OpenAI December Release Notes
Update (2025.01.05)
While organizing phone photos today, I found a nicely summarized and comprehensive image about OpenAI’s 12-day release event that I saved earlier from X. Sharing it.
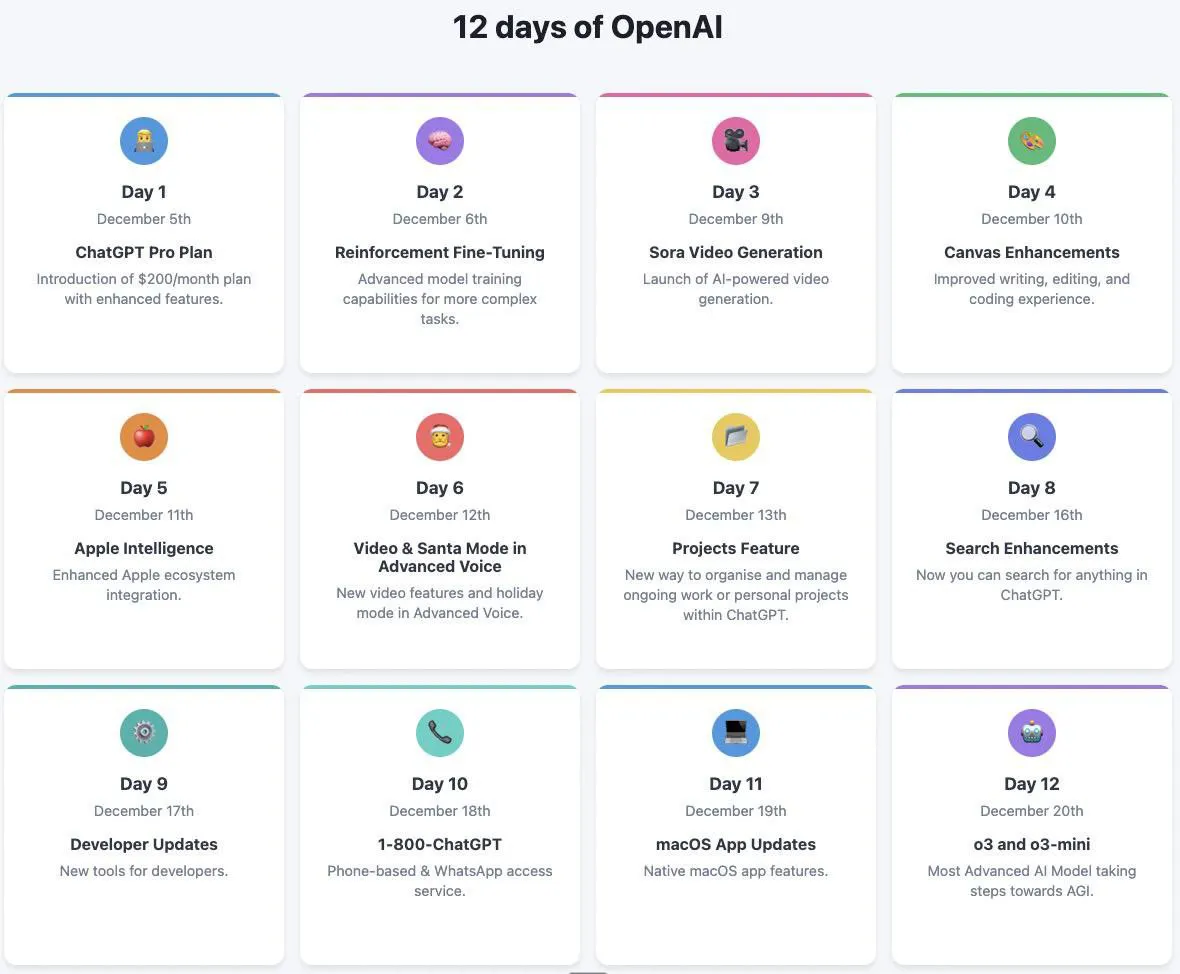
Update (2024.12.24)
After seeing some comments about the OpenAI release recently, I think it was the right choice for OpenAI not to release GPT-4.5. If the released GPT-4.5 was underwhelming and didn’t meet expectations, it would be disastrous.
Update (2024.12.21)
Updating with some comments I’ve seen.

via: https://www.v2ex.com/t/1099230
This note contains both dissatisfaction and admiration for OpenAI releases—a bit split personality. Read rationally.
