Gemini 2.0 Experience
Update (2025.3.26)
Gemini 2.5 Pro is out. After watching some blogger reviews, impressed that Gemini OCR ability has improved even more.
Update (2025.3.19)
Last night, Gemini App updated again. via: https://blog.google/products/gemini/gemini-collaboration-features/
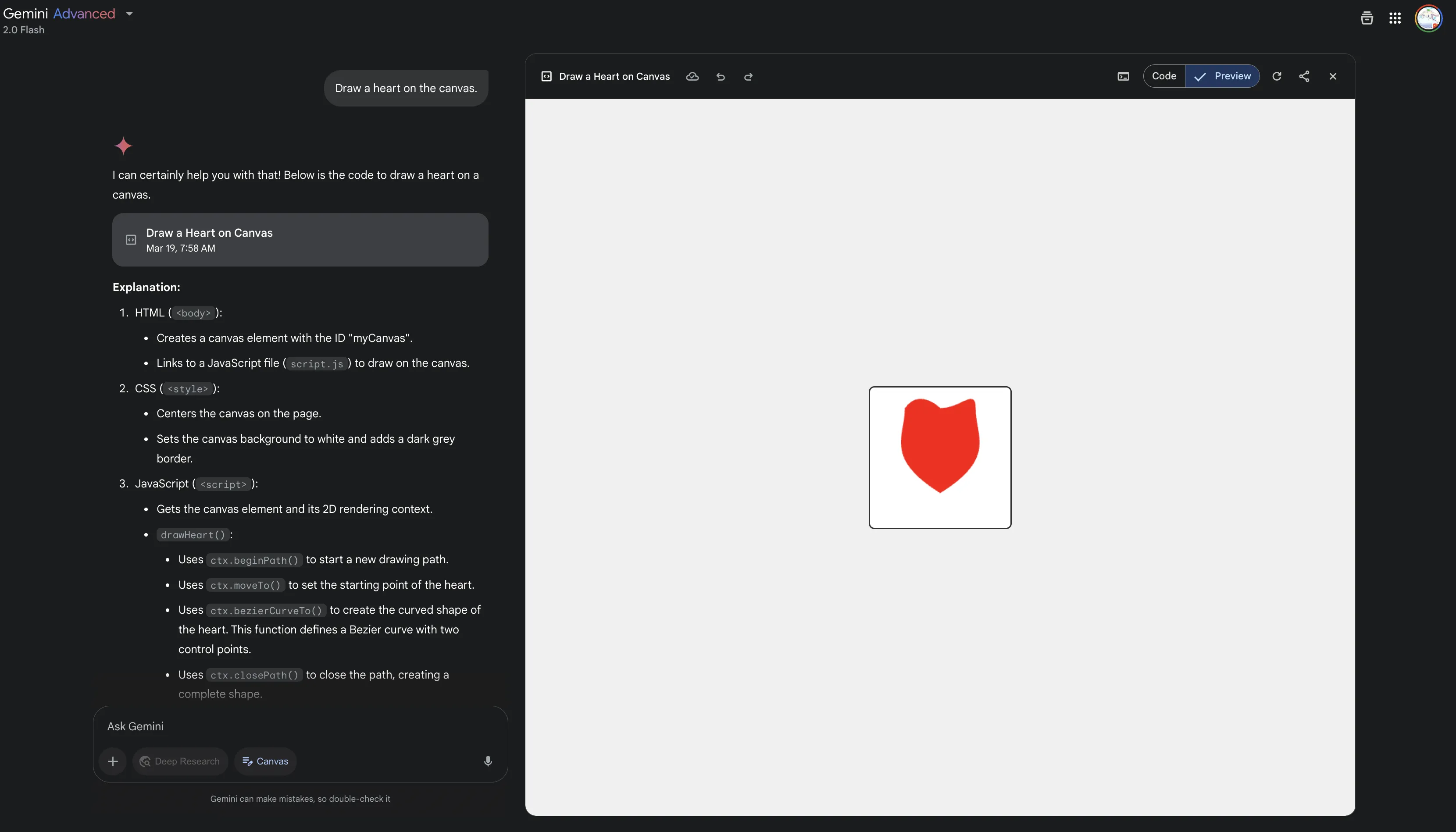
- Canvas
Similar to Claude Artifacts, ChatGPT Canvas. ChatGPT’s Canvas started supporting code rendering in January this year.
