Feed43的继承者—Rsseverything制作RSS源教学
故事背景
好几天没打开inoreader了,趁着今天周五刷feed,结果发现了reddit上rss社区的这条帖子。feed43的网站挂掉了。
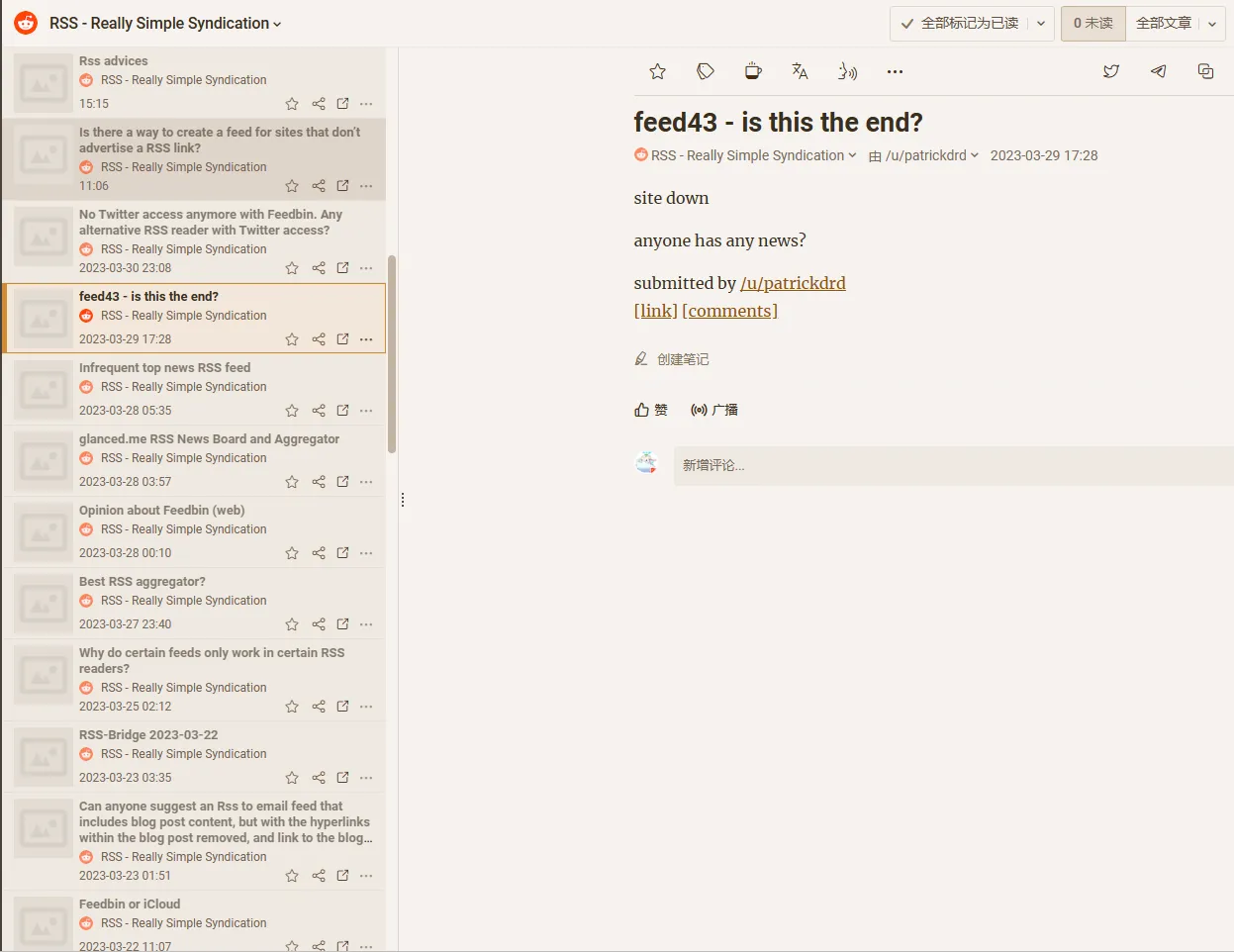
评论区网友的高赞评论,表明目前feed43仍然可以通过ip地址来访问,与此同时也给出了feed43的代替服务—RssEverything。