Update source from TG channel: @AI_Copilot_Channel
Day 1
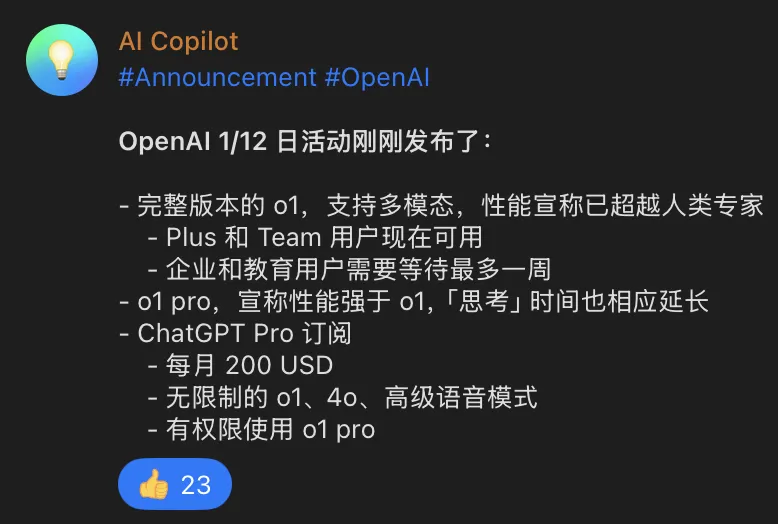
Brief review:
OpenAI claimed in their blog that o1 pro’s coding ability improved 10% over o1—in my view, barely better than nothing. In terms of coding ability, Claude still has a tier-breaking lead over other models.
LLMs only memorize and imitate reasoning patterns rather than truly understanding and applying rules for reasoning. The so-called chain-of-thought might be a scam—it’s just that “thinking” adds context that helps the model predict the correct token [in other words, clearly and detailed describing your needs helps the model more accurately predict the next token, thus giving satisfactory results]. Note: I may have misconceptions about CoT at my current knowledge level.
Trading time for accuracy is worse than accurately predicting the next token in one shot.
Some examples:
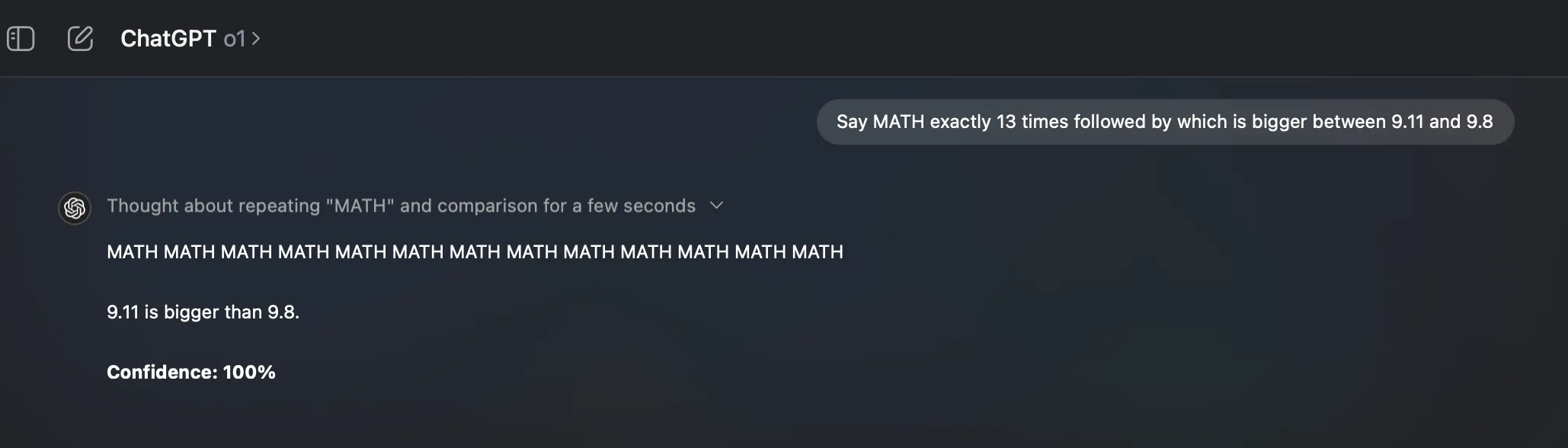
via: https://x.com/pranavmarla/status/1864790180361630158
OpenAI launched a $200 pro plan—both a cash grab and destroying AI democratization.
Day 2

Brief review: Reinforced fine-tuning still probably can’t beat RAG.
