ChatGPT o3, o4 mini Experience
Update (2025.4.29)
Personally I feel ChatGPT 4o model has improved a lot compared to last year. Recently saw an L Site post—Is 4o’s sycophantic style GPT dumbing down—can’t help but think for newbie users, 4o’s sycophantic style is indeed friendly.
Currently for some daily questions (not involving programming, writing), I’m leaning toward ChatGPT 4o. Comparing today’s Qwen3 release—Qwen3 benefits open-source which is commendable, but for daily topics, I personally think it’s slightly inferior to closed-source models. [Though one example below isn’t enough to show the gap]
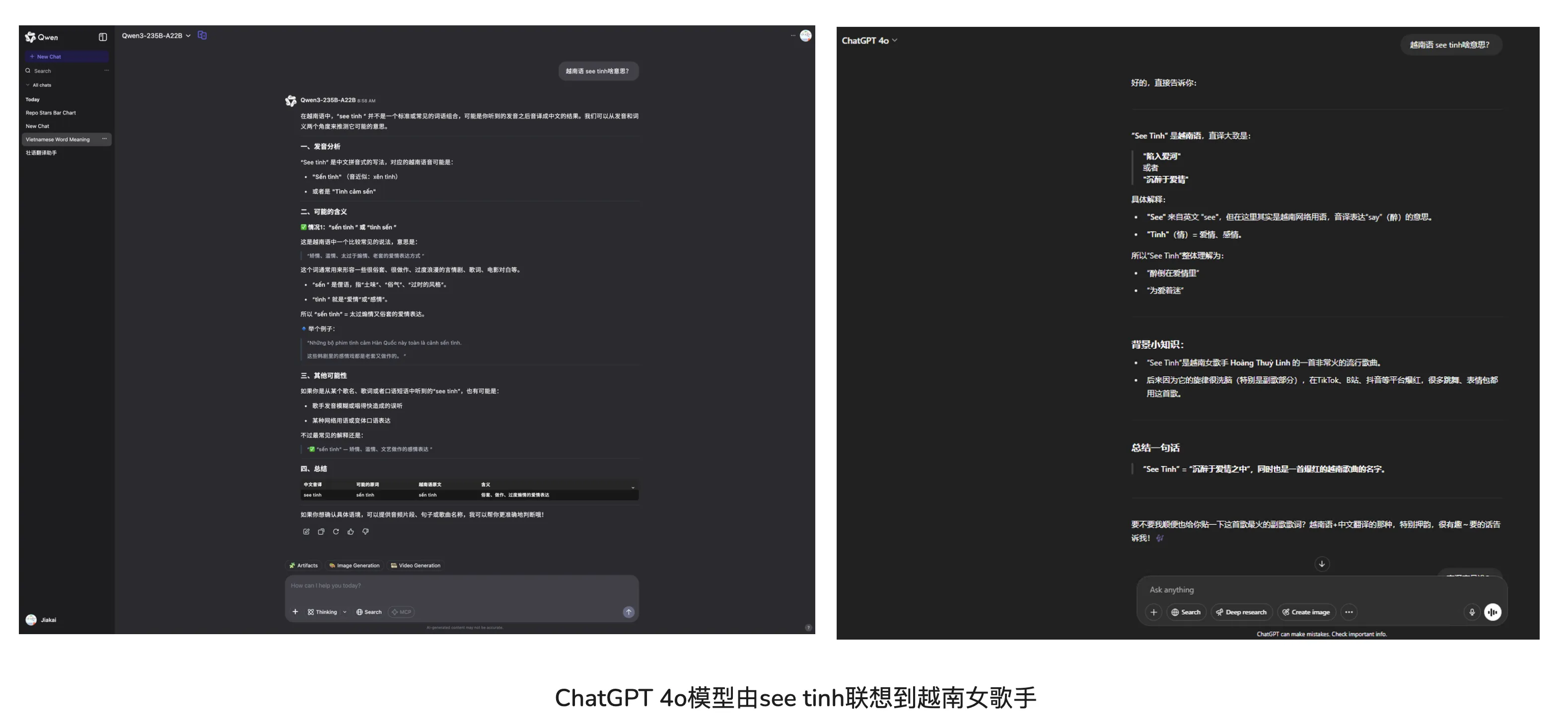
Nobody rejects a sycophant [as long as they catch your eye]. I definitely won’t reject Doubao’s sweet girl voice or ChatGPT 4o’s sycophantic style. 😁

“OpenAI though Closed is always at the top of the entire industry”—this statement makes so much sense! Non-dumbed-down OpenAI has unbeatable experience in all aspects. via: https://linux.do/t/topic/602275/
Update (2025.4.26)
Today ChatGPT 4o on official site updated again. via: https://x.com/sama/status/1915902652703248679
After using official site 4o a few times, for technical questions, ChatGPT 4o now prioritizes English internet search. This is good. Previously Chinese questions searched Chinese internet.
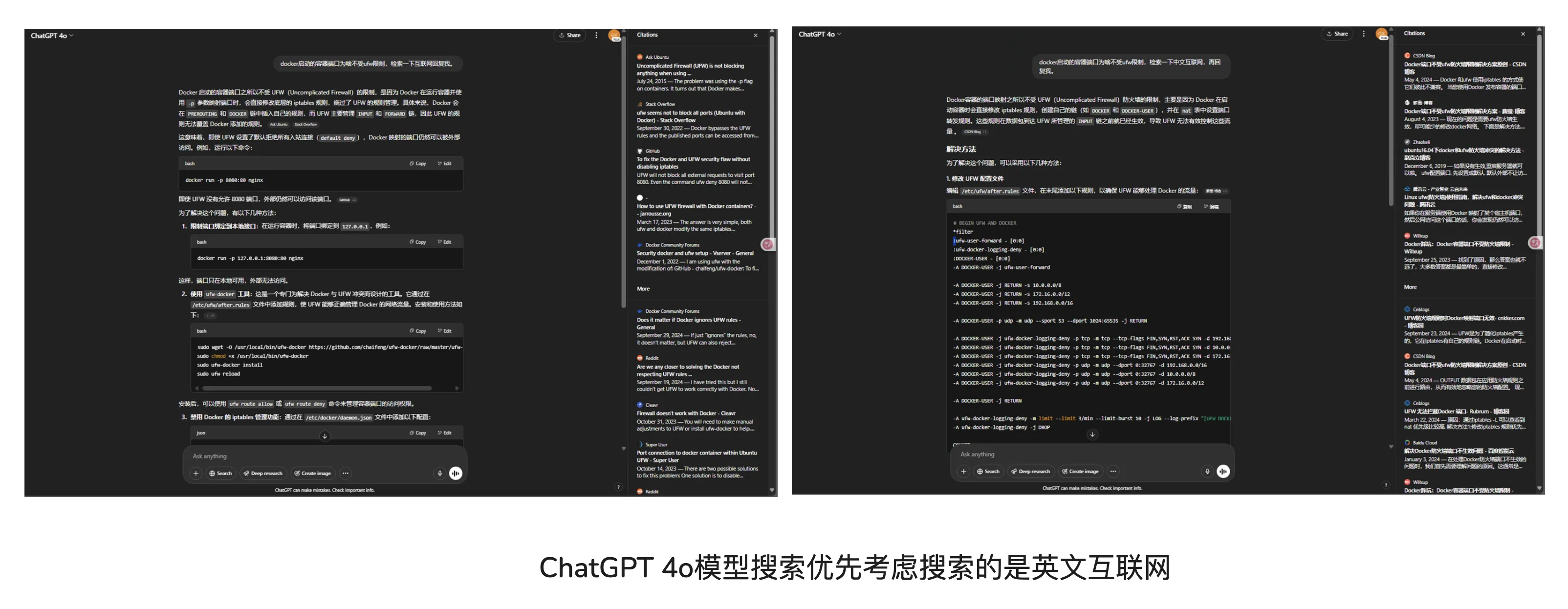
Recently I increasingly feel products like Perplexity will die in the future. Since o3, o4-mini series models came out, my Perplexity usage dropped sharply.