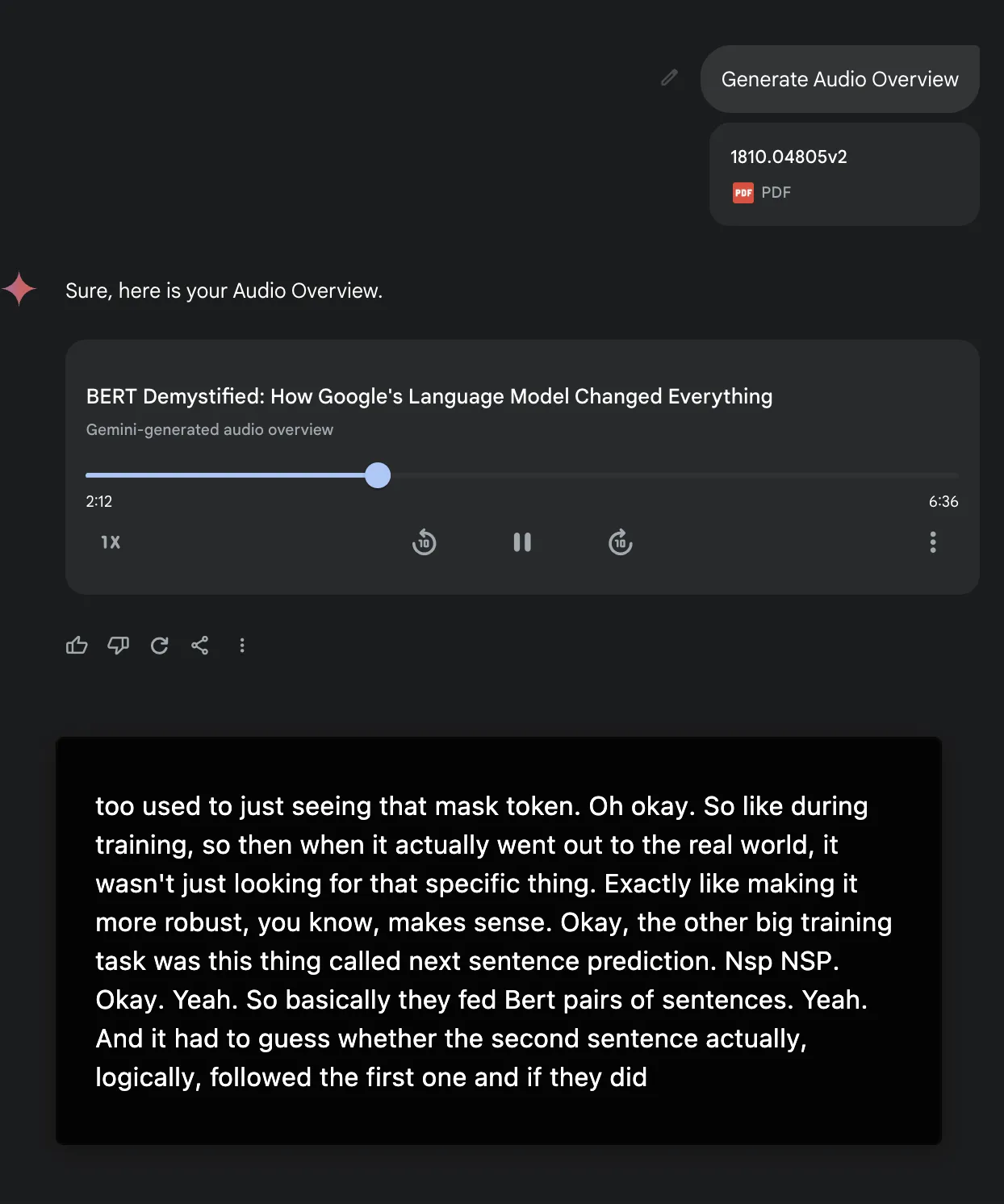
- Audio Overview
Added NotebookLM’s Audio Overview feature to Gemini—still only supports English podcasts as always.
Must complain—why is Gemini 2.0 Pro still Exp? Flash model with more new features still isn’t competitive! Expect 2.0 Pro to shed its Exp coat in May.
Update (2025.3.14)
Last night Gemini App updated Deep Research [free users’ quota changed from 5/month to 10/month], replacing model from 1.5 Pro to 2.0 Flash Thinking Experimental. Non-Advanced users can use it too. Currently Advanced users only have one more option than free users: 2.0 Pro Experimental—increasingly marginal.
Gemini series models can indeed be completely free—after all, AI Studio’s 2.0 Pro Experimental now supports YouTube video summarization too, while Gemini App’s 2.0 Pro Experimental still can’t connect to YouTube.
Gemini users can try Deep Research a few times a month at no cost. Completely free—same logic as Grok, register multiple accounts and it’s definitely enough.
Update (2025.3.13)
Google AI Studio added YouTube video support.
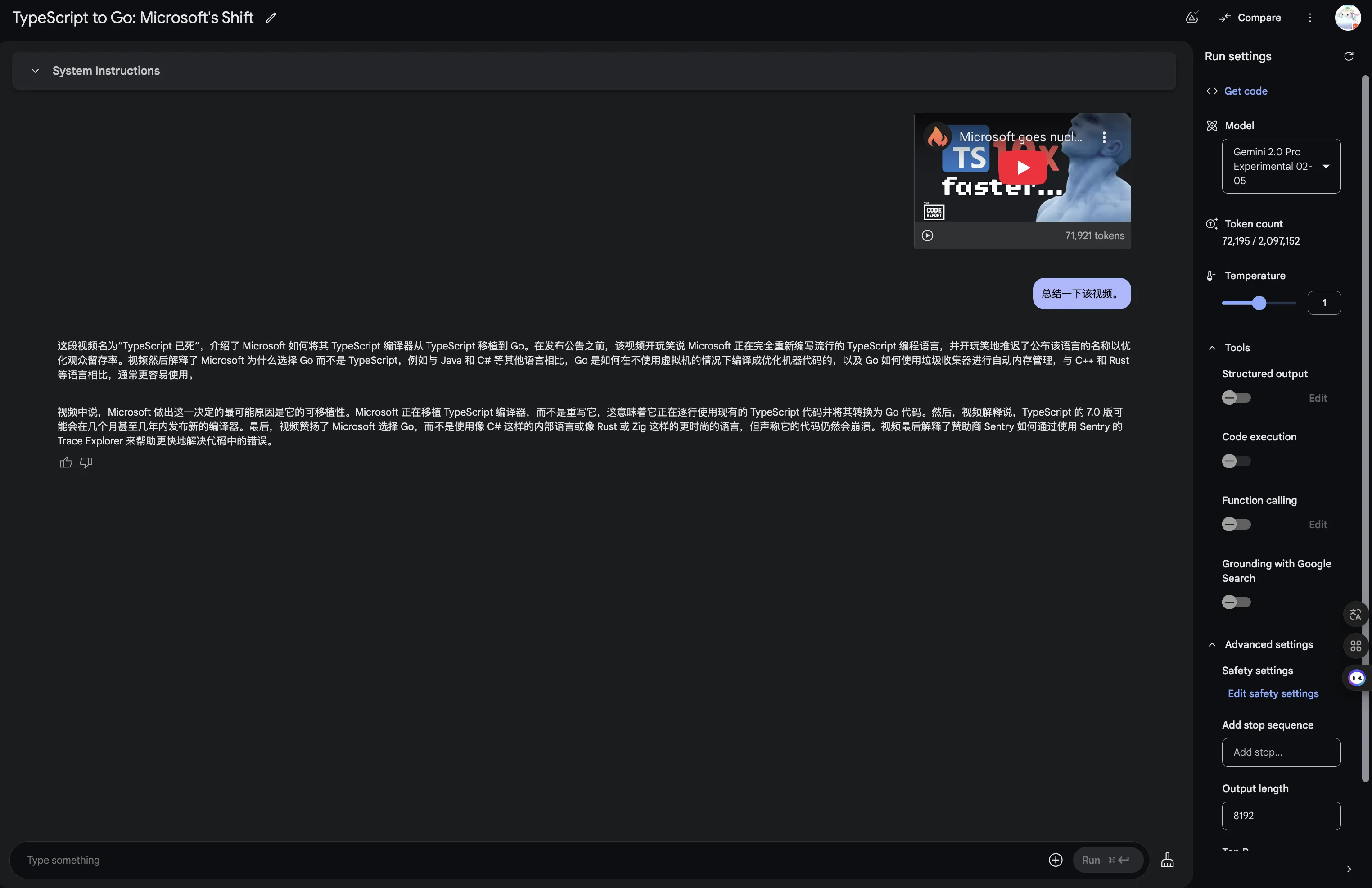
Feels like native video understanding ability, not implemented through YouTube subtitles.