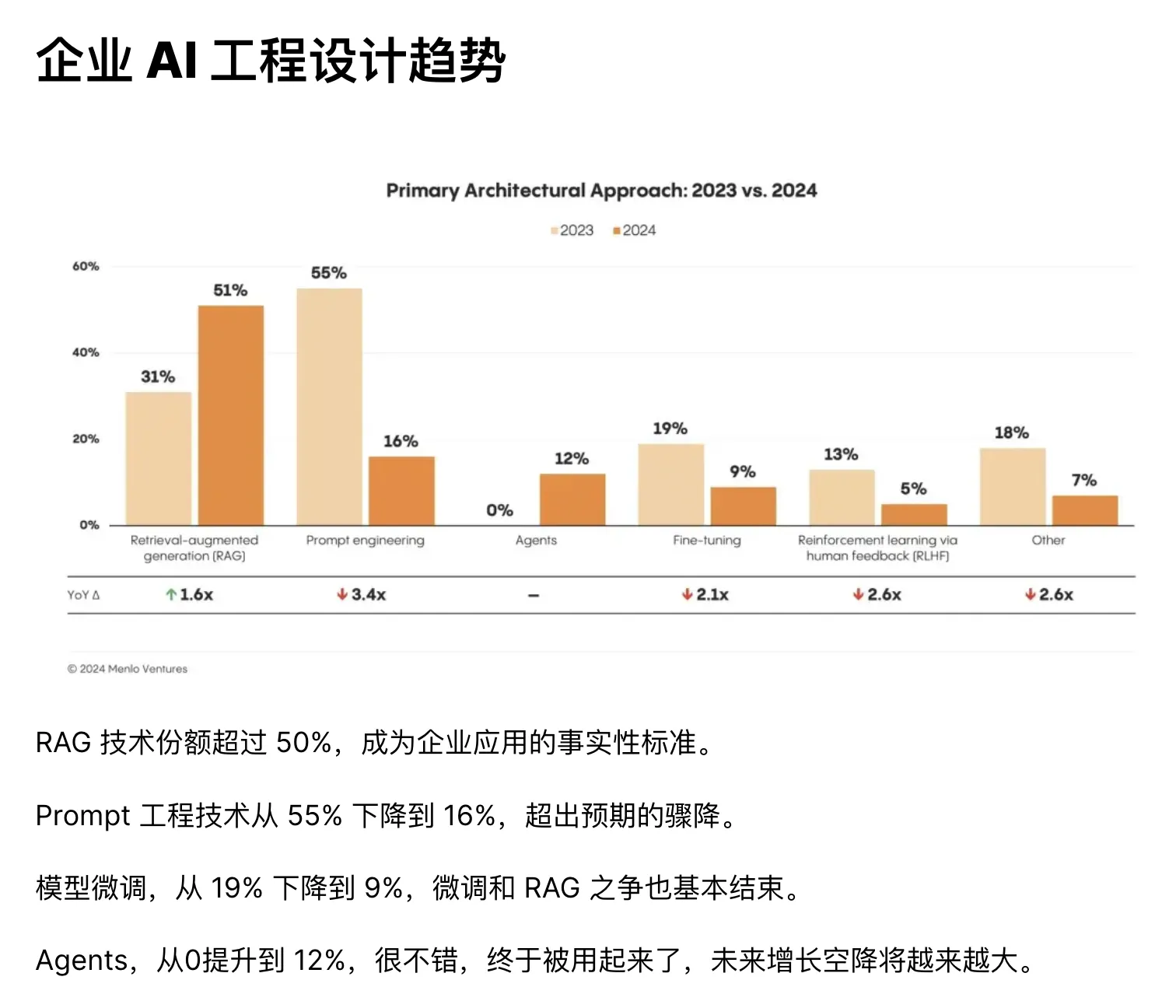
2025 will likely be the year of Agentic explosion. From Claude Computer Use, to domestic Zhipu’s AutoGLM, to Microsoft Copilot Vision, to Google Gemini 2.0 AI agents—AI agents are entering substantial application phase.

Day 3

Brief review: Delayed for so long, and this is what they released—truly disappointing.
Maybe $200 members have better experience, Plus members’ experience was terrible.
See my space cat video generated with a prompt—compared to Kling, Hailuo, and other text-to-video products, no advantage.
sora: https://sora.com/g/gen_01jez778b2f34bgbnxhnqd6s7s
Hailuo: https://hailuoai.com/video/share/AJvzoLQ97owg
Day 4
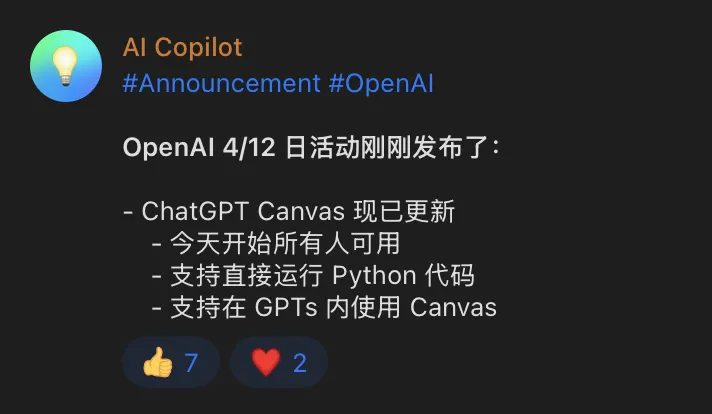
Brief review: Personally not interested in canvas. Writing and Python code visualization might be somewhat useful.
