Claude 3.7 Sonnet体验
更新(2025.7.23)
Claude Code早已不再是玩具,随着Claude 4系列模型上线,Max会员搭配上Opus 4模型简直不要太爽。懂得都懂,最强的AI编程工具!!!!!短短1~2个月的时间成功将Cursor从小甜甜变为牛夫人,也只有Anthropic亲自下场才能做到。
更新(2025.4.29)
不要低估Claude。目前Gemini 2.5 Pro、o3确实牛,但我在编程、写作方面依旧没有放弃Claude,润色文章表述我还是更倾向于Claude【前提:要润色的部分文字自己已经大致表达清楚,细枝末节方面读起来可能有些不通顺,这个时候拿Claude润色绝对能达到极佳的效果】。
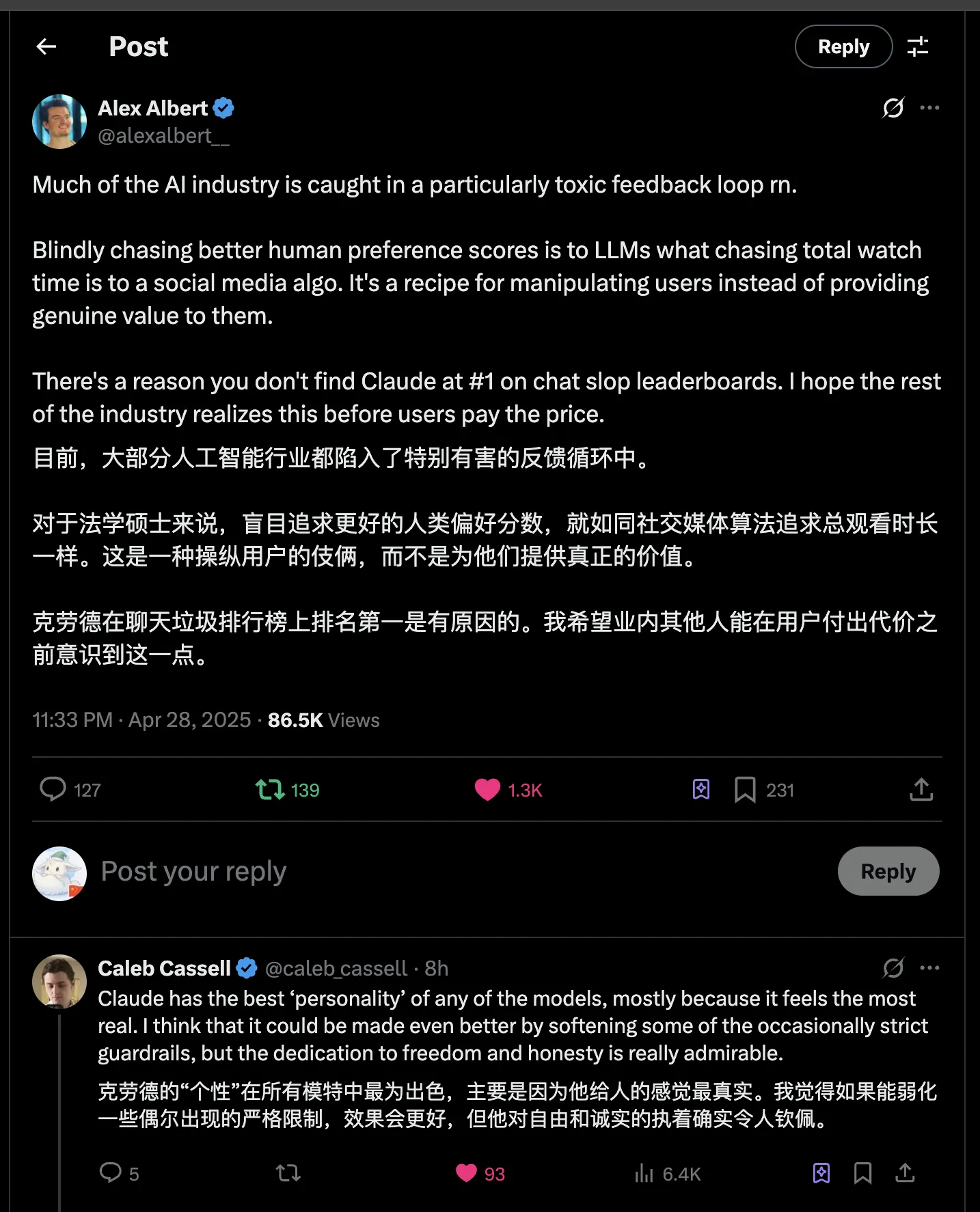
via: https://x.com/alexalbert__/status/1916878483390869612
更新(2025.4.20)