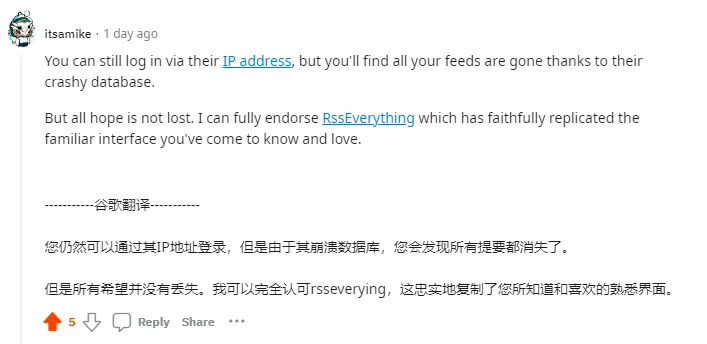
RssEverything这个服务是在2022年年度作者在reddit上发布的。感谢这位作者创造出了人们想要的产品。
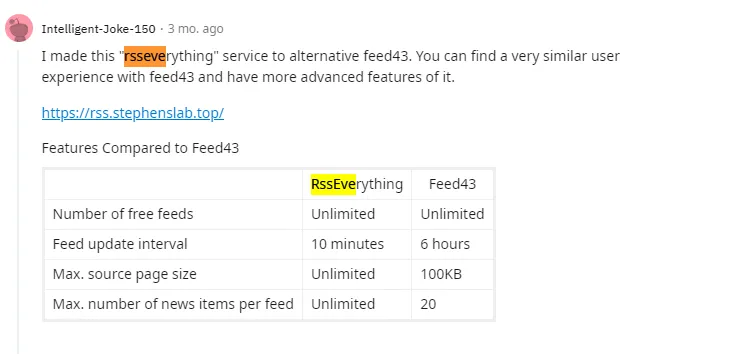
feed43的服务,自从去年https的ssl证书到期后,我就再也没用过,我知道这项服务岌岌可危。