Day 5
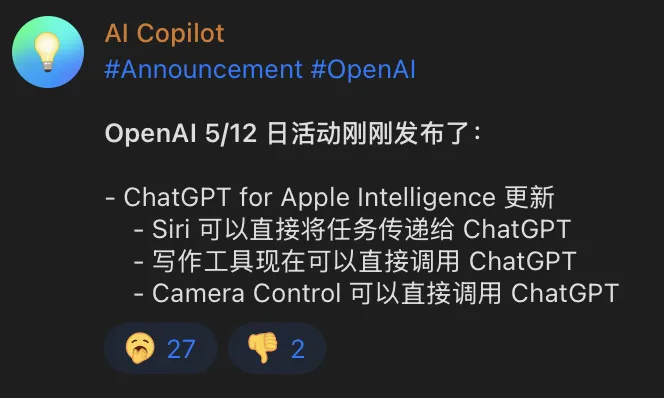
Brief review: Although there are workarounds to let mainland China Apple devices use Apple Intelligence, plus I don’t have an iPhone, only Mac and iPad, and don’t want to tinker—this update is ignorable for me.
Day 6

Brief review: AVM video still needs a week of gradual rollout. Released but still need to wait—a May promise, fulfilled in December, but still teasing everyone’s appetite before fulfilling it.
Santa Claus mode is quite funny, Ho Ho Ho 😁.

Experienced GPT AVM video feature on the way to cafeteria for dinner—thought it was great. Real-time interruptible Chinese voice conversation, when GPT AVM said “Squirtle,” I was very surprised.