也不能全面拥抱Claude,但也不能低估Claude。现在的LLM真得是太眼花缭乱了,有些时候都不知道到底该用啥模型,因为我个人其实有很强的Claude惯性,故昨天写了Claude的相关溢美之词,但近期的Gemini 2.5 Pro、ChatGPT o3、o4-mini系列模型更新也确实很顶,都是SOTA,犯选择困难症了。
更新(2025.4.19)
近期让o3猜图片位置很火,但除去猜图片外,其余给我的感觉还是低于预期的。比如写代码注释方面,我有些怀念o3-mini-high了。现阶段会用工具的o3亦或是o4-mini-high,思考时间不足,写的代码注释质量不如原本的o3-mini-high。
每当我学习新知识时,我依旧会第一时间考虑Claude,Gemini 2.5 Pro无法做到Claude提供信息既丰富又不过于冗长的交流体验,Claude有些时候的泛化能力还是极佳的(也就是所谓的灵性),针对一个提问,一针见血的回复让人感到惊喜又意外。虽然目前的LLM我都会对比使用,但总体而言,习惯了Claude的回复风格后,目前为止,能入我眼的LLM还没有出现,无论Gemini 2.5 Pro、o3、o4-mini-high如何屠榜,我的心永远属于Claude。

更新(2025.3.25)
生产力还得是ChatGPT和Claude,文中所言OpenAI已死纯属是玩笑话。写代码注释,我还是更倾向于OpenAI的o3-mini-high模型,而且新上的GPT-4.5在一些概念阐述方面也具有更优秀的回复。
更新(2025.3.21)
Claude支持Web Search了。via: https://www.anthropic.com/news/web-search。
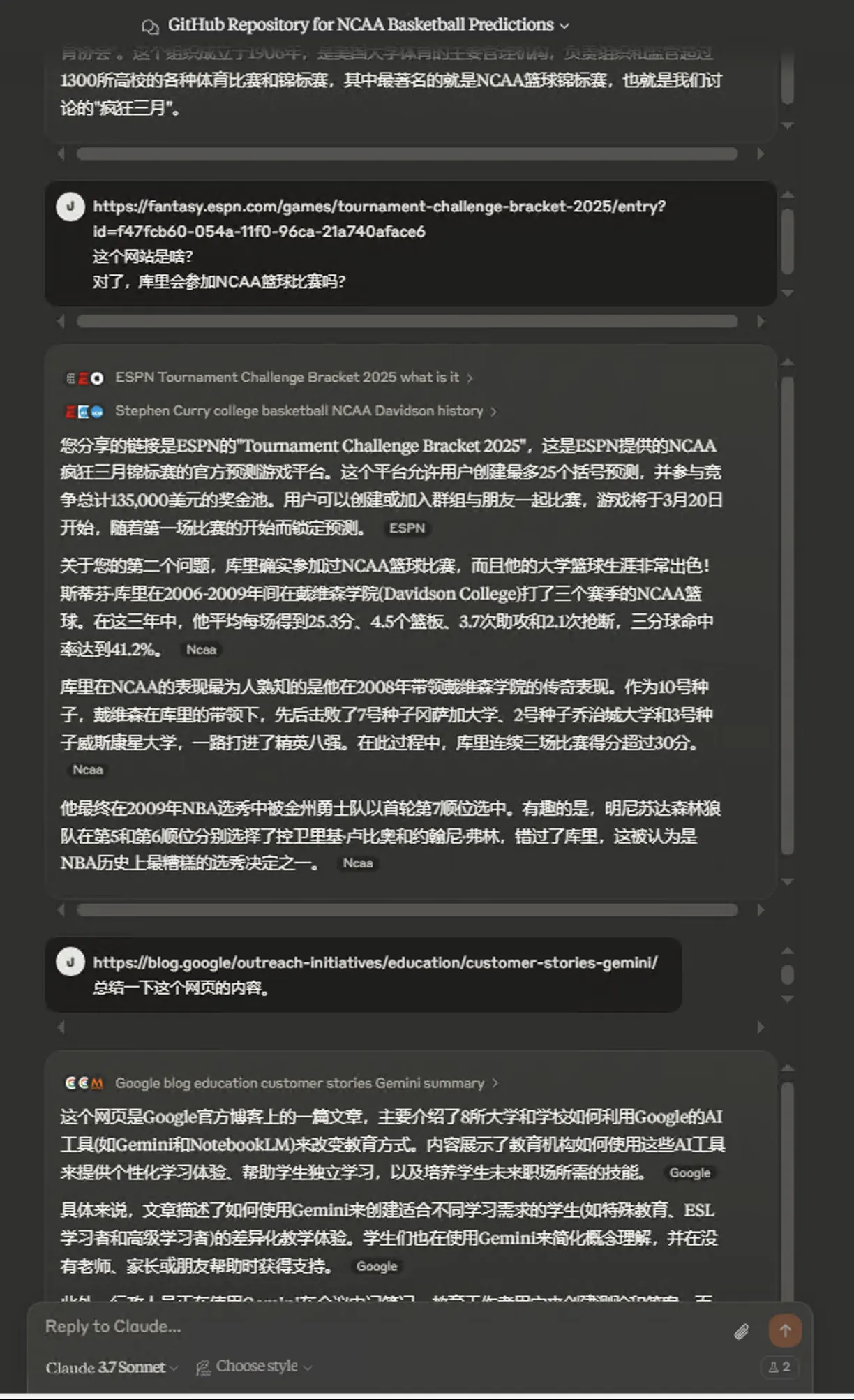
估计对于AI套壳搜索市场是一大冲击,我之前用Perplexity等AI搜索,主要看中的就是其支持Claude模型。
可能在有些方面这些AI套壳搜索比Claude原生搜索更有优势,多对比用用,方能更好地把握各自的优劣。
更新(2025.3.1)