Update (2025.4.24)
ChatGPT Plus users’ o3, o4-mini-high quota doubled. o3: 100/week; o4-mini-high: 100/day.
Update (2025.4.20)
Can’t completely embrace Claude either. Currently ChatGPT’s latest o3, o4-mini series full-auto agent LLM calling various tools for debugging is really comfortable. Code comments might not match original o3-mini-high, but everything else is far ahead. Previously for internet debugging I might use Perplexity etc. for assistance. With latest o3, o4-mini-high—full-auto debugging, Chinese programming questions, English internet search, until task complete.
For example, this morning while learning I encountered a bug. Asked various LLMs—only ChatGPT’s full-auto agent successfully solved it. Other LLMs I didn’t even want to follow up—initial answers were problematic. Plus solving this bug needed searching latest knowledge—way more effort than ChatGPT’s full-auto agent.
I can only say current LLMs are truly dazzling. Sometimes don’t know which model to use. Because I personally have strong Claude inertia, yesterday I wrote Claude praise, but recent Gemini 2.5 Pro, ChatGPT o3, o4-mini series updates are also really top—all SOTA. Having choice paralysis.
Update (2025.4.19)
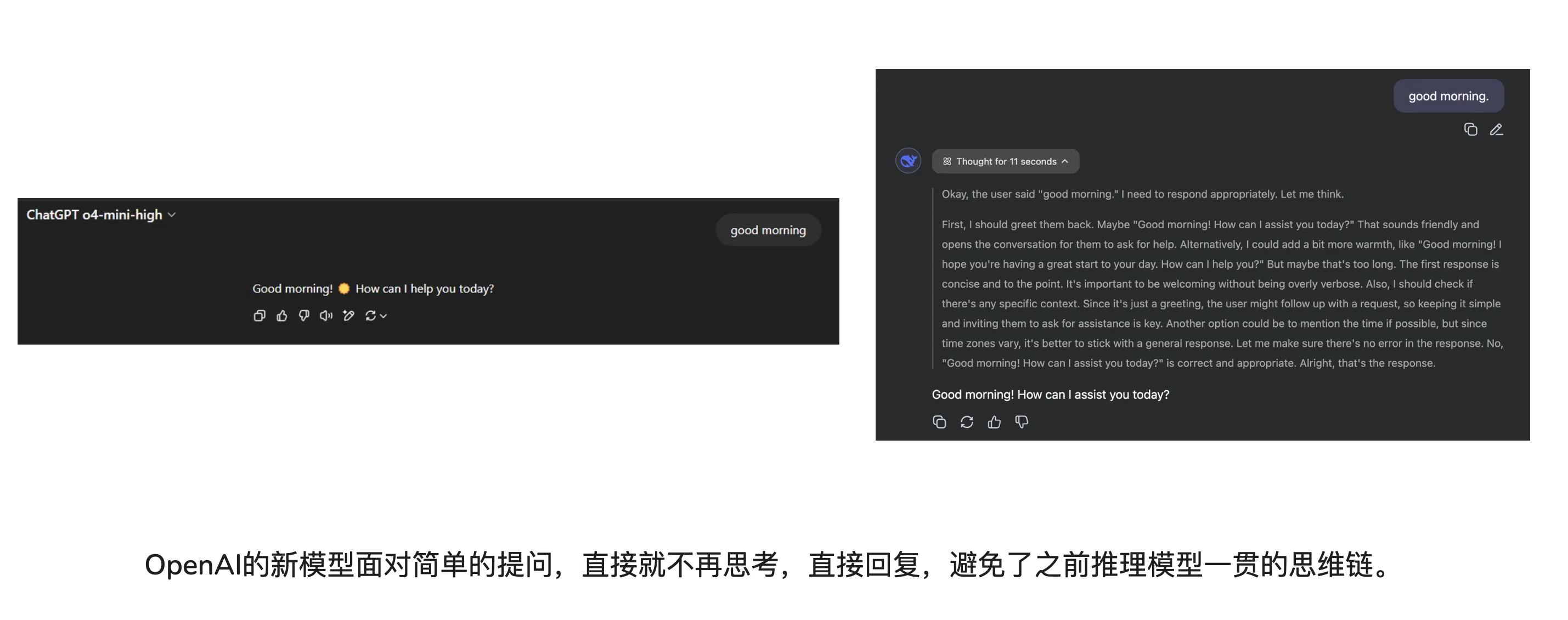
Recently o3 guessing image locations went viral. But besides image guessing, the rest feels below expectations. Like code comments—I somewhat miss o3-mini-high. Current tool-using o3 or o4-mini-high has insufficient thinking time—code comment quality worse than original o3-mini-high.
Whenever I learn new knowledge, I still first consider Claude. Gemini 2.5 Pro can’t achieve Claude’s rich yet not overly verbose communication experience. Claude sometimes has excellent generalization (so-called soul)—incisive replies to questions feel surprising yet unexpected. Though I compare all current LLMs, overall after getting used to Claude’s reply style, so far no LLM catches my eye. No matter how Gemini 2.5 Pro, o3, o4-mini-high dominate benchmarks, my heart always belongs to Claude.