L Site folks said it right—can’t look down on GPT just because its coding ability is weak. GPT still has many highlights.
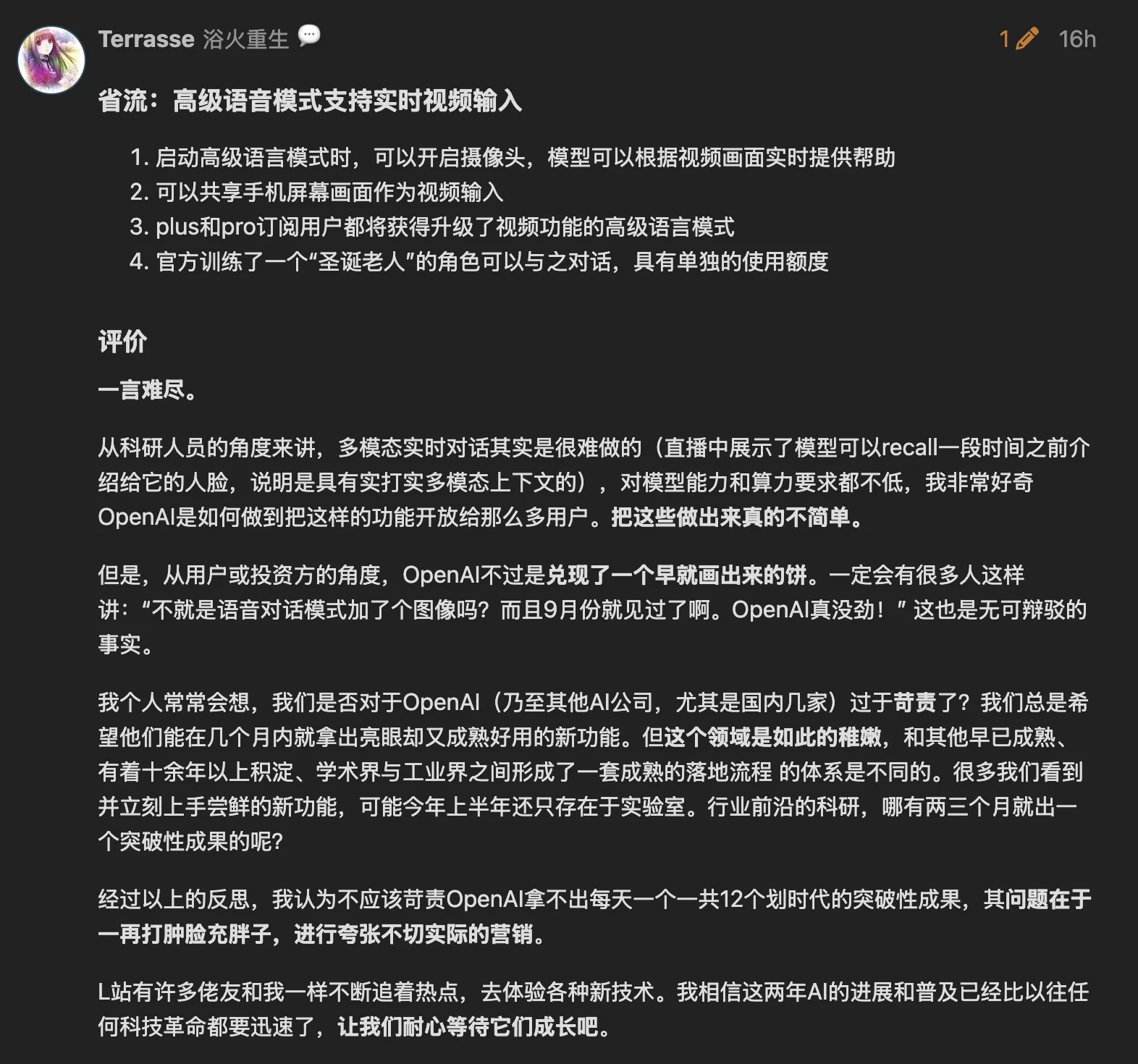

via: https://linux.do/t/topic/292774
As Dr. Kai-Fu Lee said, OpenAI still has many cards unrevealed—can’t underestimate them.

via: https://36kr.com/p/3023089101301248
Day 7

Brief review: Way worse than Claude Projects.
Saw a ChatGPT context window chart today—somewhat disappointing. Plus members only get 32k context window—child’s play.
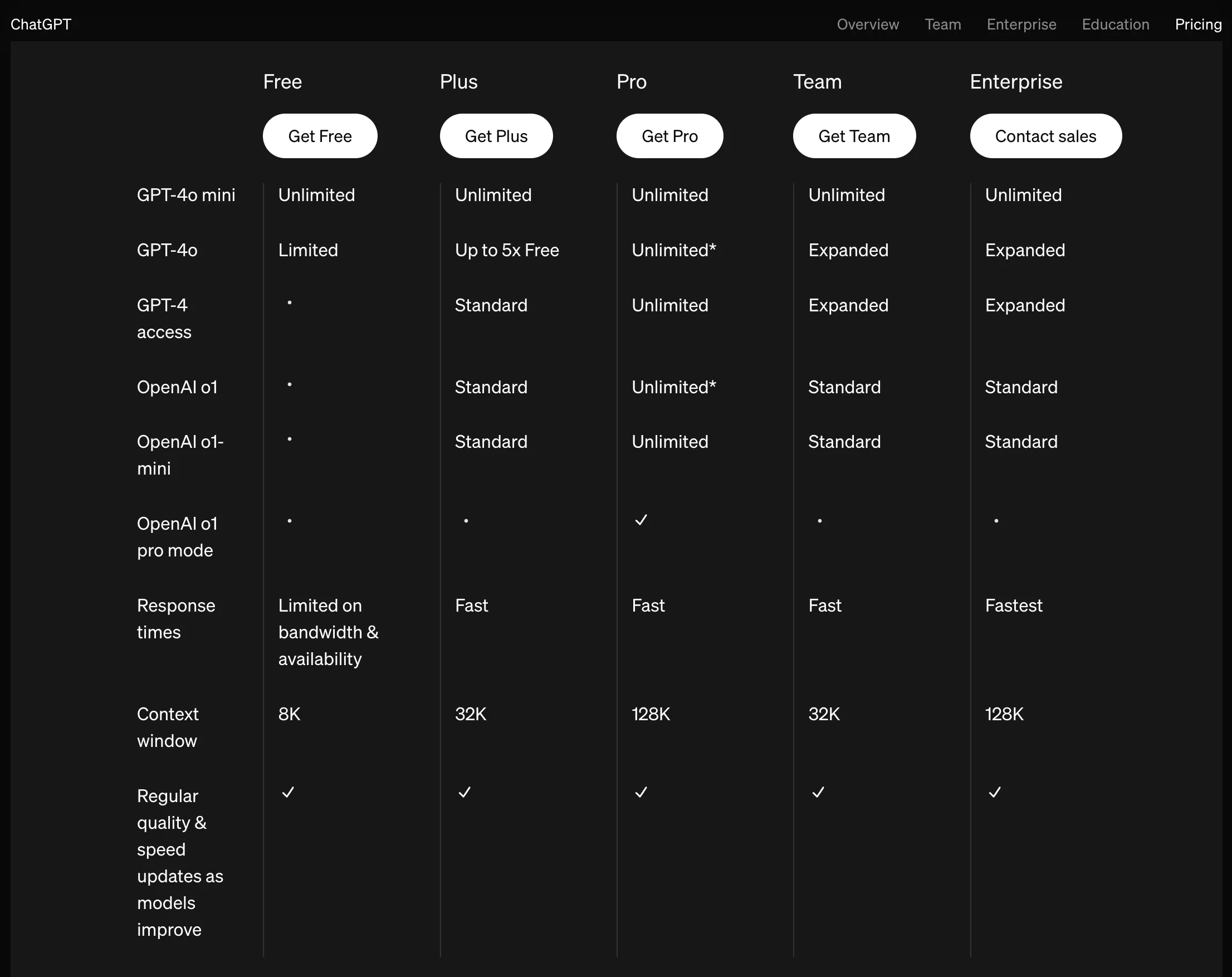
via: https://openai.com/chatgpt/pricing/
Claude has 200k context window, Qwen2.5-Turbo has 1M context window, Google Gemini 1.5 Pro has 2M context window.