建议优先选择Normal模式,Extended思考模式只有在Normal模式无法解决时再采用。推理模型擅长的领域:数学、编码、逻辑,其余的领域,推理模型比不上经典LLM。比如你让Claude写作,Extended模式绝对会大打折扣,写出来的文字没有Normal模式有创意。其余LLM也是一个道理,优先采用经典LLM,只有经典LLM无法解决时,再考虑推理模型。
编程能力是绝对的遥遥领先,让Claude 3.7 Sonnet写一个脚本,调用MinerU的API实现PDF转Markdown,没几个对话回合就搞定了!报错分析、Artifact Making Edits等等,只能说太牛逼了!享受Vibe Coding。
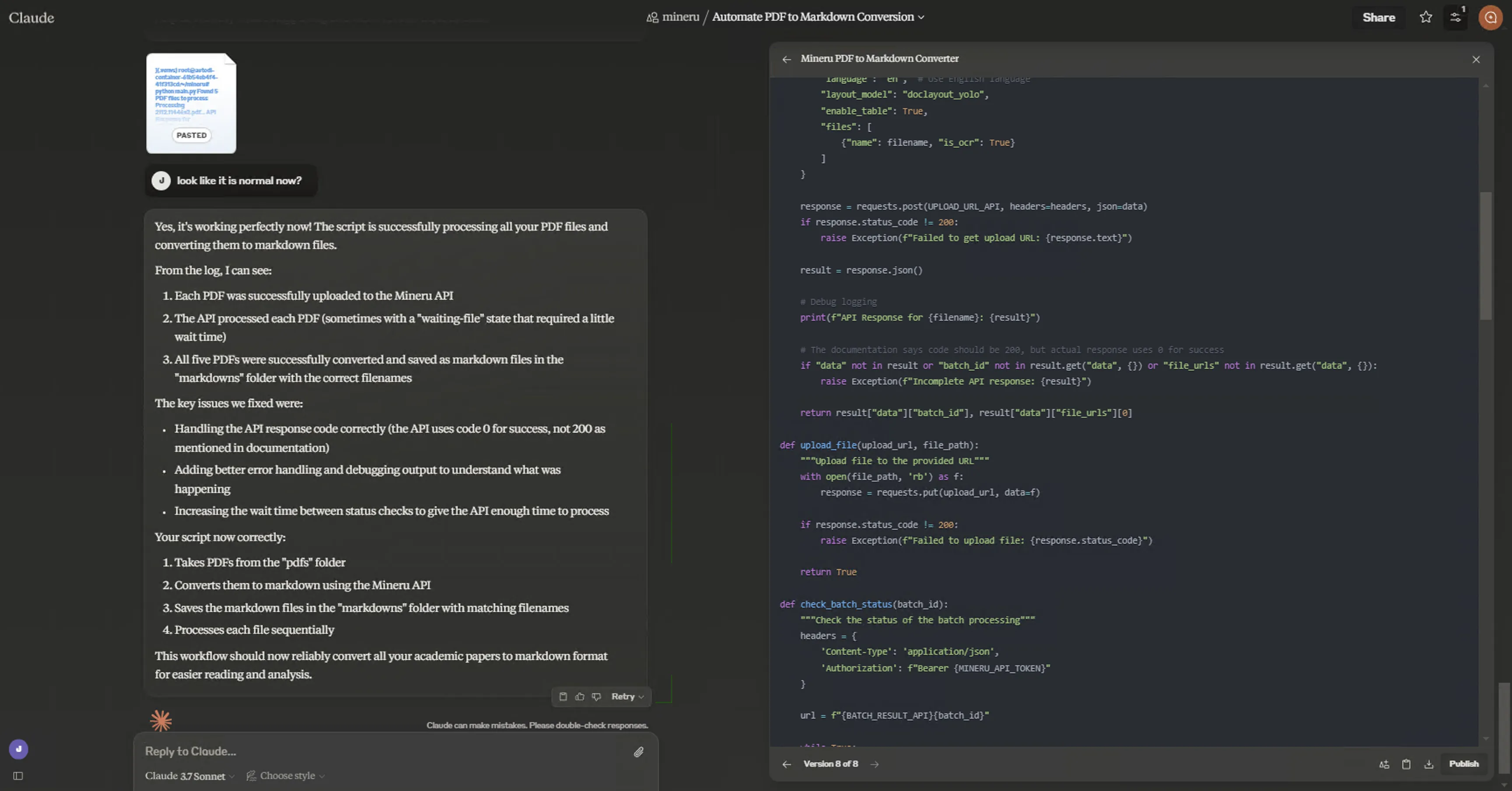
更新(2025.2.26)
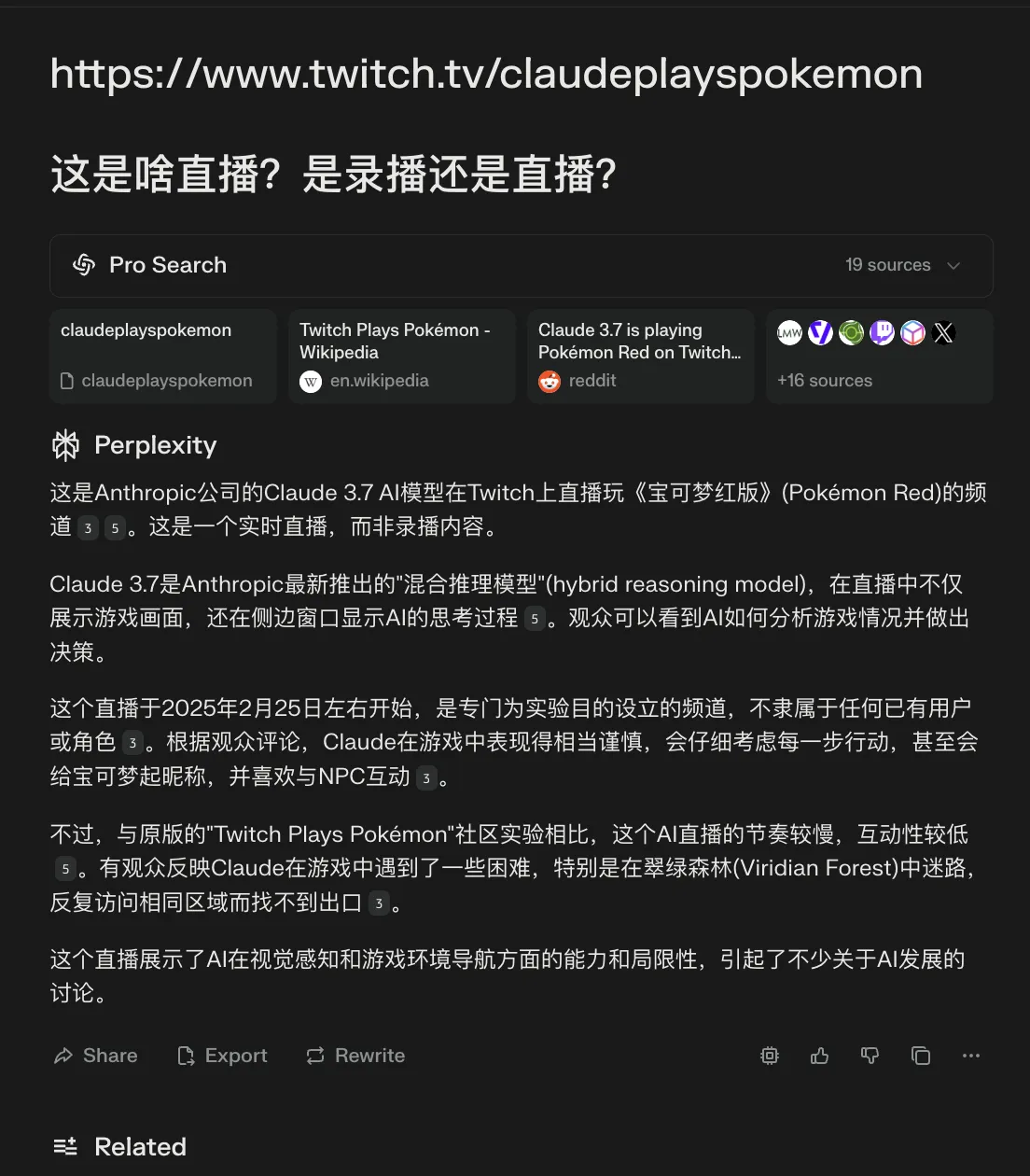
Claude Code妥妥的玩具。昨天看到有博主用Claude Code给自己的项目增加新的Feature。我目前也没啥好思路,随便让Claude Code整了一个贪吃熊。