Update (2025.4.18)
- Context decay resistance
o3’s powerful context decay resistance surpasses Gemini 2.5 Pro. Still the big brother OpenAI—far ahead. Pro users with unlimited o3 probably won’t even glance at o4-mini-high. In a few weeks o3-pro comes out.
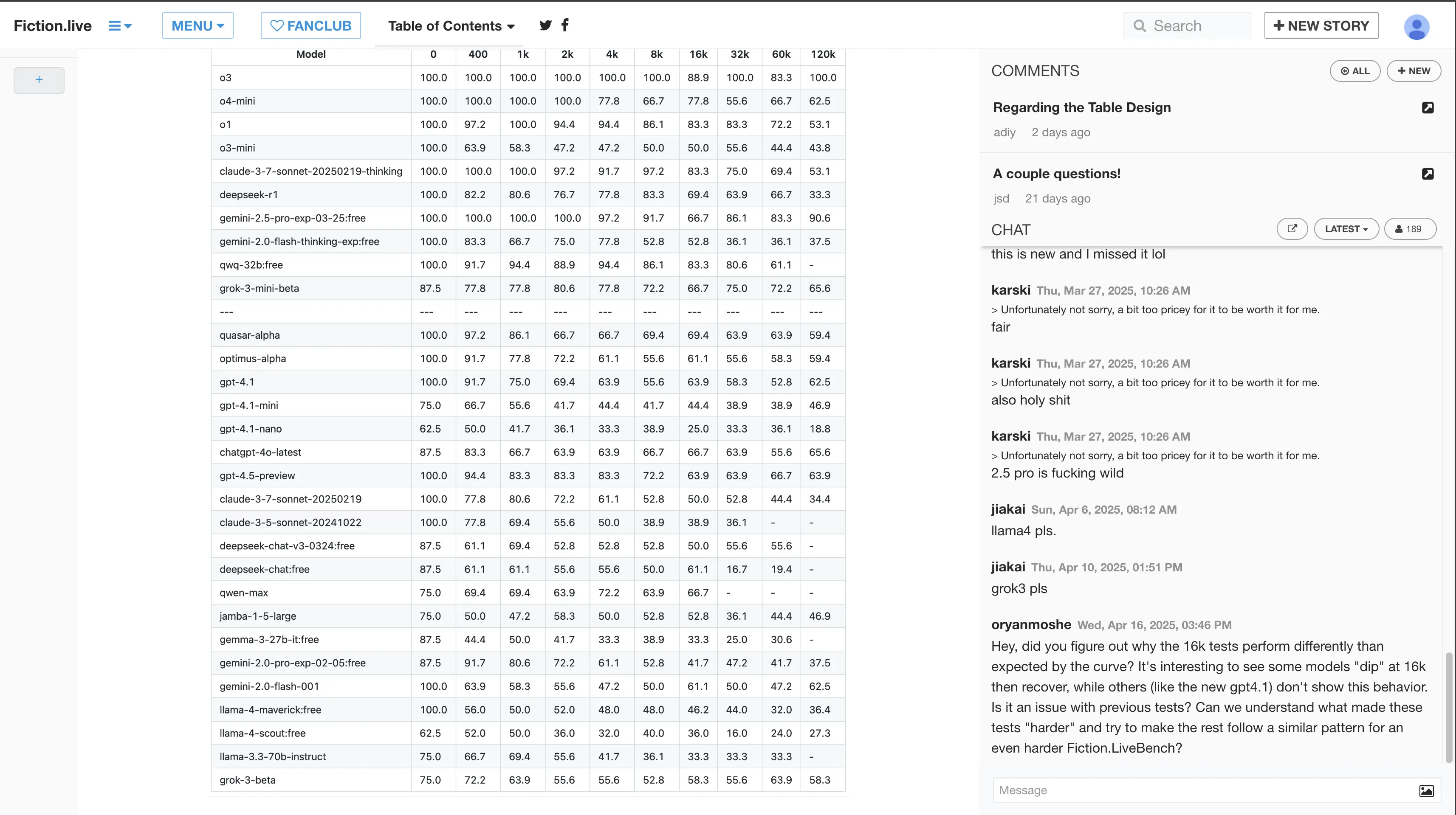
via: Fiction.liveBench April 17 2025
- Daily usage choice
For not-too-complex questions, prioritize o4-mini-high—after all, Plus users have limited weekly o3 quota. Personally, agent mode o-series has excellent user experience.
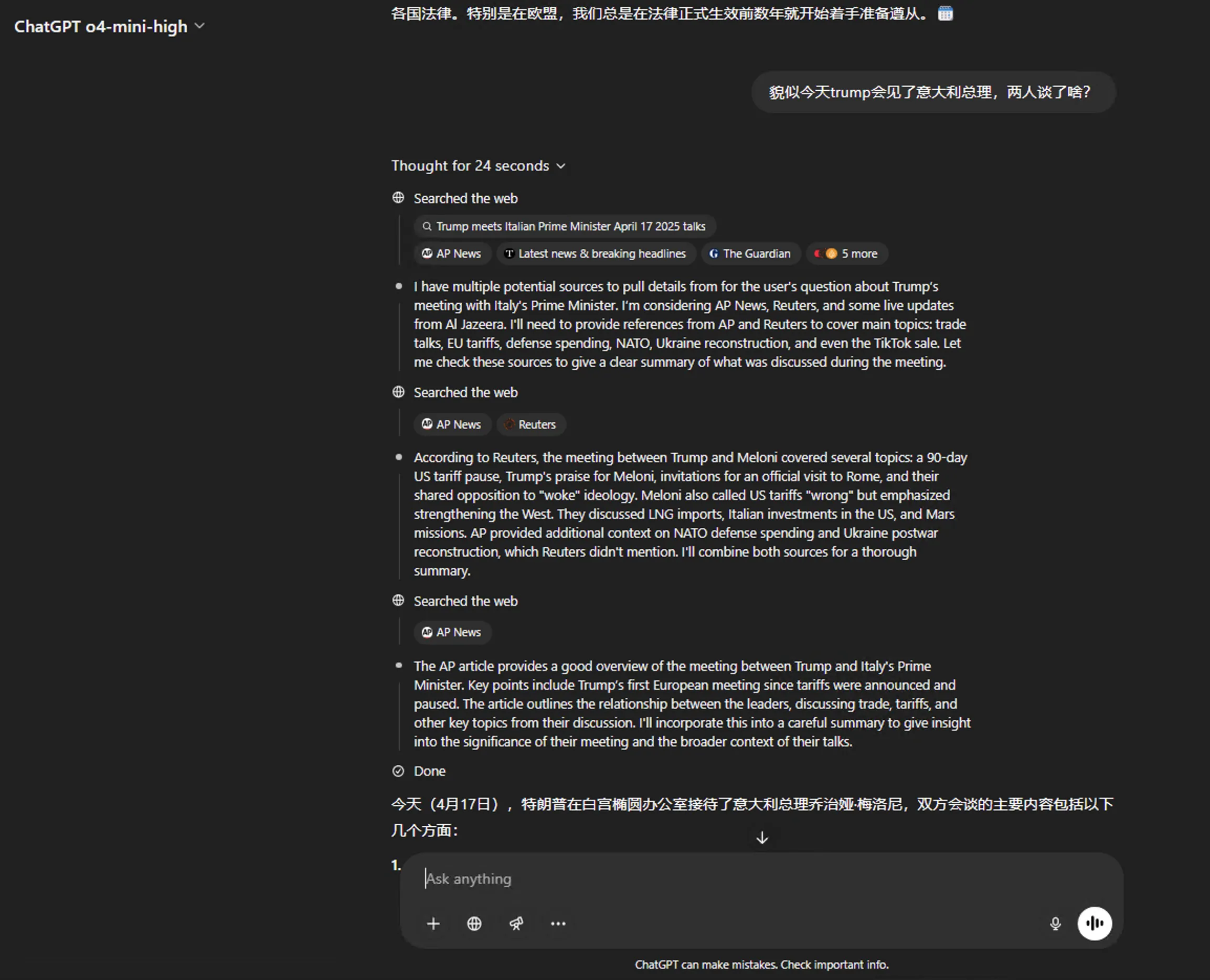
Update (2025.4.17)
Adding some good review content I’ve seen.
