。
最近发现国内的GLM-4.6V在Image Search的加持下,也能生成带网络图片参考的回复。
国内的秘塔搜索也在可视化方面下功夫,基于国产的文生图模型搞了一个Meta-banana,以增进可视化回复效果。下图展示见此链接。

举了这么多案例,不难发现AI服务们开始在可视化方向发力,用图文并茂的输出来提升用户体验。
其中的技术路线主要有以下2种:
- 适时引用现成的网络图片(如Grok等)
- 基于强大的文生图模型生成合适的图片(如Gemini Nano Banana Pro等)
如果是生成小程序演示类的服务,还需要借助模型强大的编码能力。页面不美观、生成的小程序效果不佳等因素会降低用户好感度。
2. 可视化的合适时机
什么时候AI可视化回复对于用户而言是友好且必要的?那肯定是在LLM输出内容的文字过于密集时。
之前尝试各大服务的Deep Research功能时,就想过该功能最大的缺憾是缺少可视化,面对接近1万字左右的输出内容,大部分人都会选择略读或者看个大概。倘若在其中恰到好处地穿插可视化图片,可在吸引读者阅读兴趣的同时,使读者有更多的耐心阅读下去。
但并不意味着所有的AI回复都应该以可视化的形式呈现。夹带网络图片的可视化回复需要搜索相关图片;文生图模型生成合适的图片需要时间;生成可视化网页的回复需要生成网页代码,有时甚至还需要修复代码以实现良好的呈现效果。这些因素势必会拖慢回复速度。
在线上社交时,我们都期待秒回,这种渴望也同样适用于AI回复,一个简单的问题复杂化是不必要的,除非用户愿意用更多的等待时间来换取更高质量的回复。
最近用0元Team方案体验到了ChatGPT 5.1 Pro模型,有时发现其显示的思考时长是在给用户营造努力思考的假象,其大部分时间都在空转,在原地踏步,等到了一定的时间才给用户回复。