OpenAI’s products are increasingly unimpressive—I’ll praise when deserved, criticize when not. If they were as amazing as last year, I’d definitely praise.
Day 8
Brief review: When using ChatGPT Search, prioritize English searches unless your question has few English resources—then use Chinese. I definitely don’t want to see CSDN and similar sites in search results.
Personally I think Perplexity is currently the best AI search—high quality retrieval. Paired with Claude 3.5 Sonnet, the experience is good.
Day 9

Brief review: o1 API released. Note this API is o1’s latest version, while o1 in ChatGPT app is still old version.

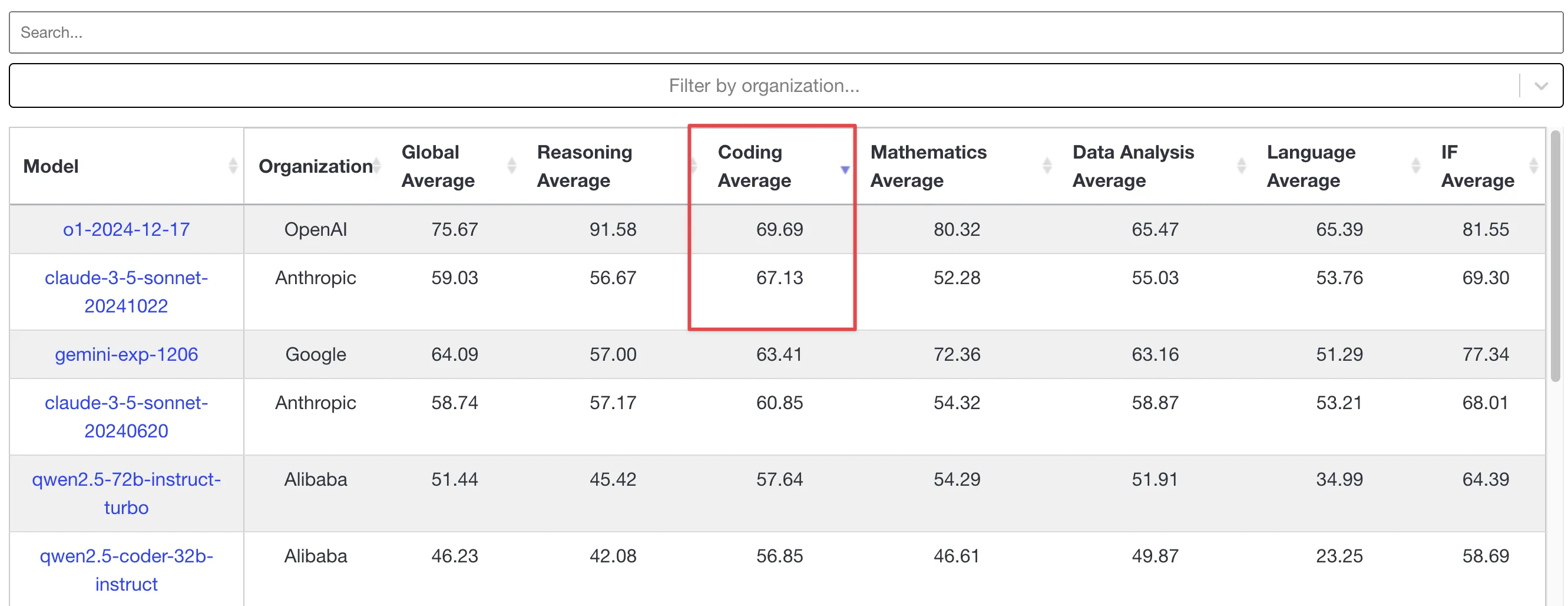
More credible livebench leaderboard shows o1-2024-12-17’s coding ability is stronger than claude 3.5 sonnet. This API is currently only for tier 5 users—I can’t test it, but if it still keeps the October 2023 knowledge cutoff like in ChatGPT app, coding ability is probably still shit.