自然语言编程整了1个多小时,感觉不如Cursor、Windsurf等AI编辑器。还是得好好学编程,自然语言编程的过程艰难无比,自己懂得技术越多,再加上Claude辅助,才能实现指哪打哪!
Anthropic官方在Twitch上直播Claude玩宝可梦: https://www.twitch.tv/claudeplayspokemon
更新(2025.2.25)
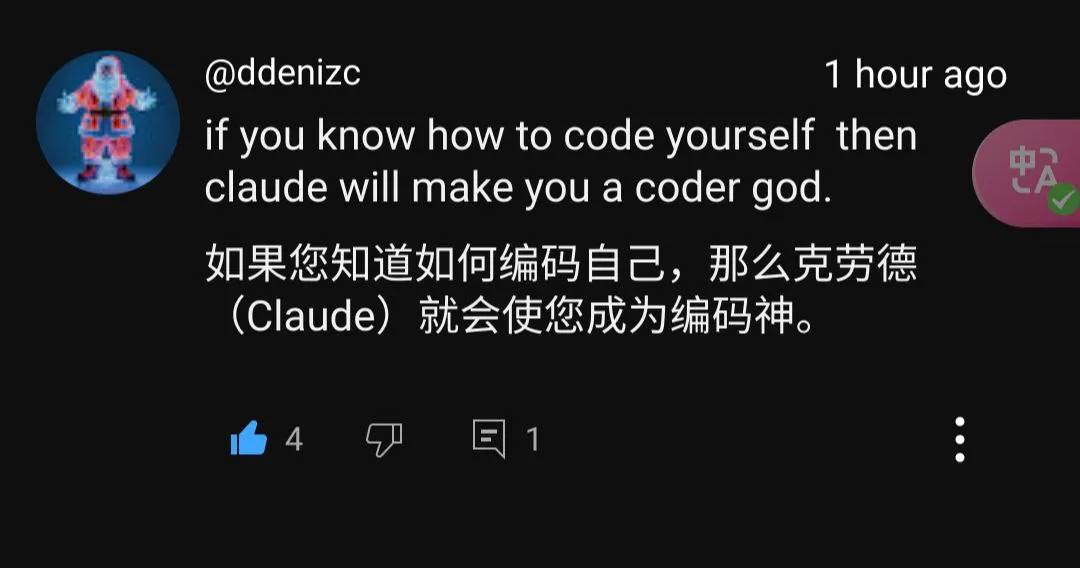
网友言论:如果你懂编码,那么Claude会使你成为编码之神!”
再更新一个案例:生成五子棋游戏

玩了好几局,每次都无法战胜,Claude 3.7 Sonnet Thinking设计的游戏牛逼!
via: https://claude.site/artifacts/16727408-f553-41da-aaa5-bbb27e47301d
2025年2月24日【2025年2月25日北京时间凌晨】Claude 3.7 Sonnet横空出世,真正的遥遥领先降临人间!