有时我会没耐心等待,转而将提问转交给其余AI处理。
因此可视化输出需平衡速度与质量,不能为了花里胡哨而让用户慢慢等!
真正应该可视化的是那些需要概念阐释的提问,而一些如让模型Debug代码的场景则完全没必要,还有很多不应该可视化的场景……
Phind 3的可视化可以说是走了极端,其像是一个玩具,所有问题都会用代码生成一个交互式小程序。大部分网友们对于其发布的态度都是消极的。具体可以看看GPT 5.1 Pro的犀利点评。

3. 案例展示
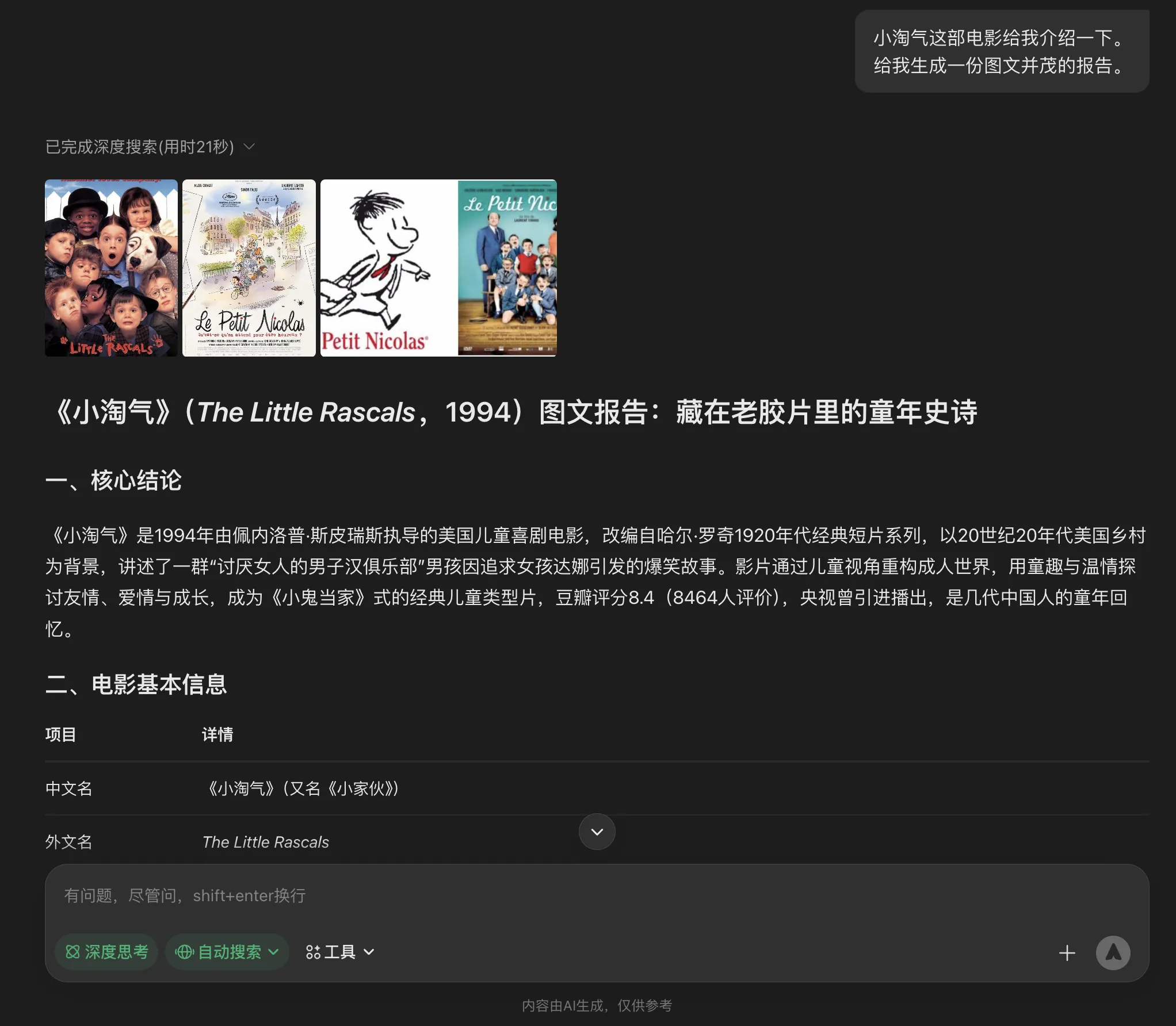
昨天看了一部年龄比我还大的喜剧电影《小淘气》,让AI们以可视化的形式进行影片的介绍,从它们的可视化回复中可比较可视化能力孰强孰弱。
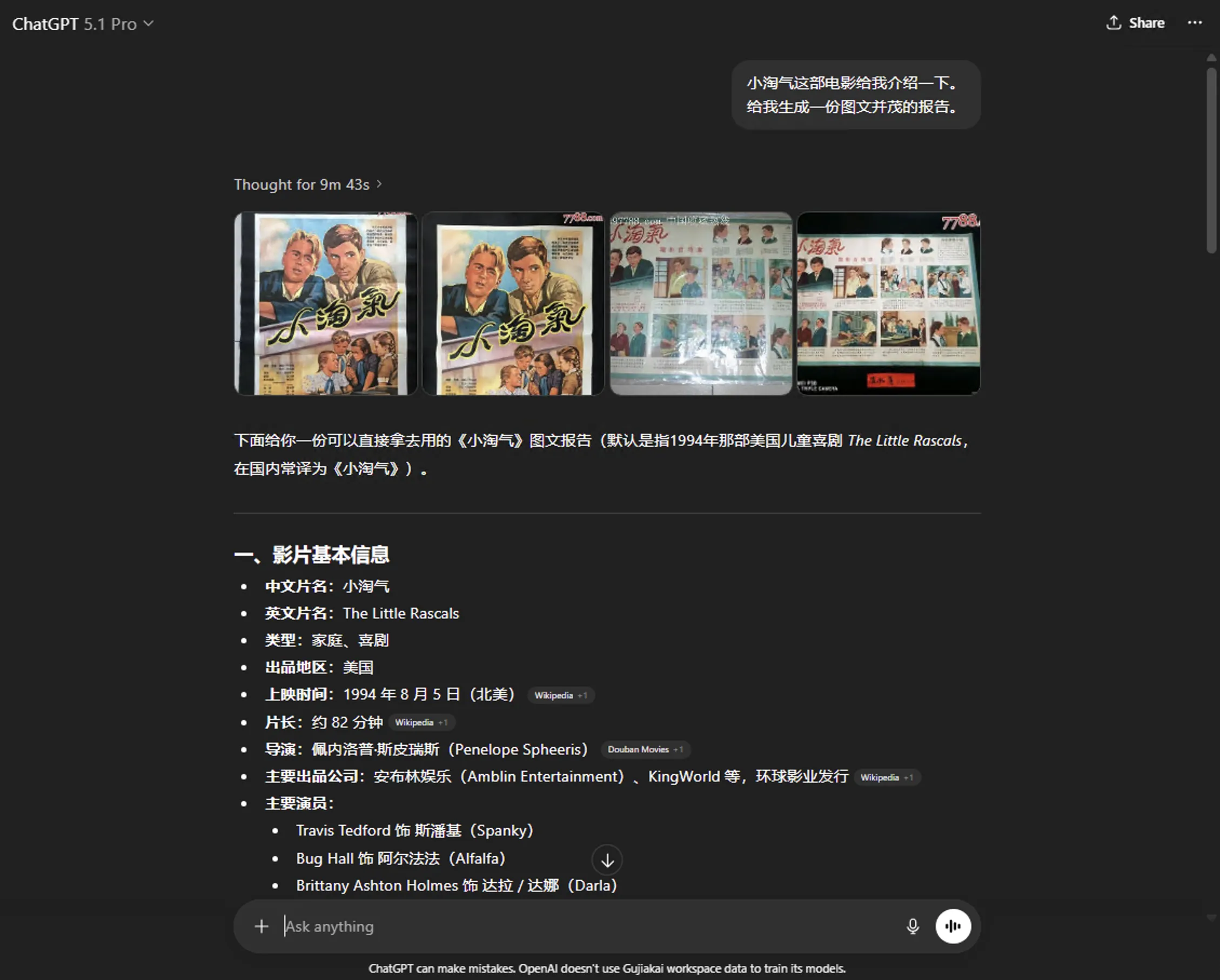
ChatGPT 5.1 Pro的回复如下图所示,可视化引用的网络图片放置在开头。
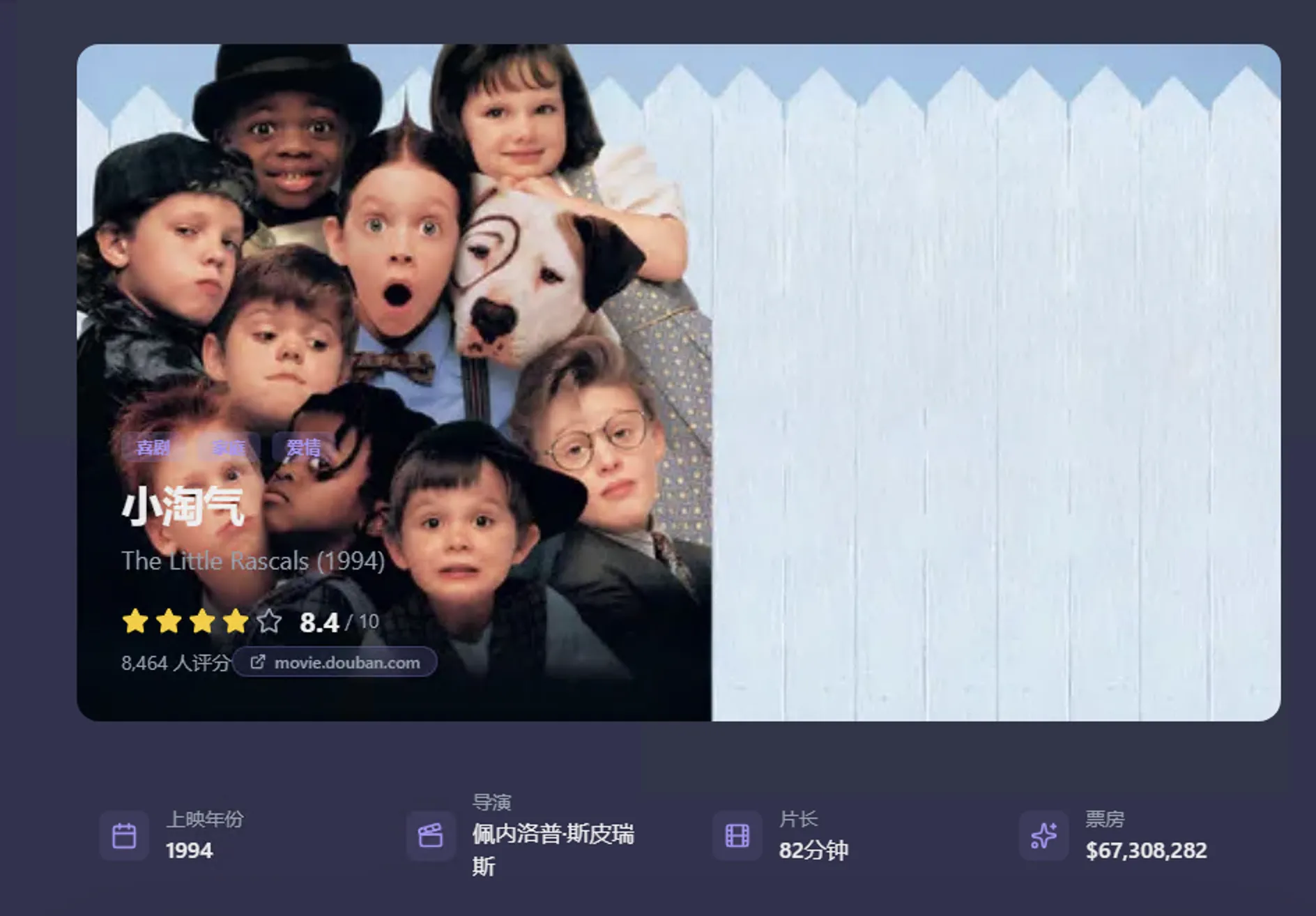
Gemini App的可视化调用了Nano Banana Pro工具,直接生成了对应的图片,不得不说这图片很逼真。