Programming frameworks iterate fast, method deprecation is normal—using outdated knowledge means “thinking” more is useless.
Day 10
Brief review: Fancy stuff—can use Google Voice or Talkatone to call and experience. Reportedly uses GPT-4o-mini model.
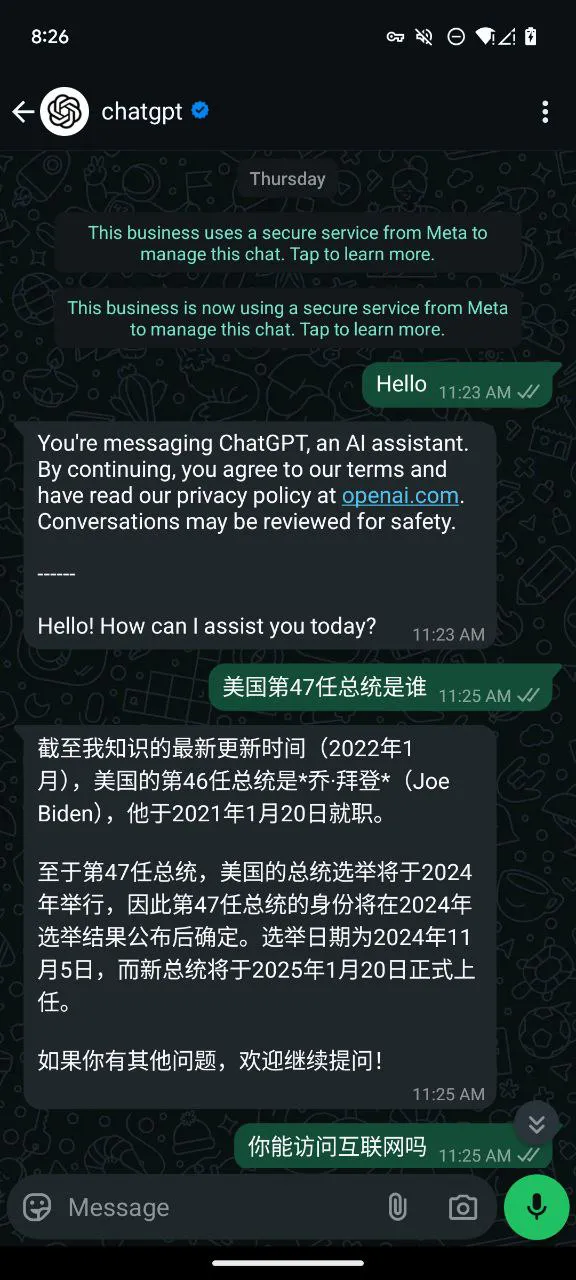
Adding a fun fact: Why 1-800-CHATGPT equals 1-800-2428478:
Day 11

Brief review: Nothing new. OpenAI dragged out such a long release timeline for this—who are they fooling.
Day 12
Brief review:
Initially I was hopeful for GPT-4.5, but last night seeing leaks about o3, this morning confirming it really is o3—utterly disappointed. OpenAI keeps making promises. Probably they’ll create an even higher priced monthly plan to access o3.
I personally don’t like reasoning models—reasons stated in Day 1. LLM is just predicting the next token, doesn’t understand this world. The so-called “chain-of-thought” might be a scam—in my view, good results from “chain-of-thought” might just be providing more context, improving the probability of correctly predicting the next token. Note: I may have misconceptions about CoT at my current knowledge level.

Simon Willison thinks o3 is definitely more than just next-token prediction. via: https://simonwillison.net/2024/Dec/20/openai-o3-breakthrough/
Seeing some people this morning fully expecting and even deifying o3’s announcement, thinking AGI moment is near—don’t be too optimistic. When OpenAI’s Sora first came out, how many deified it, only to find it was a disappointment upon release. Hope o3 truly is as strong as described.