没有人知道feed43服务的作者到底发生了什么。下面两条去年reddit的帖子是关于feed43服务的讨论。
写这篇文章之前,我拿RssEverything制作了自己个人站点的rss源。制作的流程和feed43简直一摸一样。具体的语法为{%}和{*}
详细解释请看chatgpt4的解释:
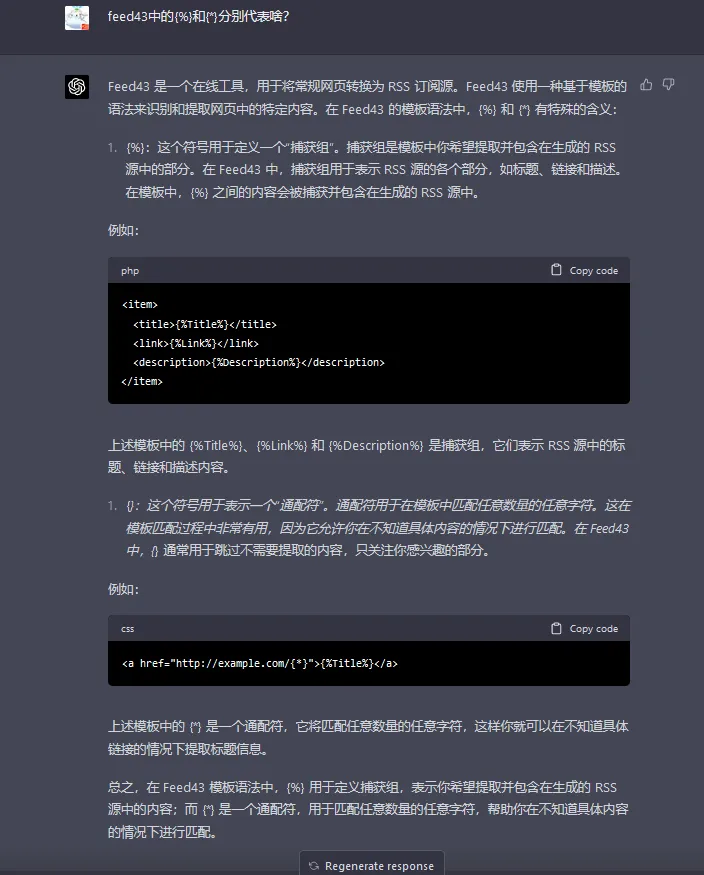