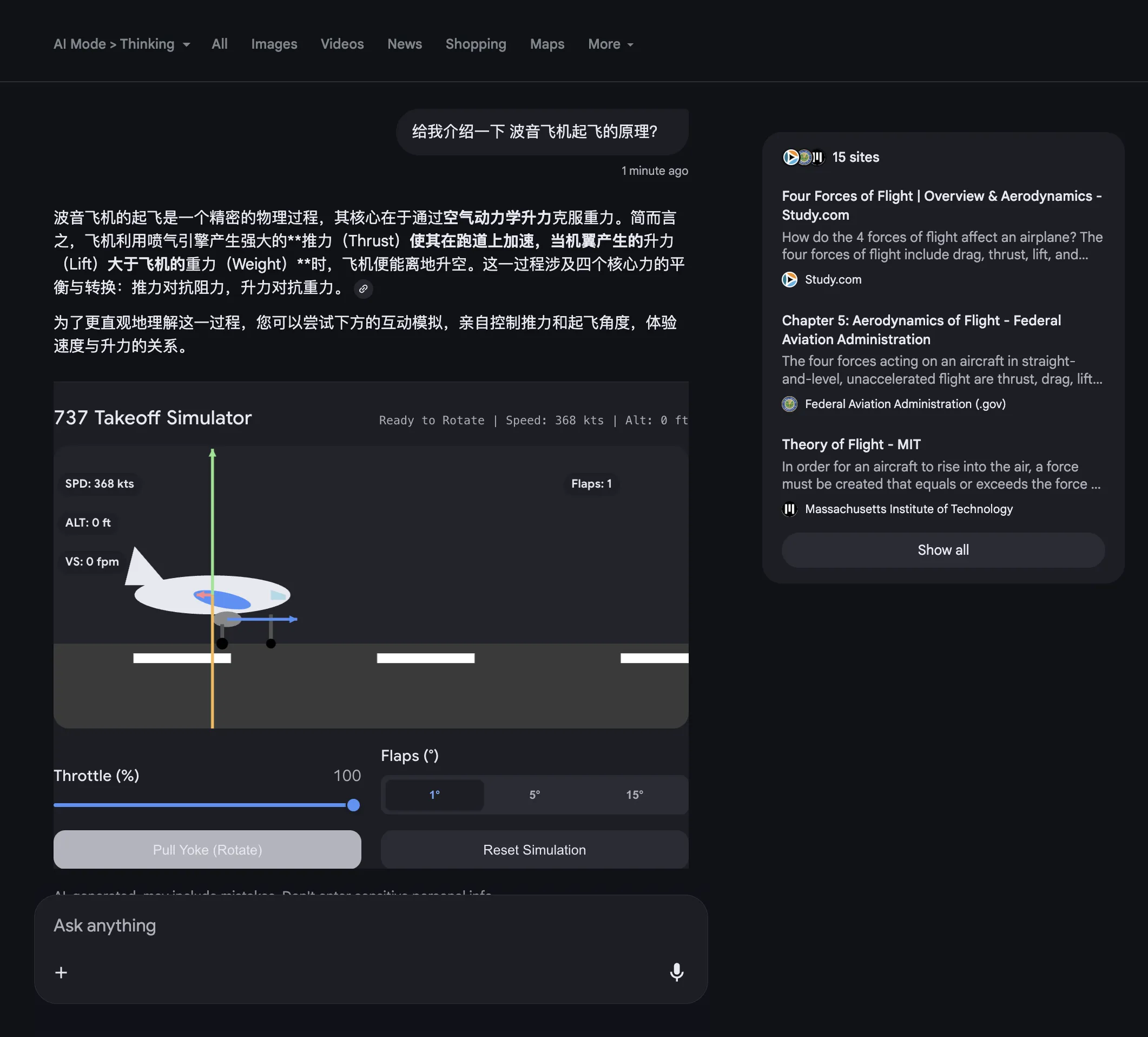
Google AI Mode的回复穿插引用网络图片,其排版深得我心。
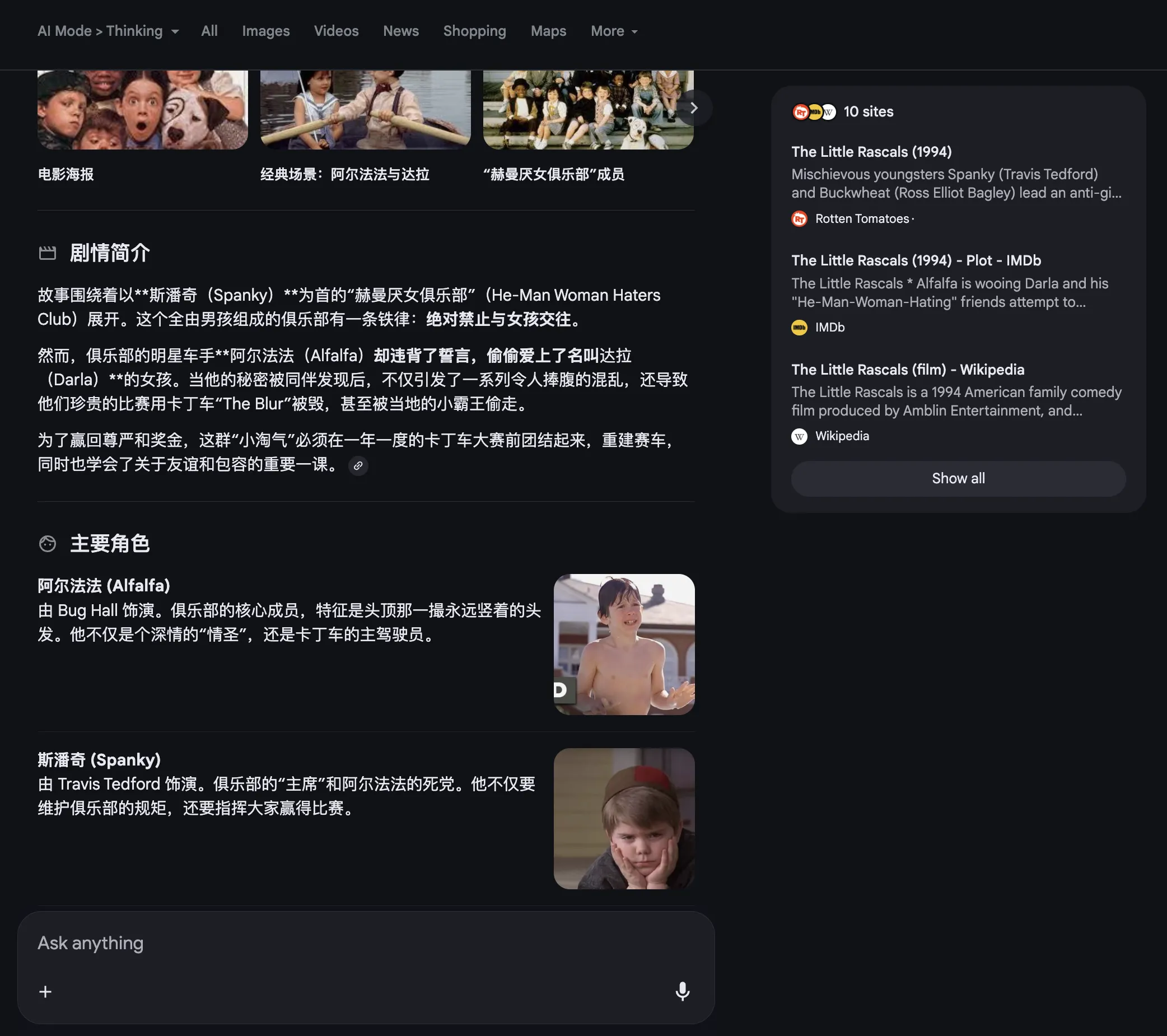
Grok的回复风格和Google AI Mode类似。链接。

Claude利用其编码能力,生成一个网页。可以看出Claude在日常使用场景中有时并不胜任,其主要还是适用于编码场景。

Phind 3的效果如下图所示,需要漫长的等待,毕竟生成是一个交互式小程序。链接。