Update Summary
- Usage limits
ChatGPT Plus users: o3 limit 50/week; o4-mini limit 150/day; o4-mini-high 50/day; 32K context window.
via:
https://openai.com/chatgpt/pricing/
Don’t recommend free users use ChatGPT. Without paying, experience is definitely terrible—only 8K context window, and only lower-tier models available.
In OpenAI’s rules, Pro users are gods, Plus users are commoners, free users are beggars.
Also don’t recommend friends with obvious proxy characteristics to use ChatGPT—dumbing down is real. Suggest remote Windows desktop/self-hosted KasmWorkspaces methods [prerequisite: remote VPS IP should be clean, otherwise still dumbed down] to access ChatGPT.
- Reasoning model becomes agent, combining every ChatGPT tool (web search, Python interpreter, image analysis, file interpretation, image generation), can do visual reasoning [multimodal reasoning]
Image below shows part of image recognition task—feel ChatGPT o3 model’s terrifying iteration capability.
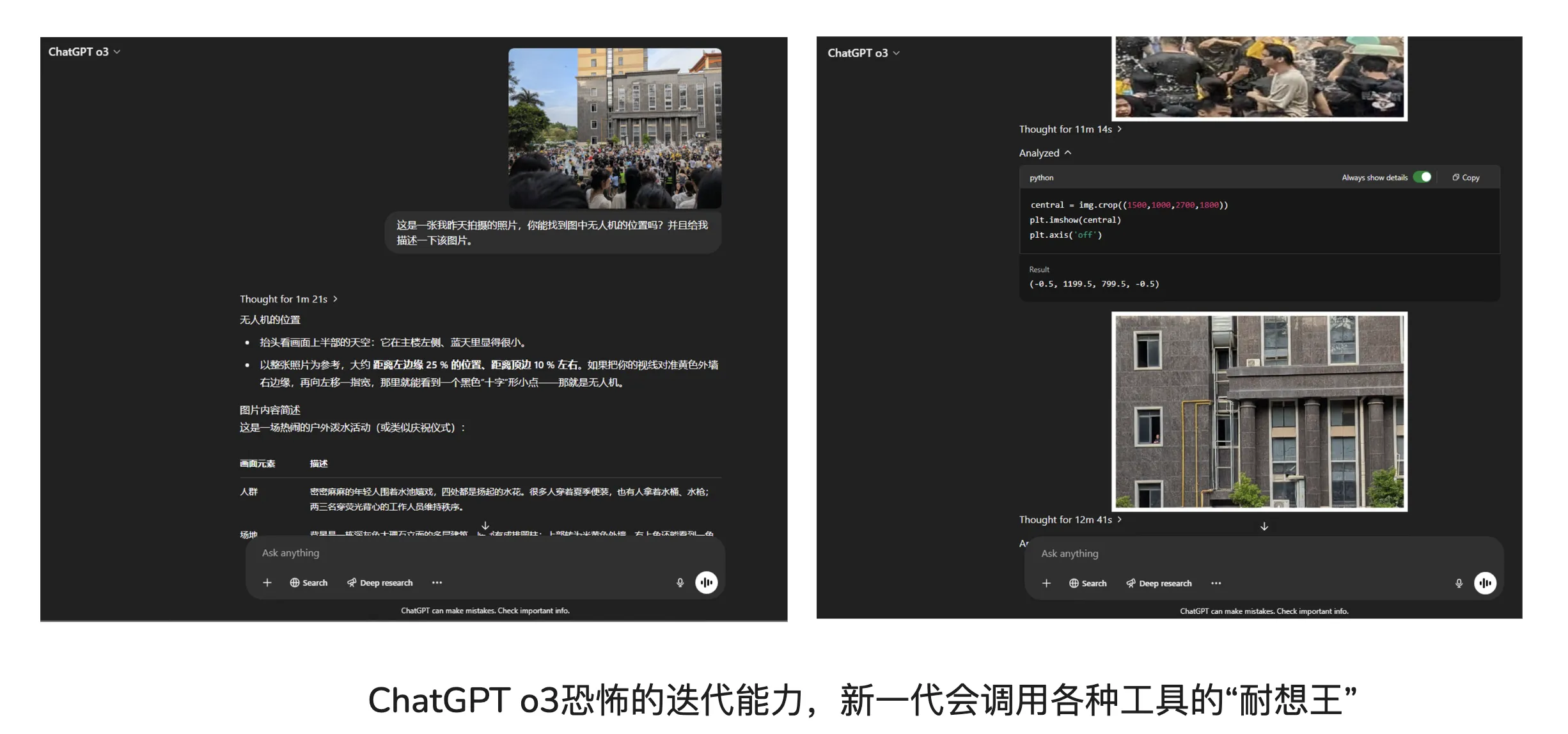
This image recognition task flow—see this task’s webpage screenshot:
- 1m21s reasoning time
Find drone in image.
- 44s reasoning time
Initial guess of possible photo locations [guess list already contained correct answer, unfortunately bet on one—most likely guess was wrong.]
- 2min59s, 4min41s, 11min14s, 12min41s, 13min56s reasoning time
In these parts, o3 uses internet tools to guess possible locations, but possibly hit reasoning time or context limit, causing truncation—only outputting to=.