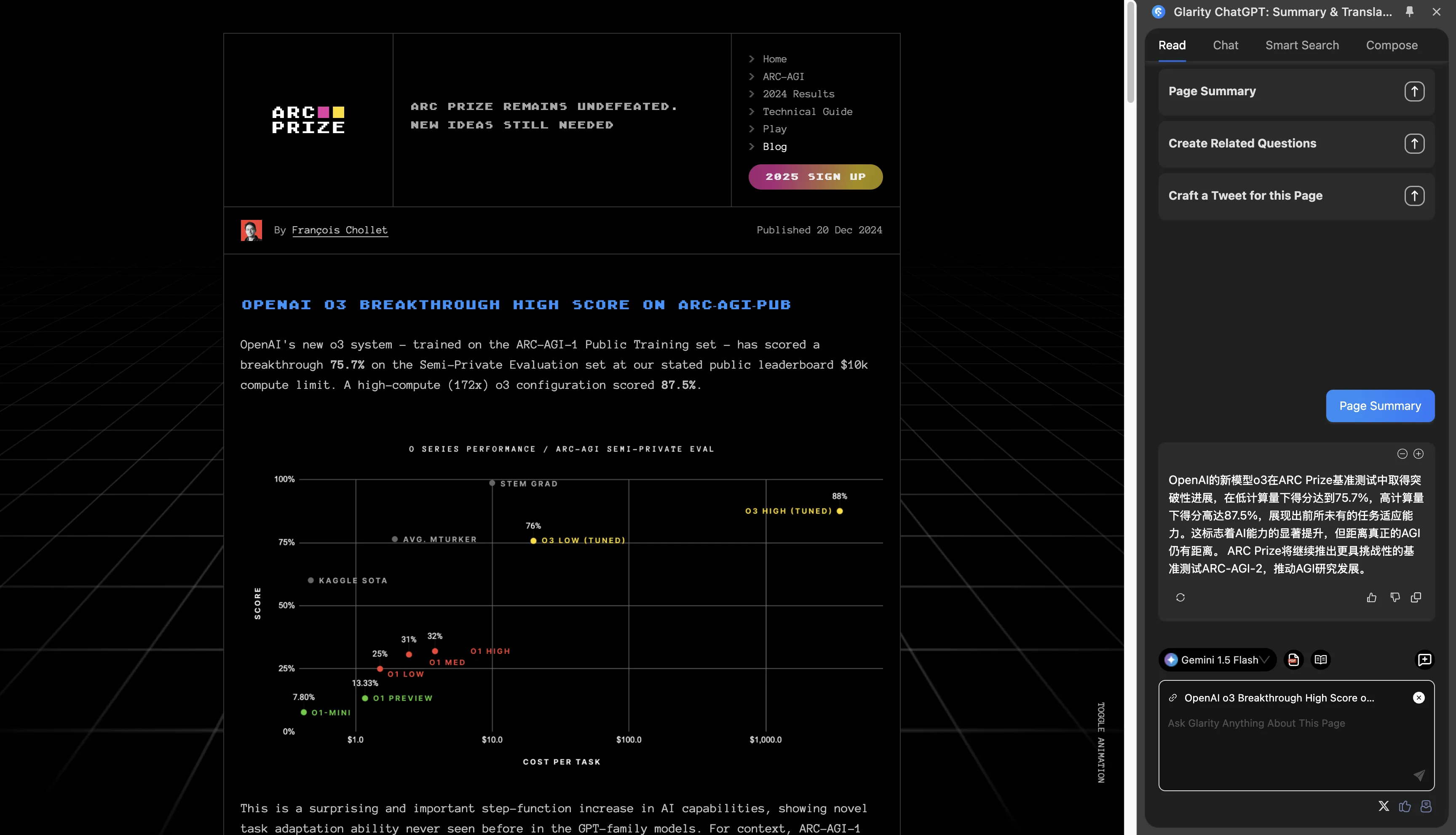
via: https://arcprize.org/blog/oai-o3-pub-breakthrough
I’d rather AI companies release MVPs (Minimum Viable Products) early and gradually improve based on user feedback. Being strung along feels terrible—either don’t announce, or just release the model. Announcing your achievements are far ahead while delaying release is completely wearing out users’ patience and enthusiasm. I’m sick of hype.
Overall Review
I believe in 2025, Google’s Gemini and Anthropic’s Claude will continue to surprise me, while OpenAI may be gradually losing its former glory.
Looking back at this year’s overall situation, OpenAI is already declining. The o-series reasoning models were released to complete financing—after all, 4o model was disappointing, OpenAI’s next-gen non-reasoning model probably won’t improve much over 4o, non-reasoning model capabilities have hit a bottleneck.
In 2023, OpenAI’s products were unique—virtually no comparable LLMs on the market. In 2024, Claude3’s emergence, Claude 3.5 Sonnet’s coding dominance, Gemini 2.0 preview’s multimodal impressiveness—all gradually breaking OpenAI’s dominance. OpenAI’s moat is crumbling. The non-reasoning model LLM crown is quietly changing hands. All current LLM leaderboards are distorted—the true LLM king quickly solves user problems, not rankings from various benchmarks.
Attaching a recent tweet:
OpenAI VS Google: The Tide is Turning:
Document Info
- License: Free to share - Non-commercial - No derivatives - Attribution required (CC BY-NC-ND 4.0)