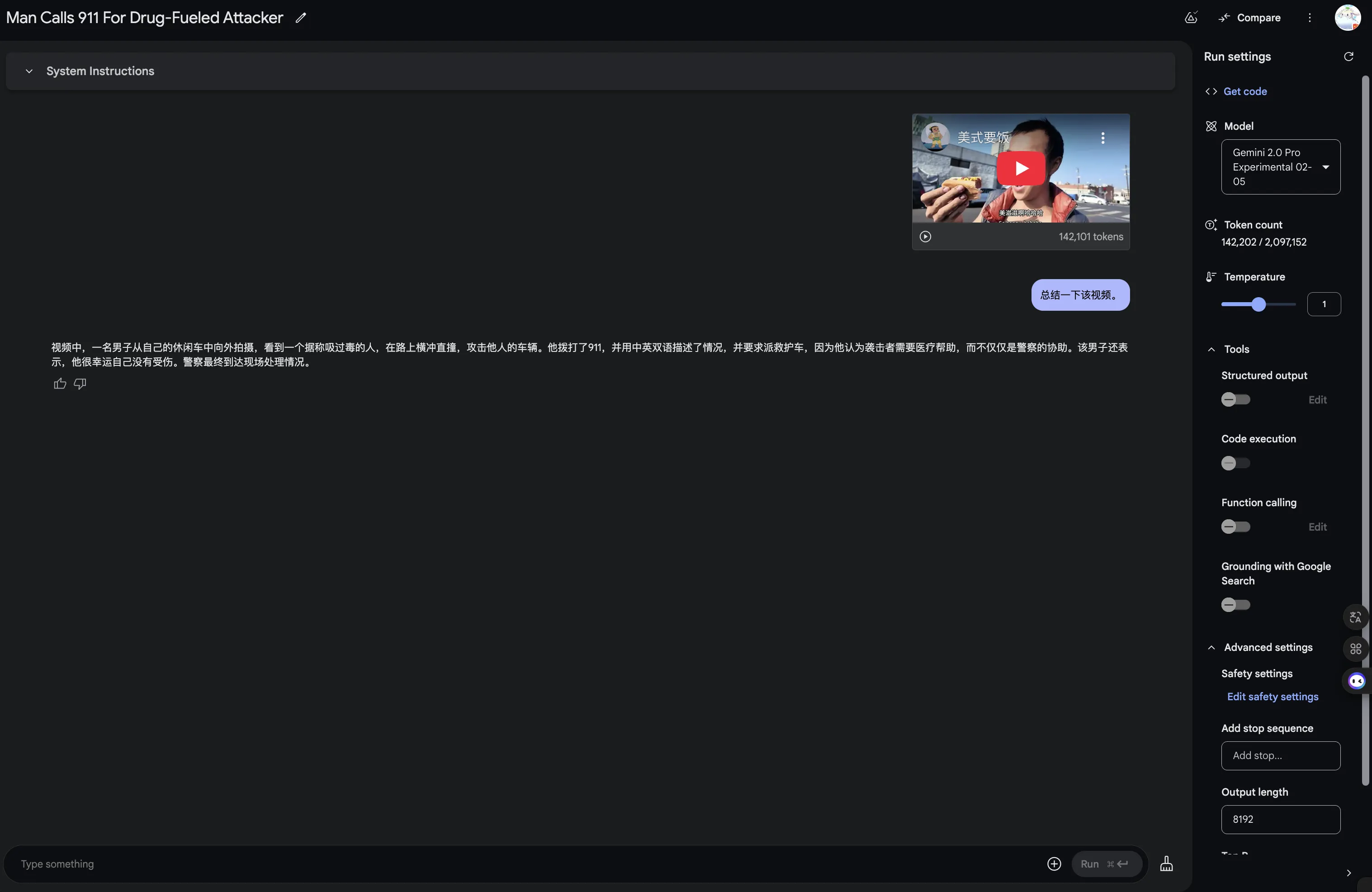
YouTube videos without subtitles can also be roughly understood.
Sometimes I wonder if Gemini understands YouTube videos through subtitles or pure native video understanding. Key point—this video has no subtitles at all. Anyway YouTube belongs to Google ecosystem—summarizing videos is a piece of cake. Note: According to Logan who manages AI Studio, it’s native video understanding. Native Video Understanding!
Videos without subtitles—Monica can also summarize.

Meanwhile, Gemini 2.0 Flash Experimental added native image output! True multimodal!