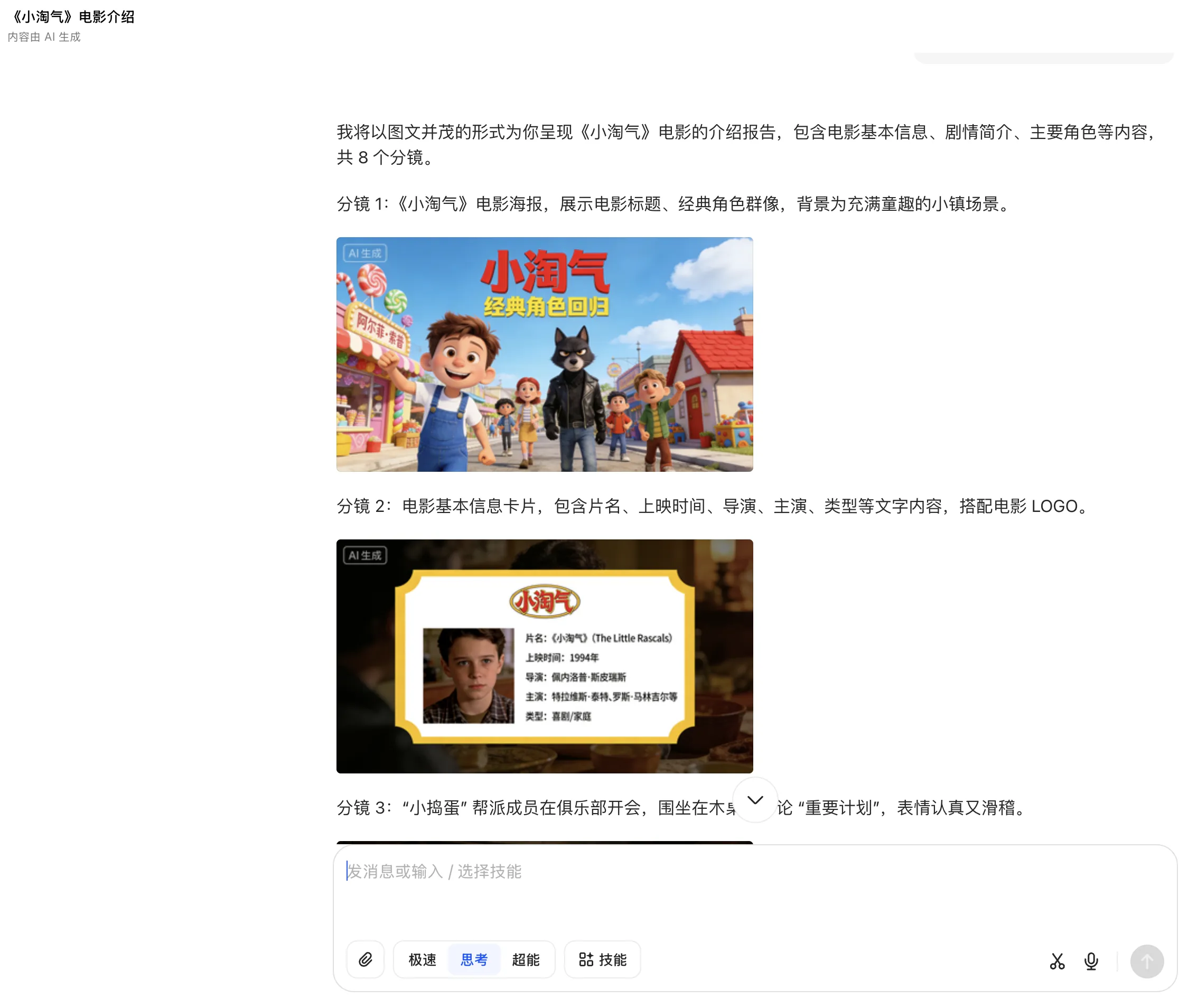
豆包利用Seedream文生图能力,生成了对应的分镜,效果不如Nano Banana Pro,毕竟《小淘气》是海外的电影。
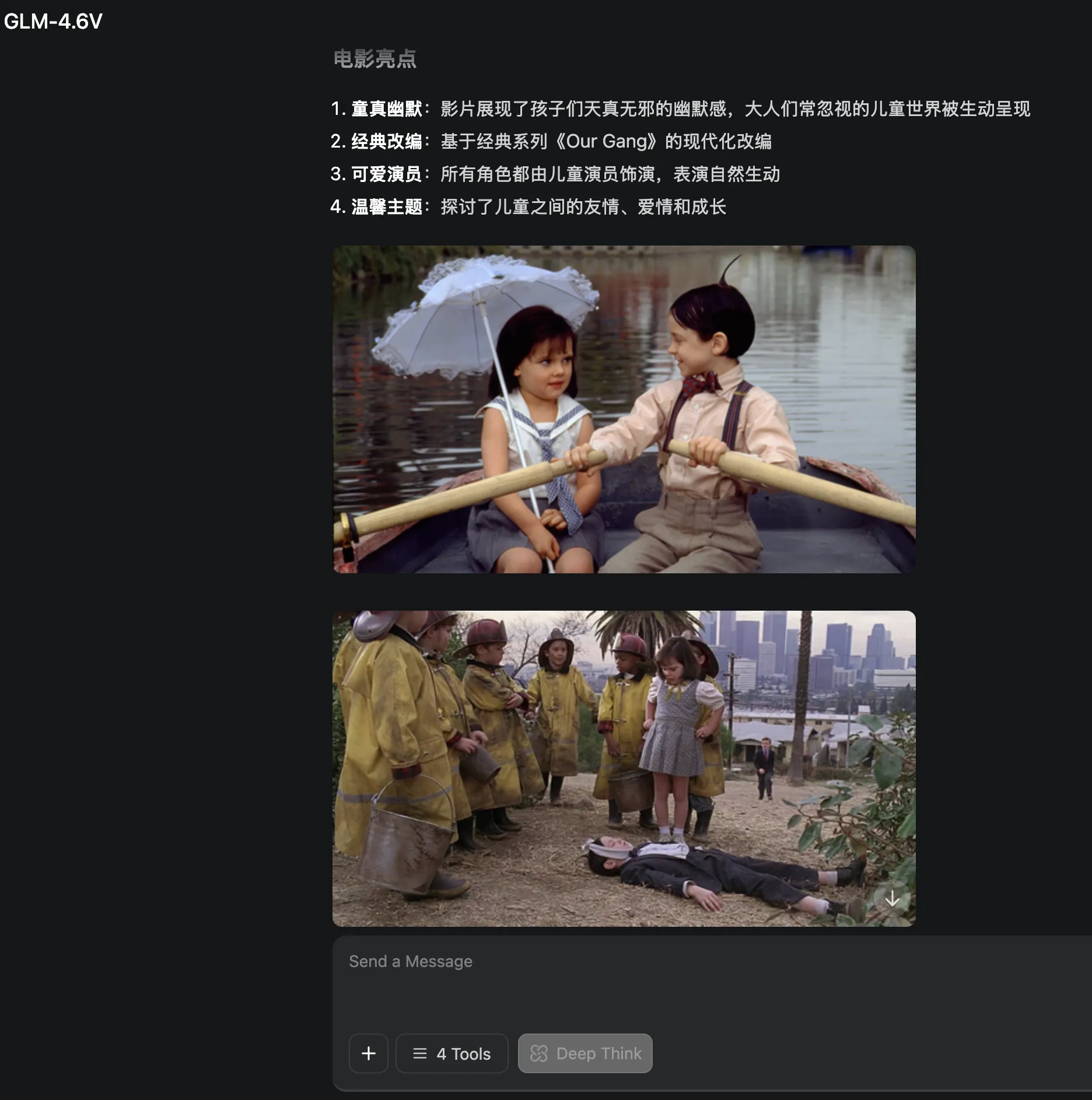
GLM-4.6V的回复类似于Grok,图文穿插排版,较容易吸引观众注意力。链接。
元宝的可视化引用网络图片也如ChatGPT一样放置在开头。
4. 尾声
大模型画答案依托的主要是模型的能力。编码能力不行,画出的答案界面不美观,用户压根不会有想看的意愿;画答案也讲究准确无误,但网络上内容参差不齐,模型辨识度不行,则可能导致其引用低质的内容;文生图能力不行,当网络上缺少恰当的图片时,可视化回复存在局限性。
总体而言,现阶段可视化效果最令我满意的是Google AI Mode、Grok、GLM-4.6V的回复,图文穿插的可视化形式给人一种娓娓道来的感觉。
文档信息
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享4.0许可证)