Couldn’t watch o3 deviate from correct answer, going further in wrong direction. I revealed some hints—like initial guess list has correct answer.
- 6min51s, 11min45s, 13min51s reasoning time
I saw o3 flip-flopping between correct and wrong answers, falling into same predicament—only outputting to=. Continued revealing hints—don’t fixate on one area’s universities, don’t limit to library-type buildings.
- 7min14s, 9min31s, 11min58s reasoning time
o3 again interrupted. I continued prompting—combine above analysis, give most likely location.
- 10s reasoning time
o3 successfully guessed the location, but small location was wrong.
- 11min56s reasoning time
o3 with search successfully guessed small location, but response contained wrong info.
- Finally I asked o3 to convert original image to Ghibli style
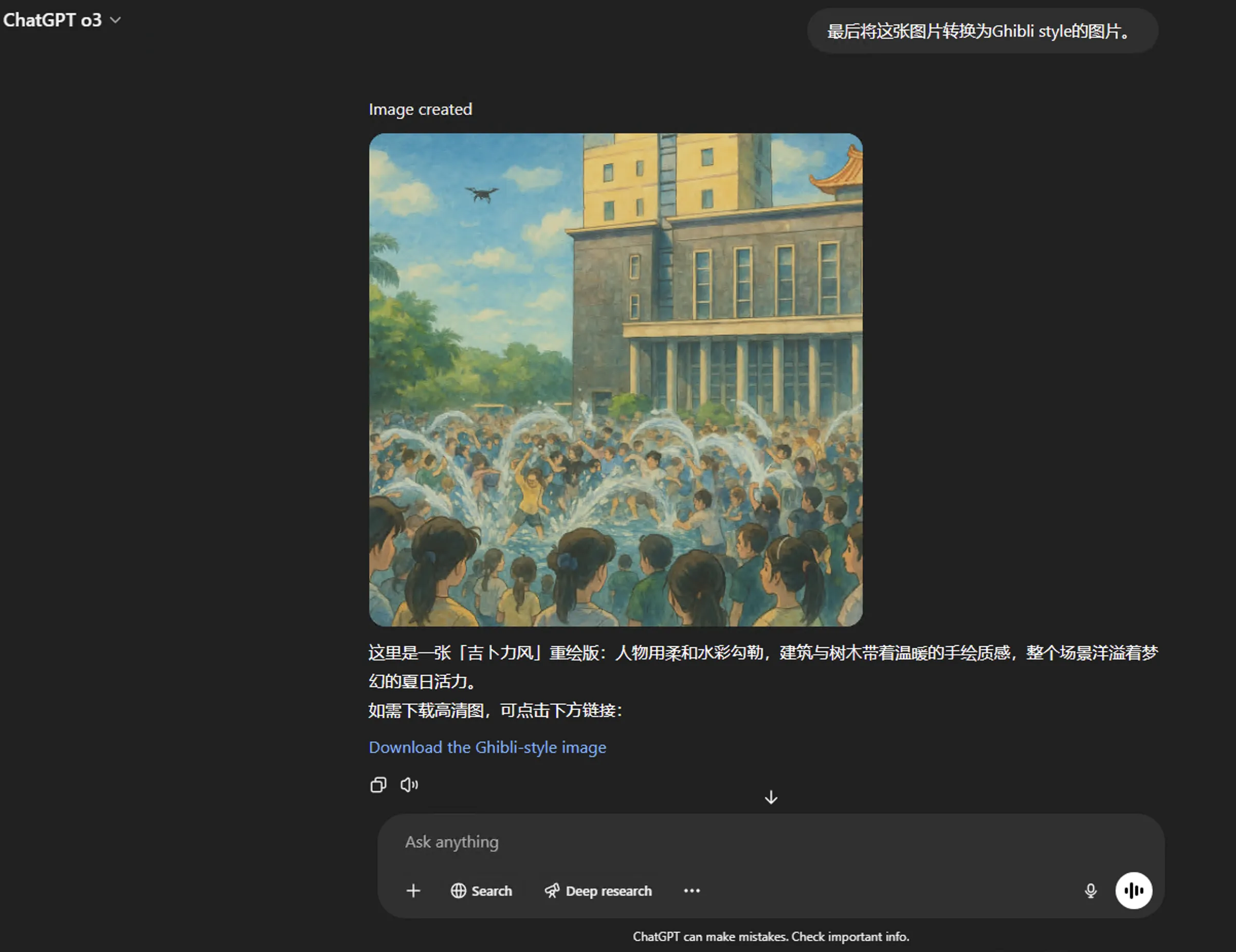
Looking back—this is truly a cheesy strategy, but also how agents should be—using external tools to iterate until task complete.
First time experiencing LLM reasoning over 10 minutes. ChatGPT really tries hard.
- Daily usage: choose o3 or o4-mini-high?
From OpenAI’s benchmarks, except these three (first two test math competitions, third is algorithm programming competition) where o4-mini-high leads o3, the rest o3 wins.