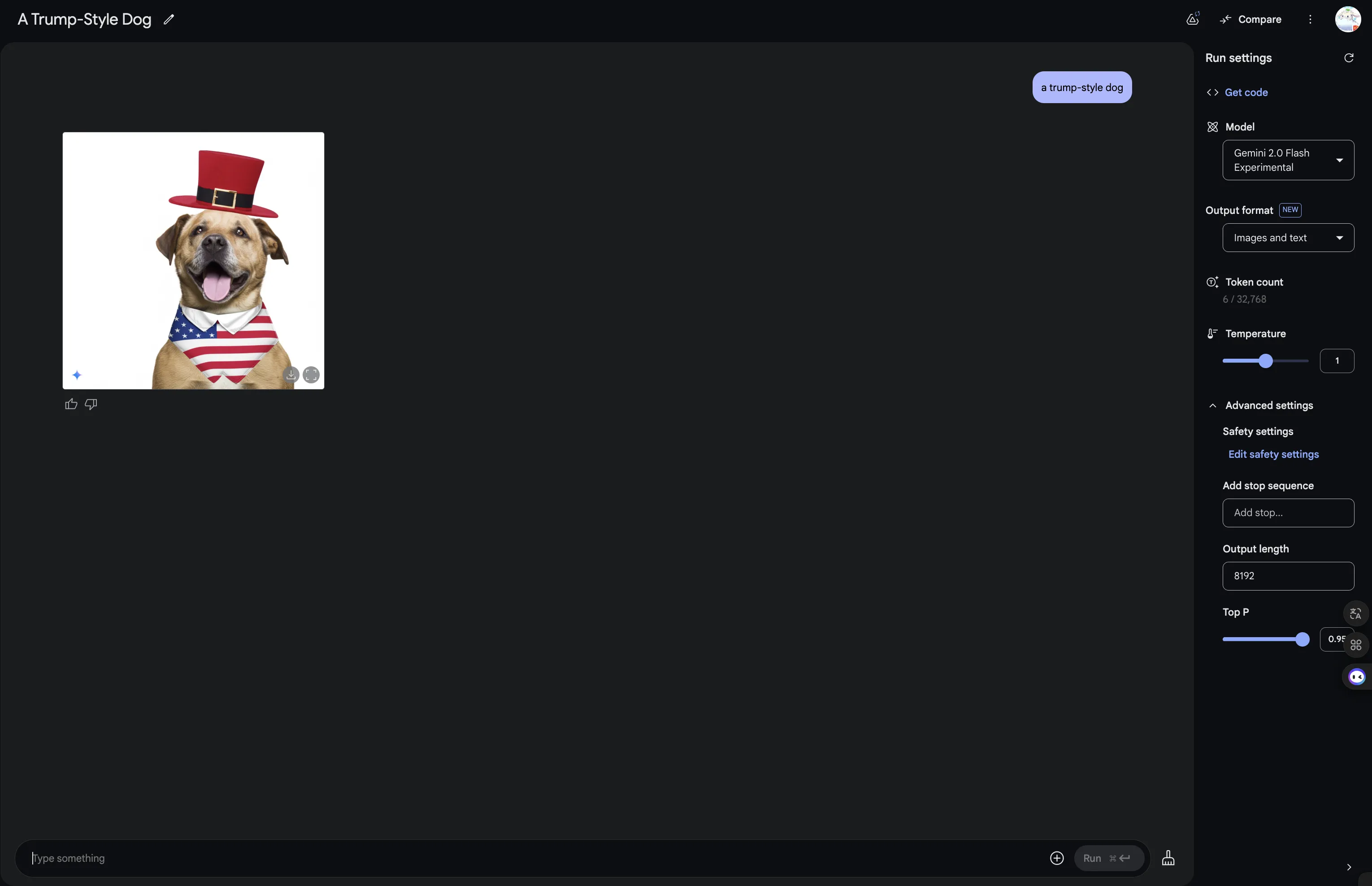
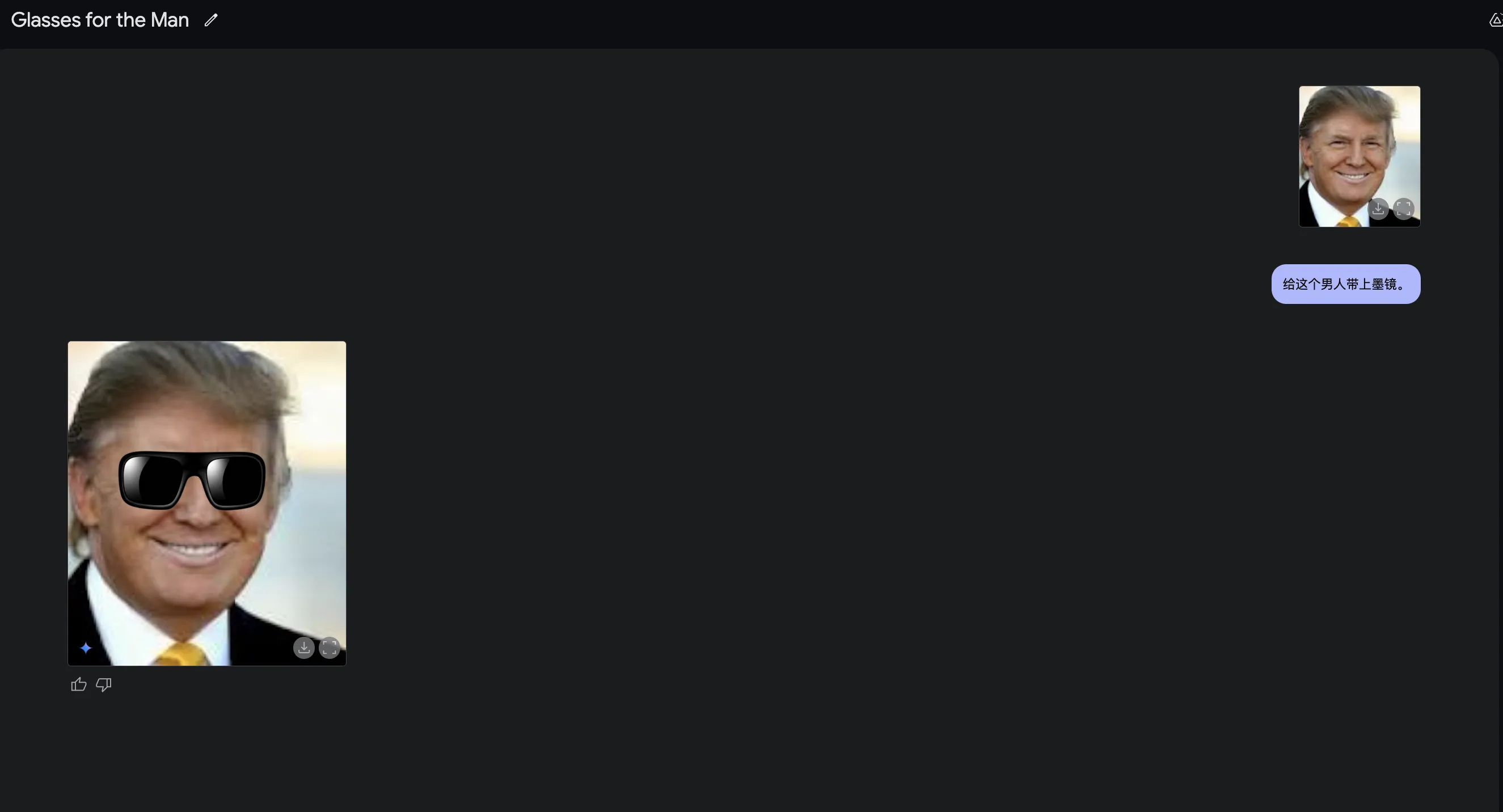
Native Image Output!

Update (2025.3.1)
Gemini video summary gives rough overview. 2.0 Flash is more stable—reasoning models may have issues like Russian output, not auto-calling YouTube extension.
At midnight Beijing time on February 6, 2025, Gemini 2.0 released new updates1.
Gemini App