TL;DR:{%}定义捕获组,用于提取你希望包含在生成的RSS源中的内容;{*}是一个通配符,用于匹配任意数量的任意字符,用于跳过不需要提取的内容。
操作演示
- 1、填写要提取网站的url,点击load。
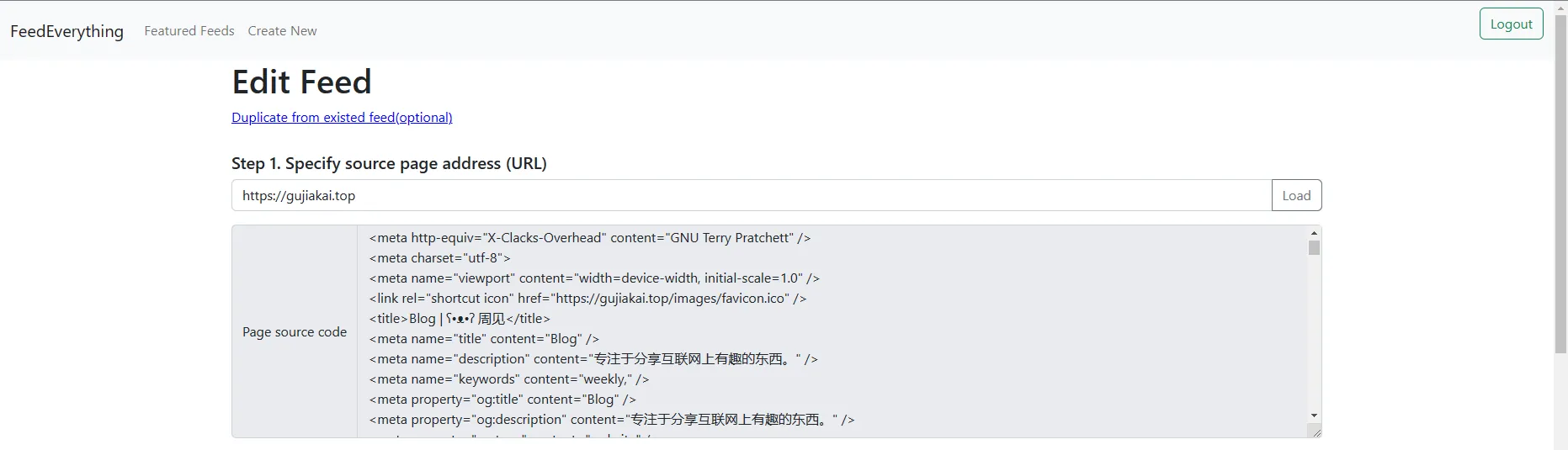
拿我的个人网站来举例(查看源码使用的是chrome插件—Quick source viewer):