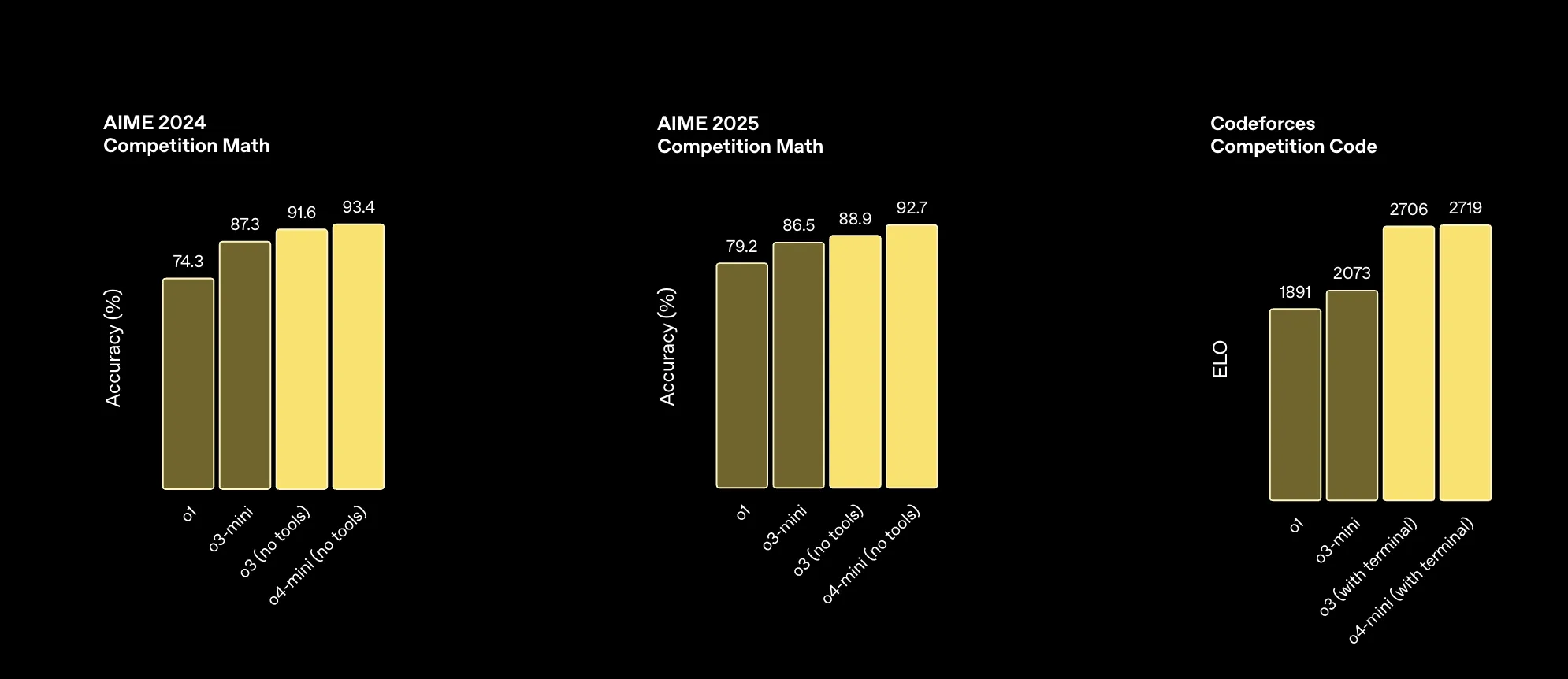
OpenAI employee recommends o4-mini-high over o3 for visual tasks. via: https://simonwillison.net/2025/Apr/16/james-betker/

Though benchmarks have biases, they roughly show LLM general capabilities. OpenAI’s new models dominate livebench.ai—reasoning models are indeed benchmark kings.
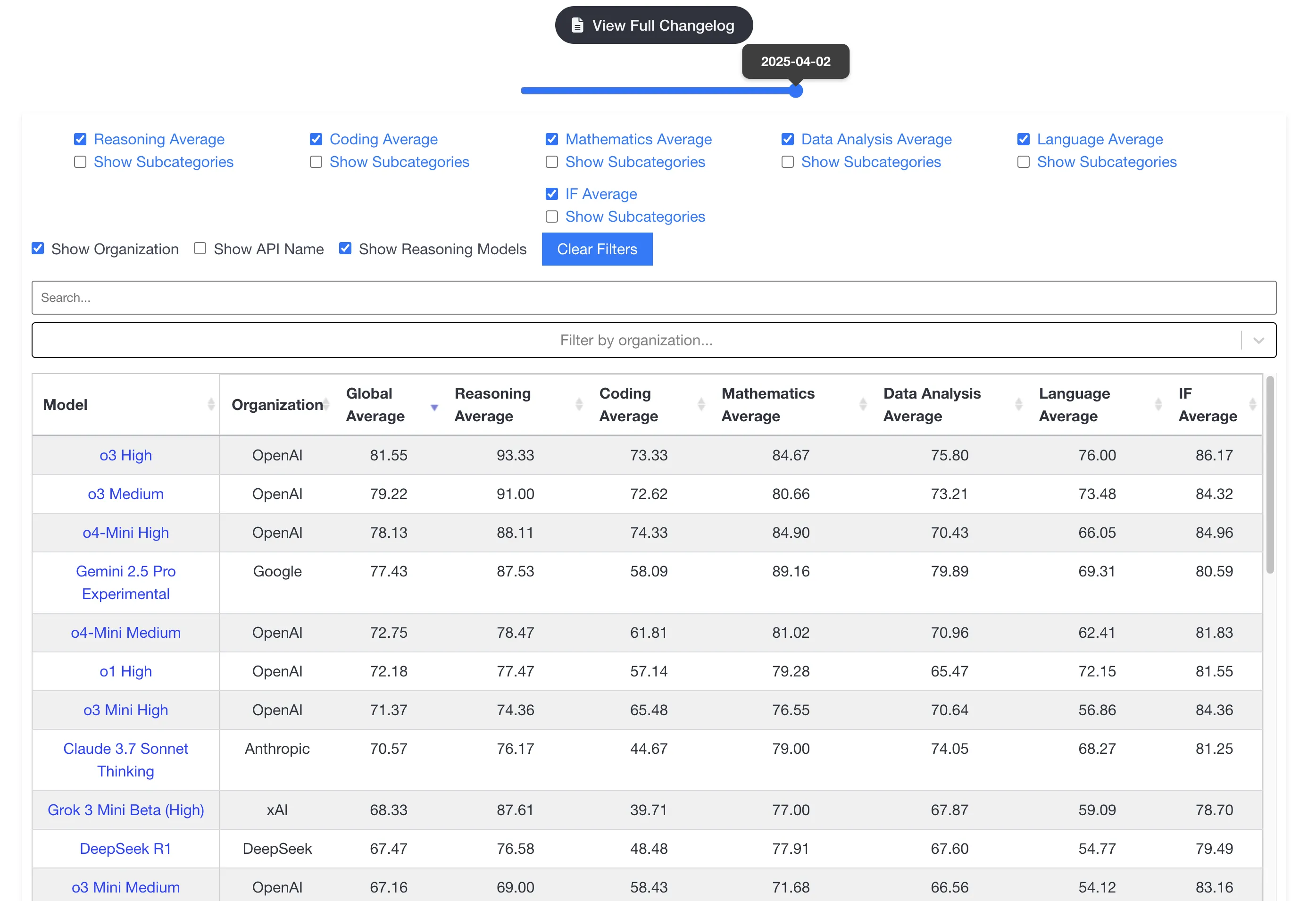
Plus users have 50/week o3 quota—use it. After exhausting o3, use o4-mini-high.
- New models’ search: Chinese questions no longer limited to Chinese internet
After Chinese questions, OpenAI’s new o3, o4-mini series directly search internet with English and Chinese versions of the question. GPT-4o still follows Chinese questions, Chinese internet search.
Reinforcement learning training models to use tools is truly impressive—not just teaching how to use tools, but reasoning when to use them.

- Codex
Similar to Claude Code. I tried applying for open-source funding—if they give me some API quota, I’ll try. Not considering for now. Foreigners think OpenAI finally gets it—starting to learn from Anthropic developing models for real needs.