Gemini 2.0 Flash went live on API. Gemini 2.0 Flash went live in App at midnight Beijing time on January 31, 2025.
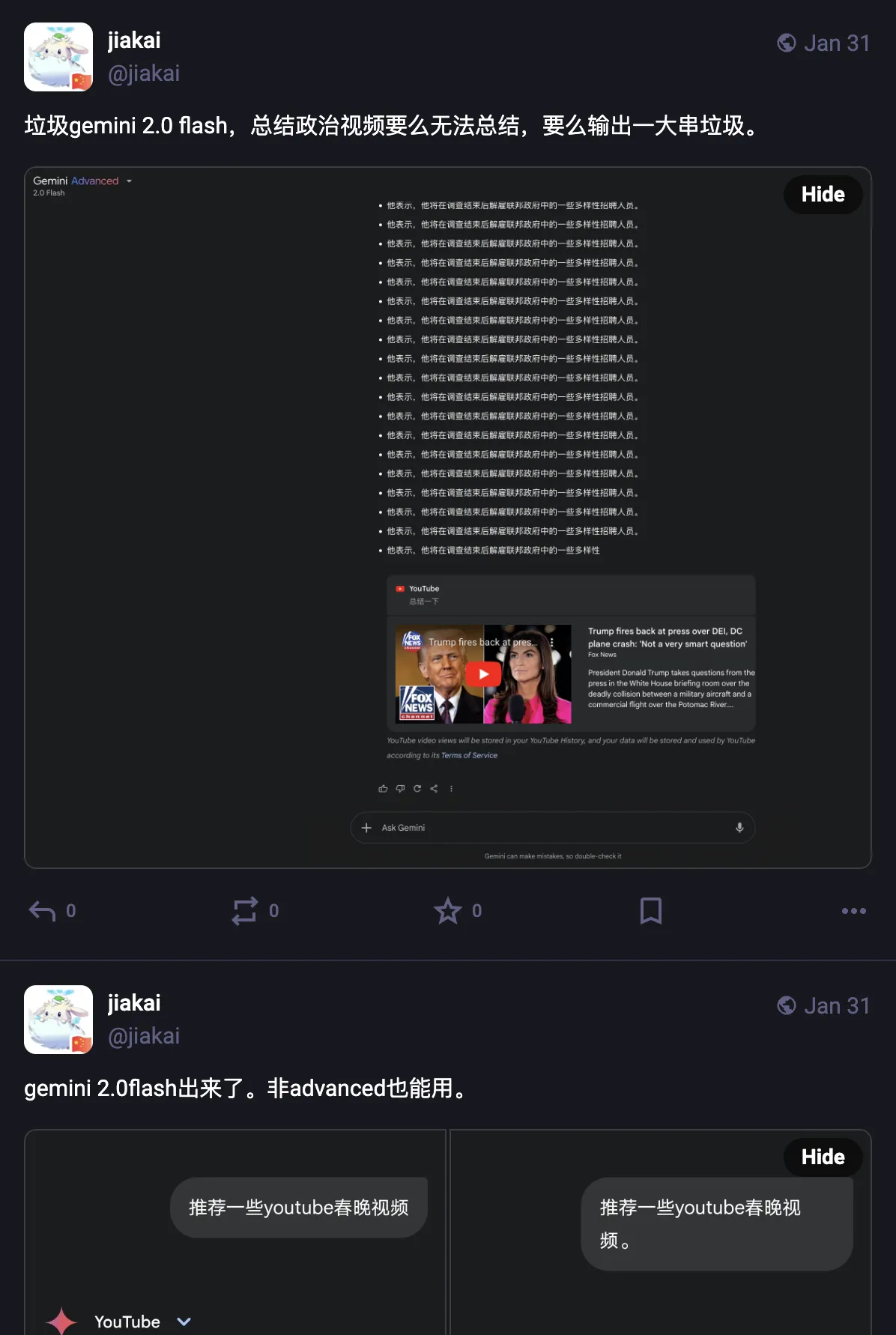
Based on these days’ experience, Gemini 2.0 Flash in App for YouTube video summarization feels like restrictions are increasing—safety is more aggressive now. Of course healthy, non-Trump, subtitled videos can basically be summarized.