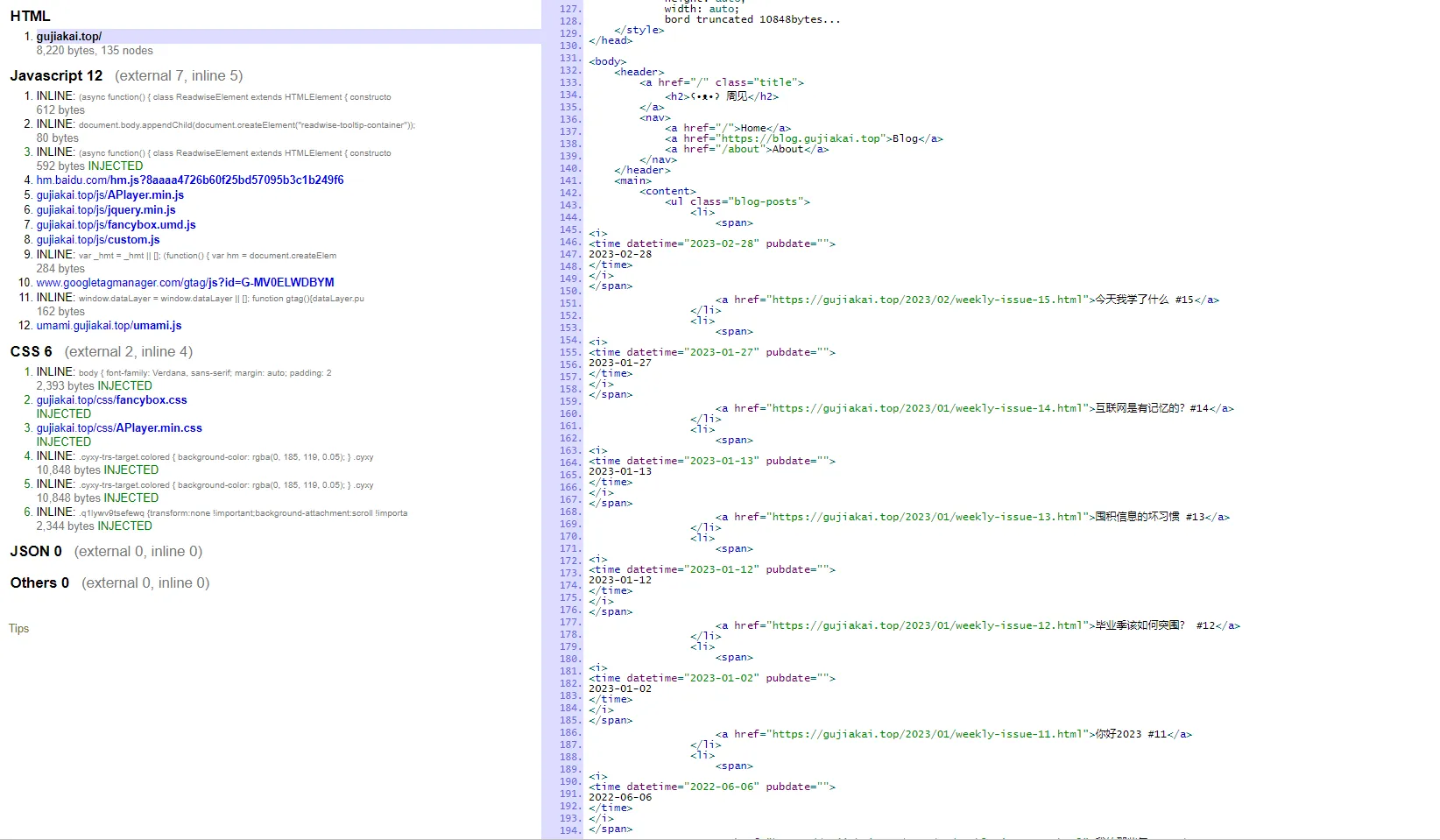
可以看到文章列表中的每一项,都在html中的li标签中包裹着。
| |
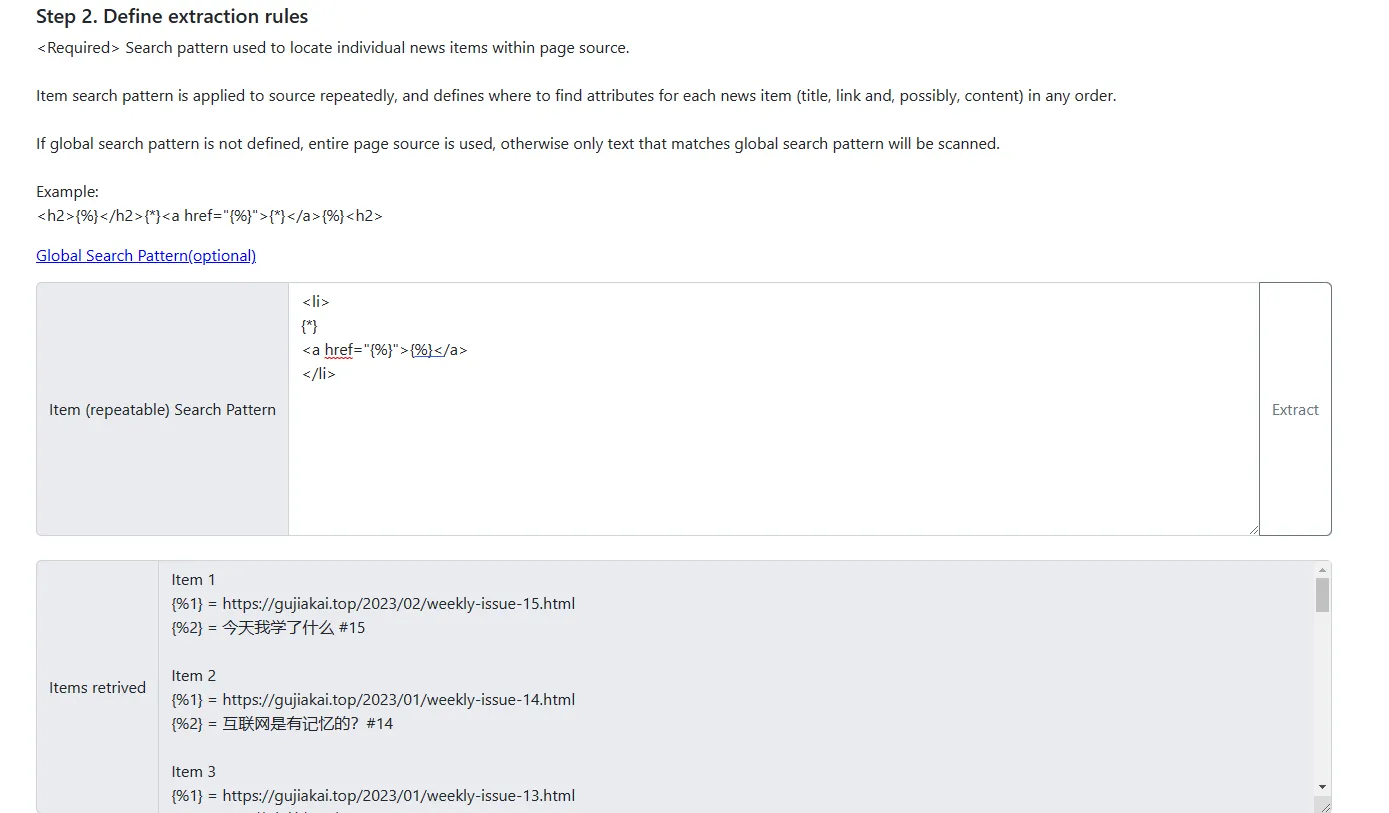
- 2、定义提取规则
于是乎,我的匹配模式就可以这样写:
| |
点击提取后,便得到了文章列表每一项的url和文章标题。
- 3、定义输出格式