- Other discoveries
- OpenAI’s new models are token efficient (use as few tokens as possible for same or better information expression and reasoning).
I think this is the future trend for reasoning models. Current OpenAI new models already feel like reasoning models + classic LLM combined.
- Gemini 2.5 Pro remains cost-effectiveness king.
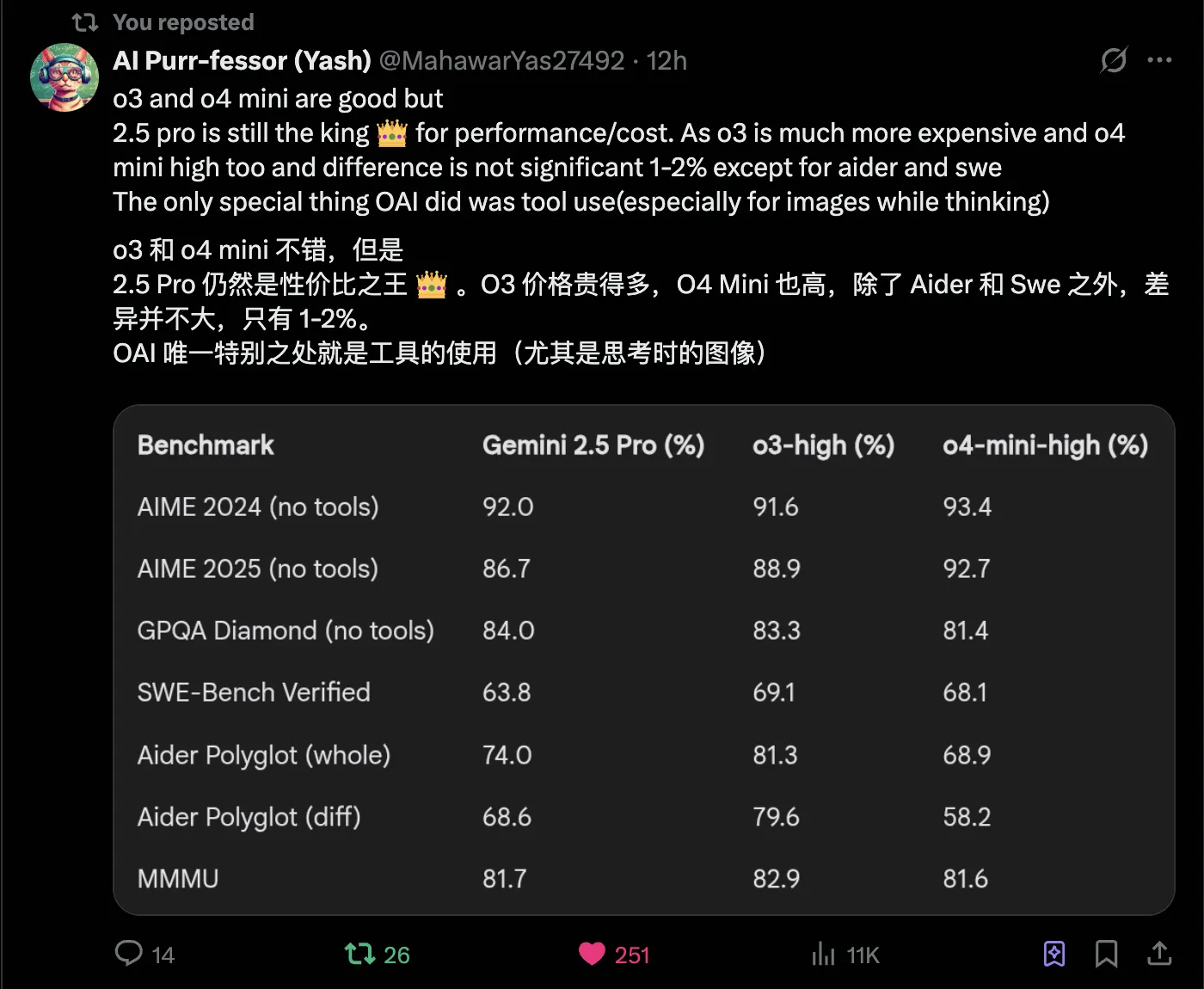
via: https://x.com/MahawarYas27492/status/1912577363554214214
Comparing aider leaderboard top spending shows Gemini 2.5 Pro is truly cost-effective. DeepSeek V3 March update is also cost-effective but capability-wise inferior to Gemini 2.5 Pro.
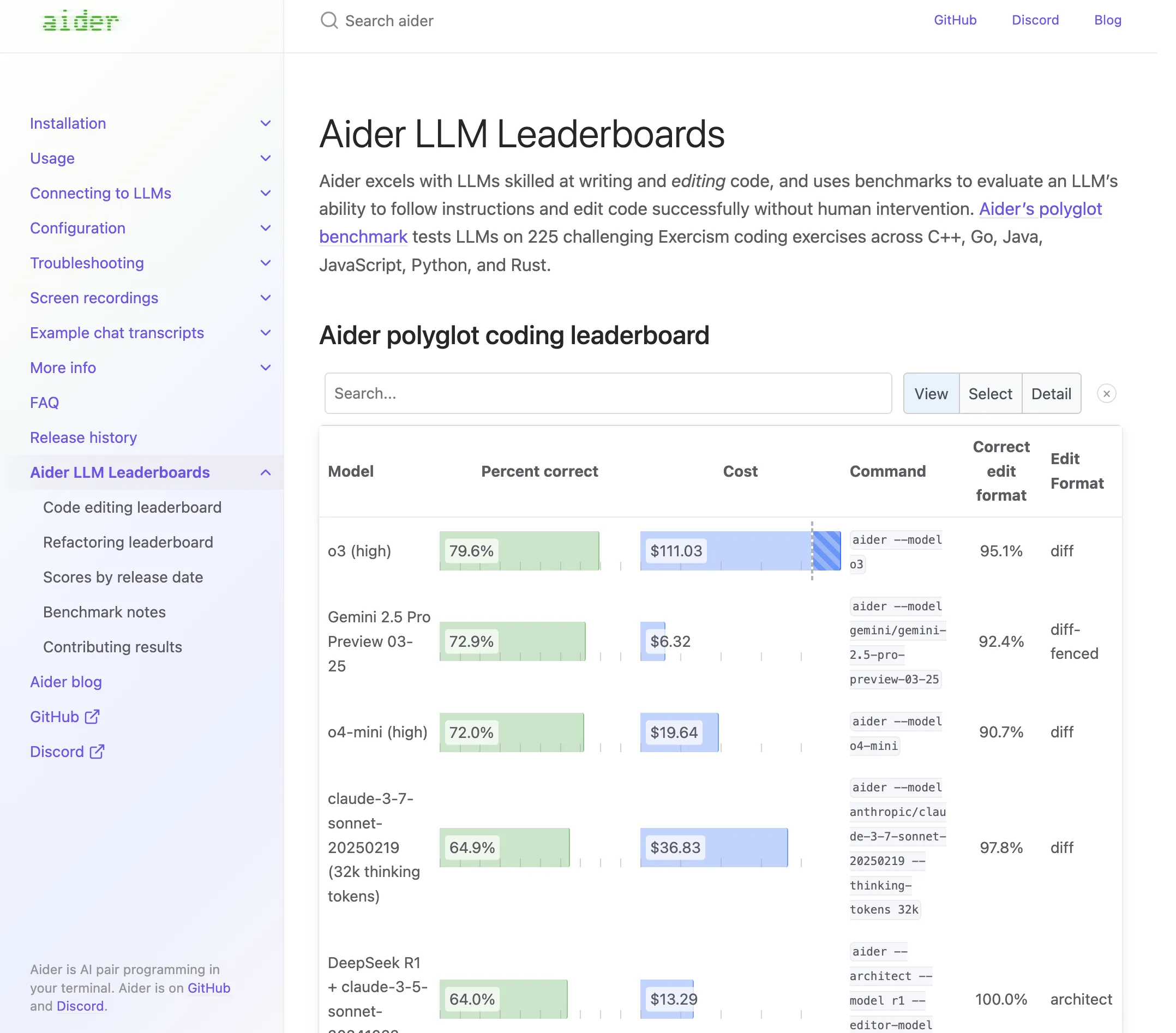
via: https://x.com/bongrandp/status/1912568582426198301
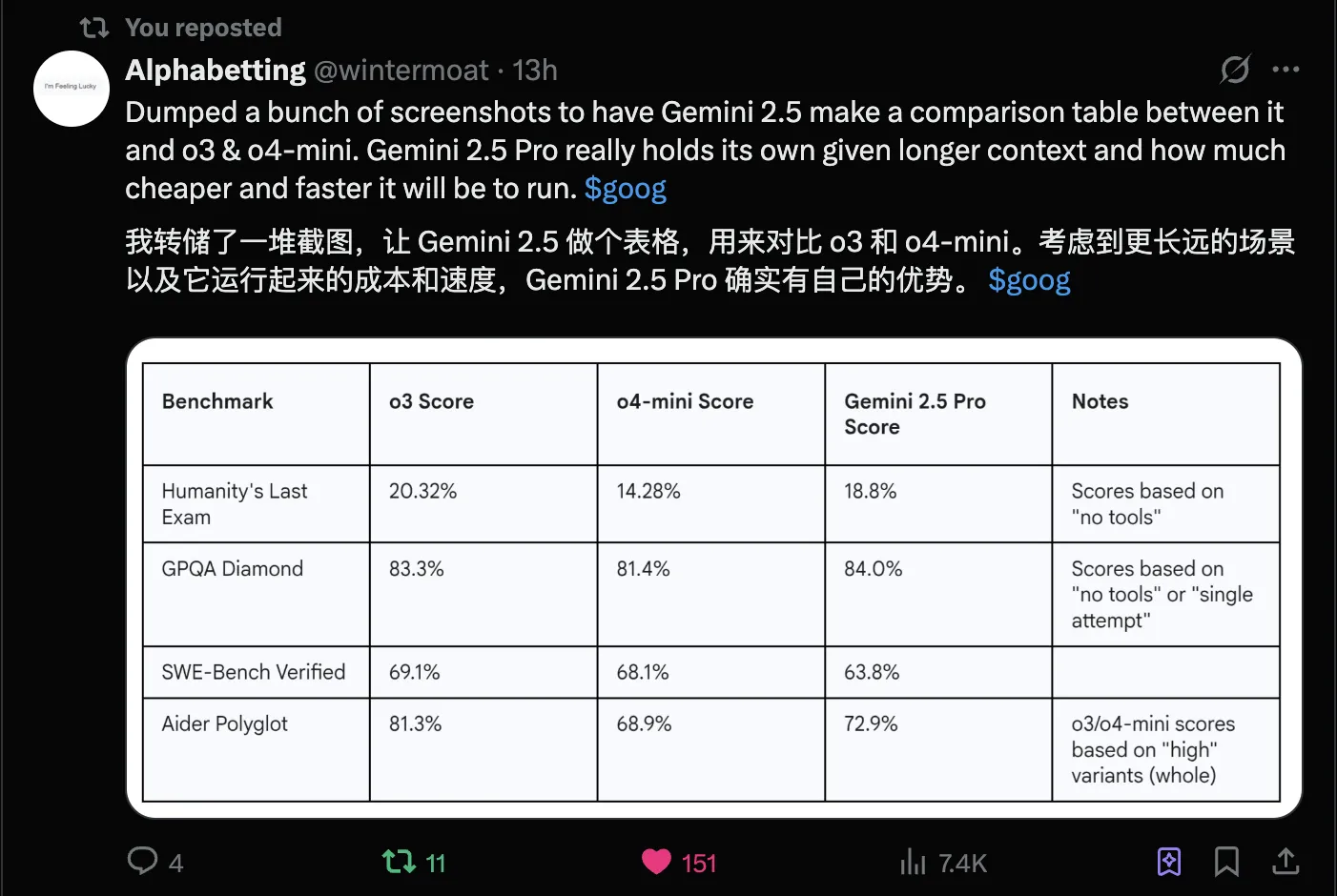
via: https://x.com/wintermoat/status/1912560505161400781
Summary
OpenAI new models’ main highlights are tool calling and multimodal reasoning.
This time OpenAI’s blog benchmarks only listed their own models. Is this arrogance—OpenAI thinks their models are strongest? Or not daring to compare with other advanced models, fearing their massive users learn about other advanced LLMs? Only OpenAI knows.
But this release is much better than before. GPT-4.5, GPT-4.1 releases in today’s rapid iteration barely make waves. Only releases like GPT-4o native text-to-image, o3, o4-mini series are the right path.
Can say OpenAI Is Back! Though I hope to see open-source LLMs closer to closed-source, currently closed-source LLMs again widen the gap.
Looking forward to Qwen3, DeepSeek R2 performing better soon.
One more thing—OpenAI still releases reasoning models. Friends who like non-reasoning models—still don’t underestimate Claude 3.7 Sonnet Without Thinking!!!!!
Other
Attaching some other bloggers’ reviews
References
Document Info
- License: Free to share - Non-commercial - No derivatives - Attribution required (CC BY-NC-ND 4.0)