With yesterday’s update, for me, the main model for summarizing YouTube videos is no longer 2.0 Flash or 1.5 series—should choose 2.0 Flash Thinking Experimental with apps [reasoning model that can connect to YouTube, Google Maps, Google Search].
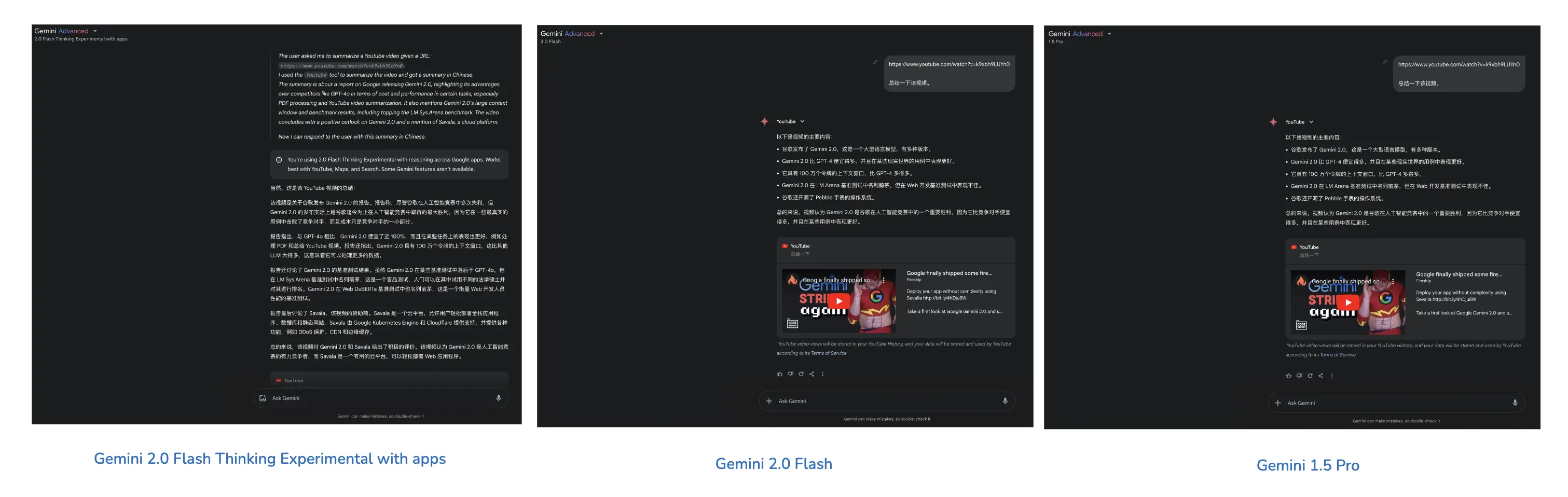
Its video summaries are more detailed. For just getting video overview, can choose Gemini 2.0 Flash or 1.5 Pro.
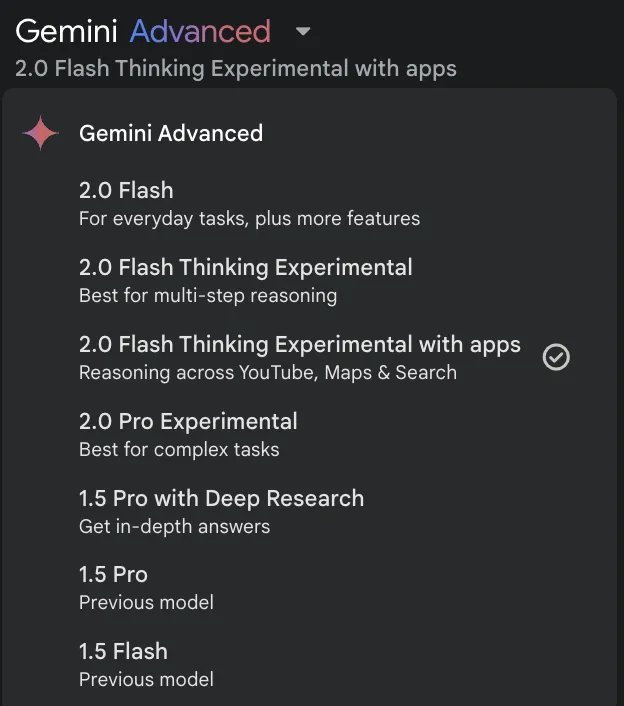
Other App models can be ignored—after all, these models are chat-optimized, losing performance. Using Gemini models without connecting to Google suite services—prioritize freeloading AI Studio models.
Currently Gemini Advanced has 2.0 Pro Experimental, 1.5 Pro with Deep Research, 1.5 Pro over non-members—marginal.
Encourage everyone to use Gemini App to summarize YouTube videos, call Imagen3 text-to-image in Gemini App—free version is enough.
Imagen3 is reportedly strong in drawing and is now on Gemini API2. Paid API generates one image for $0.03, while calling in Gemini App is completely free.
Gemini API
For freeloading in AI Studio, prioritize gemini-2.0-pro-exp-02-05 model.