最后填写生成rss模板的相应参数后,Item Title填写{%2},Item Link填写{%1},对应步骤二中提取出的item中的二个选项,点击preview。
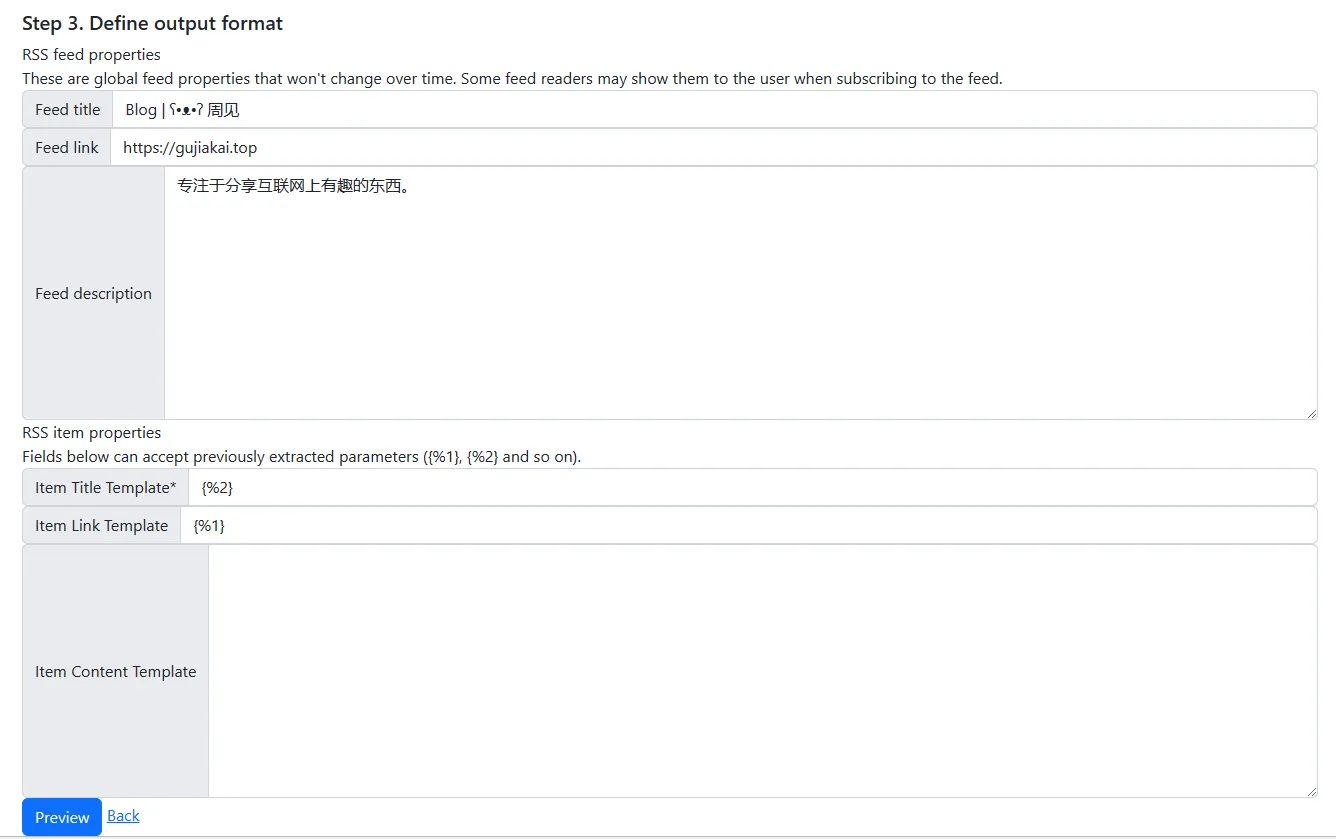
最终效果图如下:
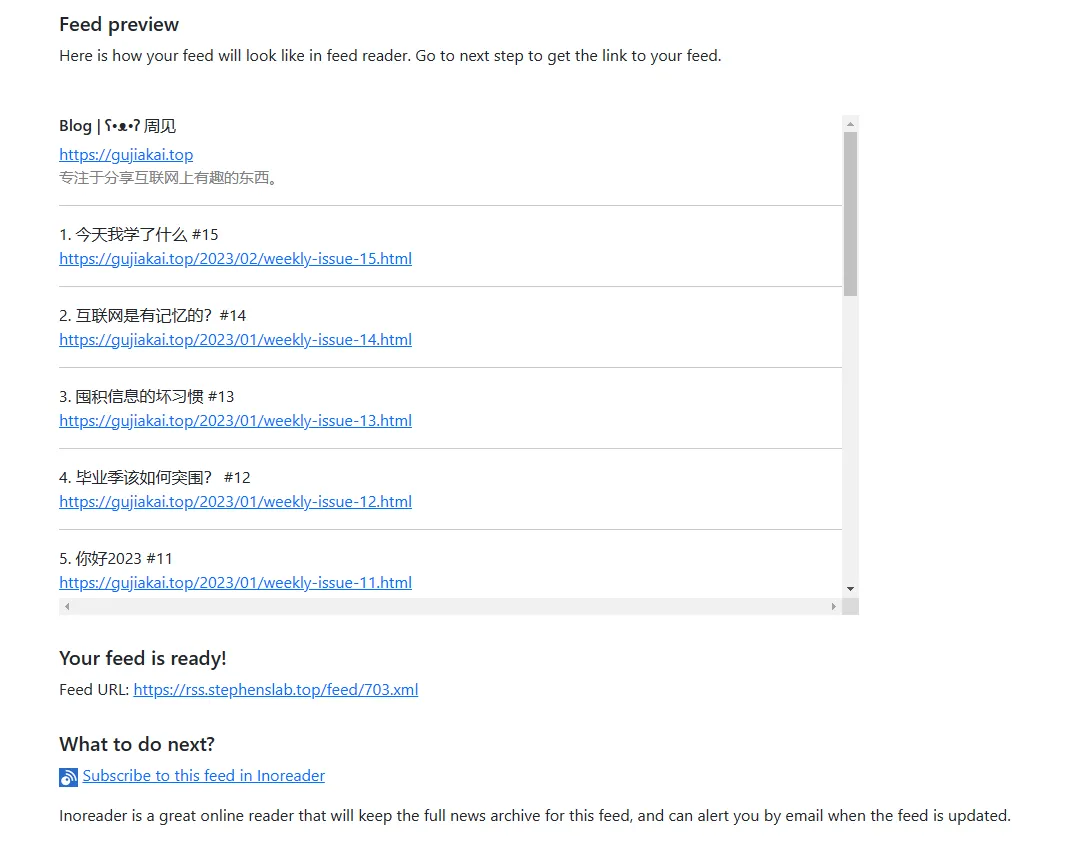
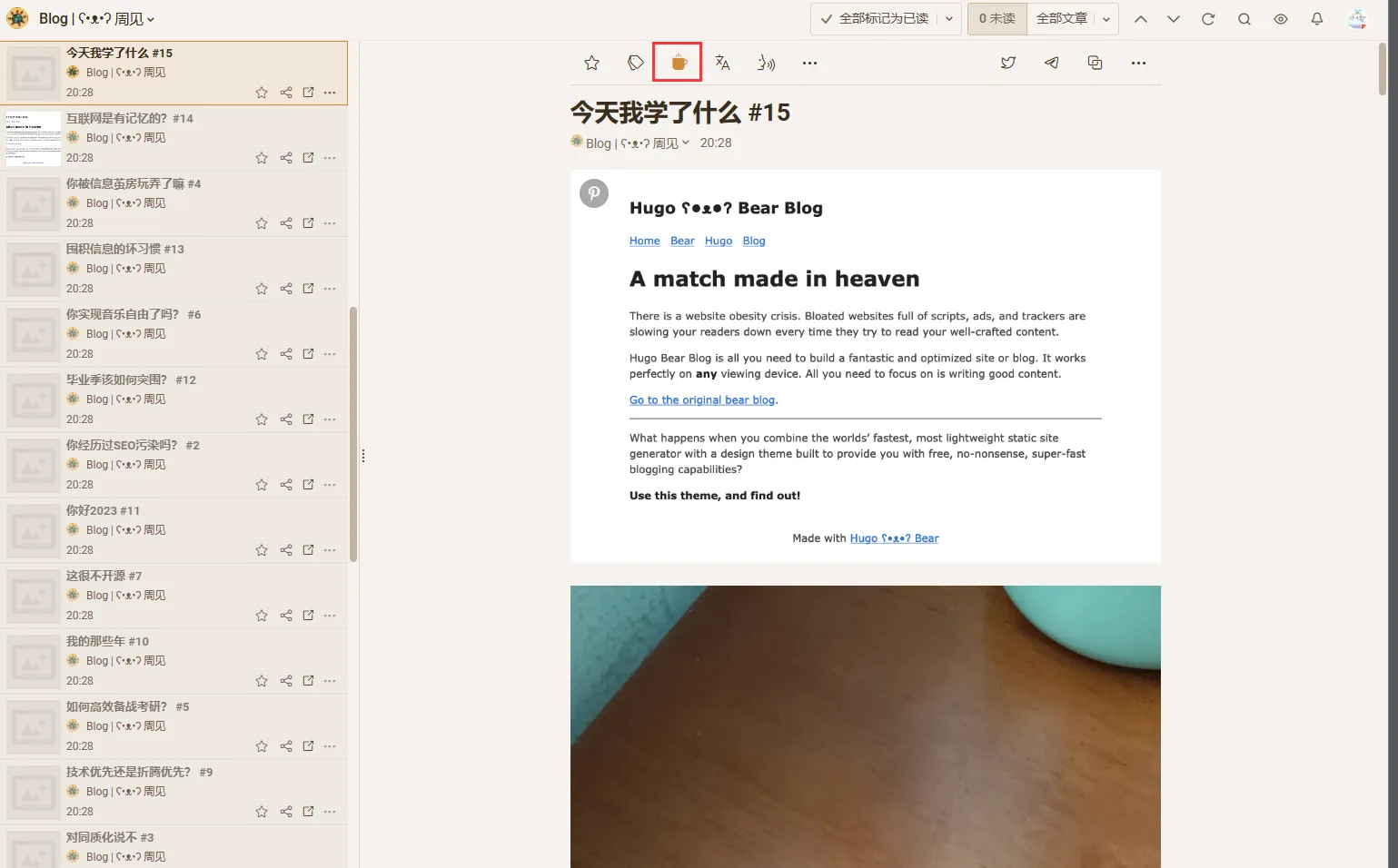