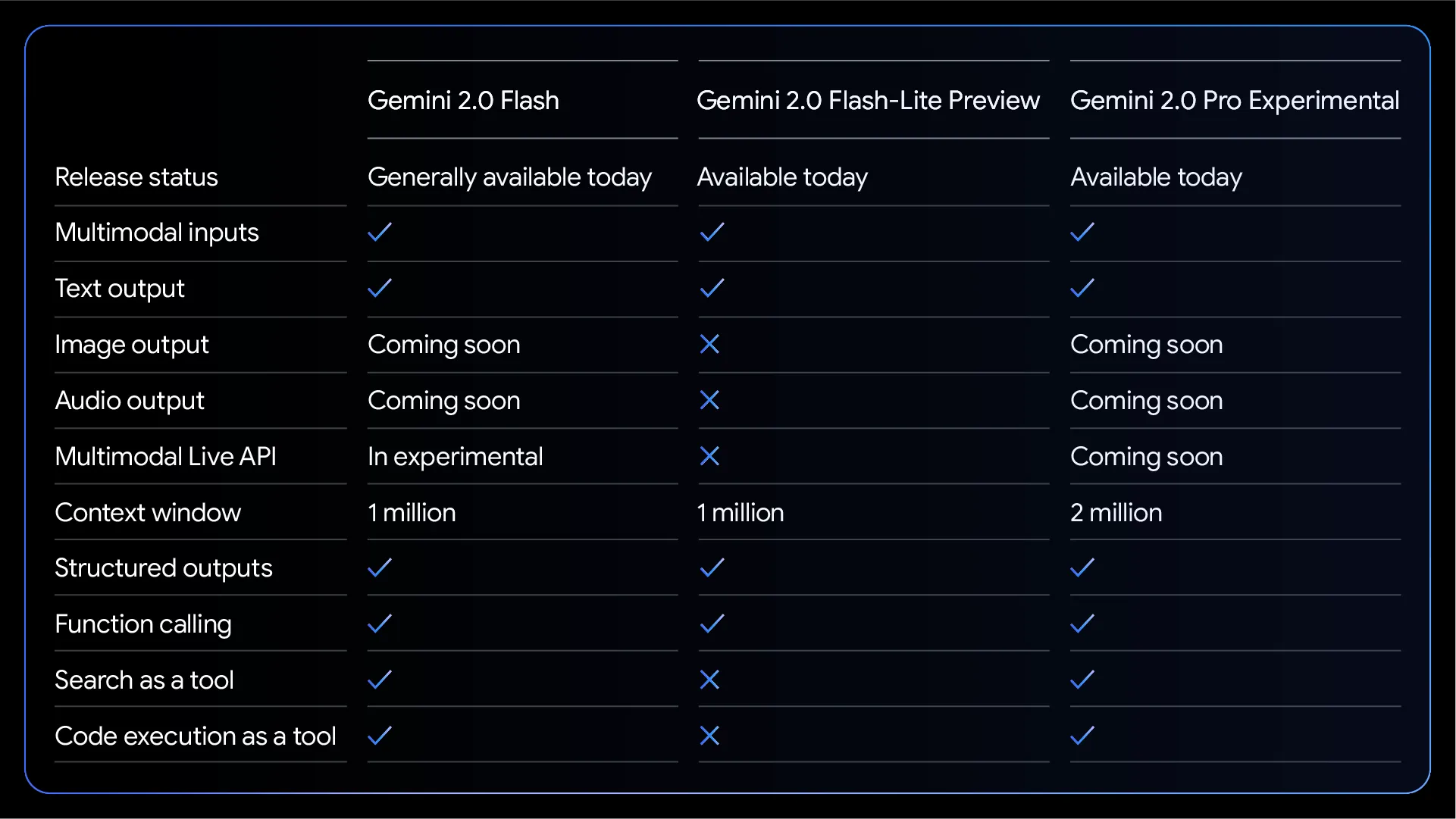
For API work usage [like calling API to batch remove HTML elements from webpages, keeping text], definitely consider Flash series. According to Google’s official blog3, 2.0 Flash series improved performance while keeping original prices. 2.0 Flash removed 1.5 Flash’s tiered pricing. To further reduce costs, consider Gemini 2.0 Flash-Lite model.

Note that Gemini 2.0 Flash-Lite supports multimodal input but only text output.
Leaderboards and Experience
Though leaderboards have some distortion, rankings roughly estimate model capabilities. Prioritize livebench leaderboard—Gemini 2.0 series models aren’t as impressive as imagined. Experimental model evolution brings some capability improvements and some declines—not all capability metrics improved.