接着搭配全文抓取的RSS阅读器,如Inoreader,即可阅读到文章全貌,无需跳转到网站阅读。
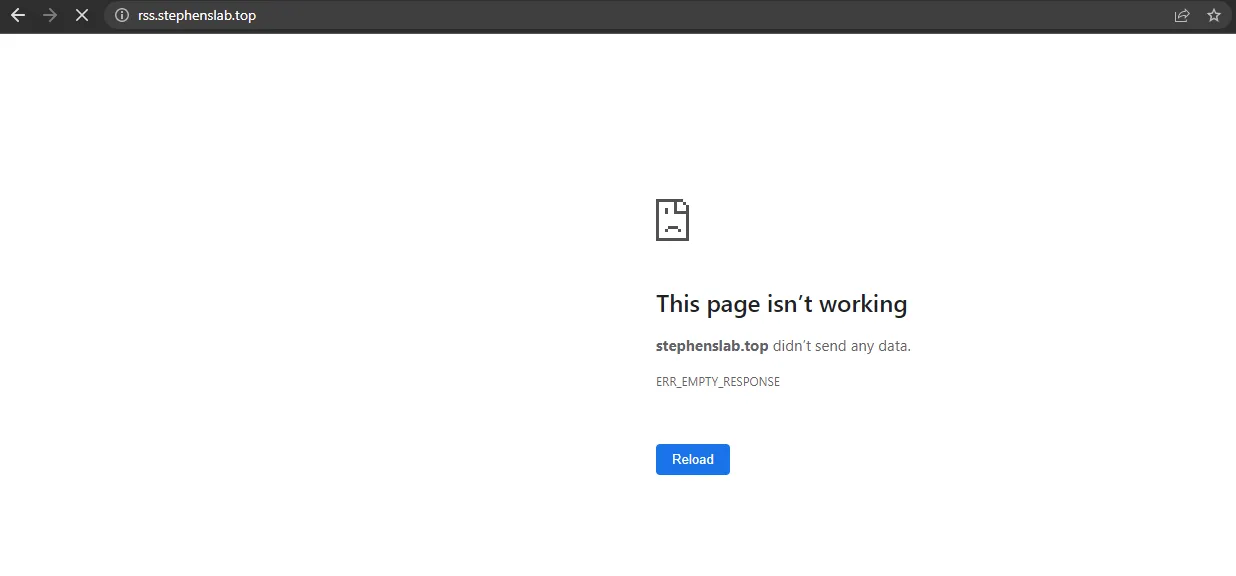
我在写本篇文章时,遇到了一阵子网站访问不了,过了一会,再次尝试,就恢复访问了,可能是我网络不佳的问题吧。
尾声
RSSEverything目前(2023.3.30)并没有付费套餐,但是网站首页的Introduction里面提及会有付费计划。我估摸着应该是等网站做起来了,再考虑出一个付费plan。

此外,作者的Roadmap中包含了全文抓取等功能,值得期待。

RSS是一项古老的技术,在2023年仍有其存在的价值。它帮助人们追踪网站的更新,节省了访问网站查看更新与否的过程。希望这项服务能维持得久一些。
文档信息
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享4.0许可证)