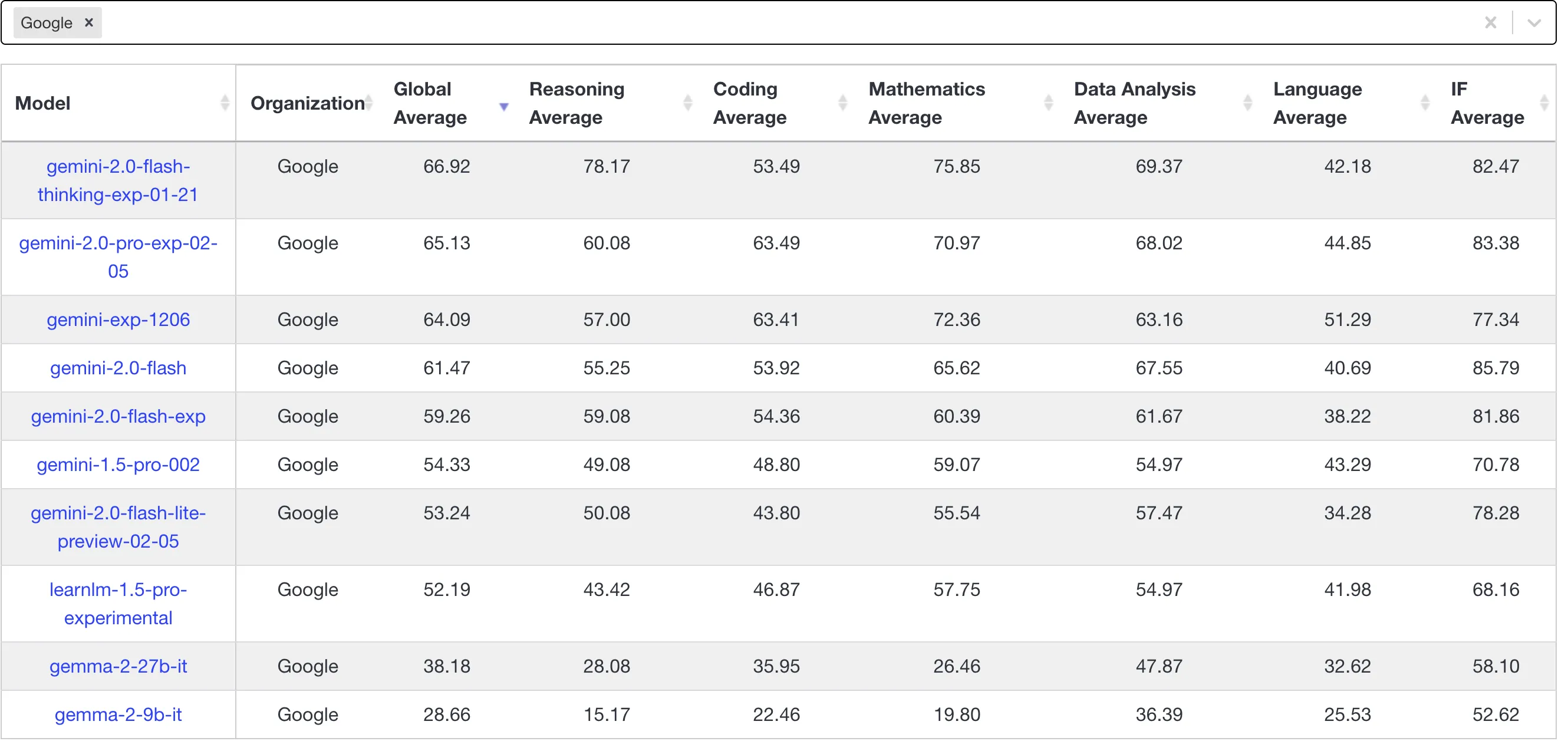
Currently o3-mini-2025-01-31-high reached cliff-leading 80+ in coding, but truly useful in developers’ minds is still claude-3-5-sonnet-20241022. The classic non-reasoning LLM that can surpass Claude—looks like only Claude itself.
Claude excels not just in coding—text abilities are also great. Chatting with it feels more like a real person—its output text has more warmth compared to other LLMs, though sometimes lazy. Setting aside CEO Dario Amodei’s controversial blog posts, Claude is truly amazing!
My daily learning priority is always Claude. Besides Claude Pro, I recently subscribed to Windsurf Pro—Cascade AI agent has good user experience and lower cost than Cursor’s $20/month.
Personal Thoughts
Gemini series models, my use cases:
- App summarizing YouTube videos
Gemini App for me is mainly summarizing YouTube videos. Unless video is compelling enough or hands-on type, I prefer using Gemini to summarize and save time.
- Flash series in production
Processing data in production—use Flash models for best cost-effectiveness. Recently saw a blog post “Ingesting Millions of PDFs and why Gemini 2.0 Changes Everything”4 5—author notes Gemini 2.0 Flash excels in cost-effectiveness, OCR accuracy is near-perfect and cheap.
- Using Flash model to summarize web articles in Glarity Chrome extension
Daily Page Summary usage is 10-20 times. Monthly cost is very low—January 2025 Gemini API GCP bill was $0.06.

Though many free webpage summarizing extensions exist, I still prefer Gemini Flash series—after all, large context window and low cost.
- …
Gemini claims large context window. Using Gemini this long, I’ve never had a conversation exceed the window—can’t comment on this. Large context window theoretically benefits RAG, but actually larger window isn’t always better—more content means more noise.
Gemini models have strong visual ability. Last semester I used Gemini to extract Chinese characters from news images. An image crammed with multiple news items—Gemini recognized almost all Chinese characters. Multimodal ability is indeed strong.
When Project Astro officially launches, expect more surprises.
Summary
Gemini models currently have merits. Compare with other models regularly to better discover strengths and weaknesses. Google series’ strength is excellent integration with its suite—ecosystem is uniquely Gemini’s.
Gemini is definitely an underrated model. Don’t ignore its gradual improvement in 2024, 2025 because of Google Bard’s struggles in 2023. Renaming from Bard to Gemini was a successful rebrand attempting to shed Bard’s negative image—Gemini series updates have indeed proven Google’s strength.
Facing DeepSeek’s current explosion, you might ask—don’t you use DeepSeek daily?
Personally I think DeepSeek has substance, but doesn’t mean it’s invincible, completely achieving East rising West falling! Can only say open-source approaching closed-source6. For example, DeepSeek currently lacks multimodal—real-time voice lags behind Doubao and other models.

Plus DeepSeek’s recent explosion overloaded its service. If just calling R1 API, feels lacking. R1+search achieves best DeepSeek experience. Will add to my daily LLM options after DeepSeek service stabilizes—otherwise asking one question then getting server busy really affects experience.
-
https://blog.google/technology/google-deepmind/gemini-model-updates-february-2025/ ↩︎
-
https://developers.googleblog.com/en/imagen-3-arrives-in-the-gemini-api/ ↩︎
-
https://developers.googleblog.com/en/gemini-2-family-expands/ ↩︎
-
https://www.linkedin.com/posts/yann-lecun_to-people-who-see-the-performance-of-deepseek-activity-7288591087751884800-I3sN ↩︎
Document Info
- License: Free to share - Non-commercial - No derivatives - Attribution required (CC BY-NC-ND 4.0)