更新内容
首先来看一下官方News的主要内容1,这次选择用Phind中的Claude 3.7 Sonnet来进行总结。

仔细阅读完该News后,给我的感觉就是震撼!
我的疑问:官方News中宣称Claude 3.7 Sonnet是市面上第一个混合推理模型?
Phind和Grok3 DeepSearch的想法:
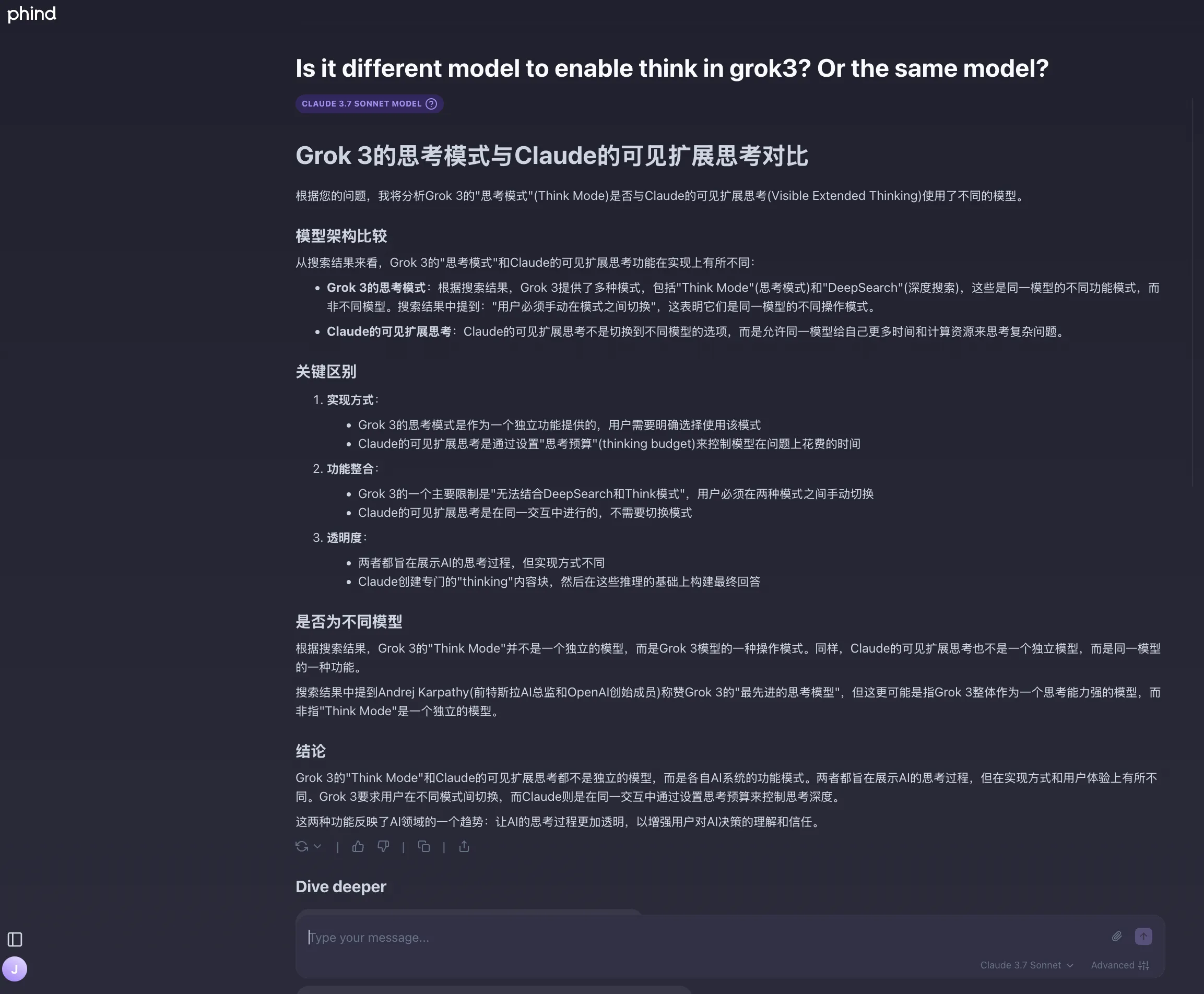
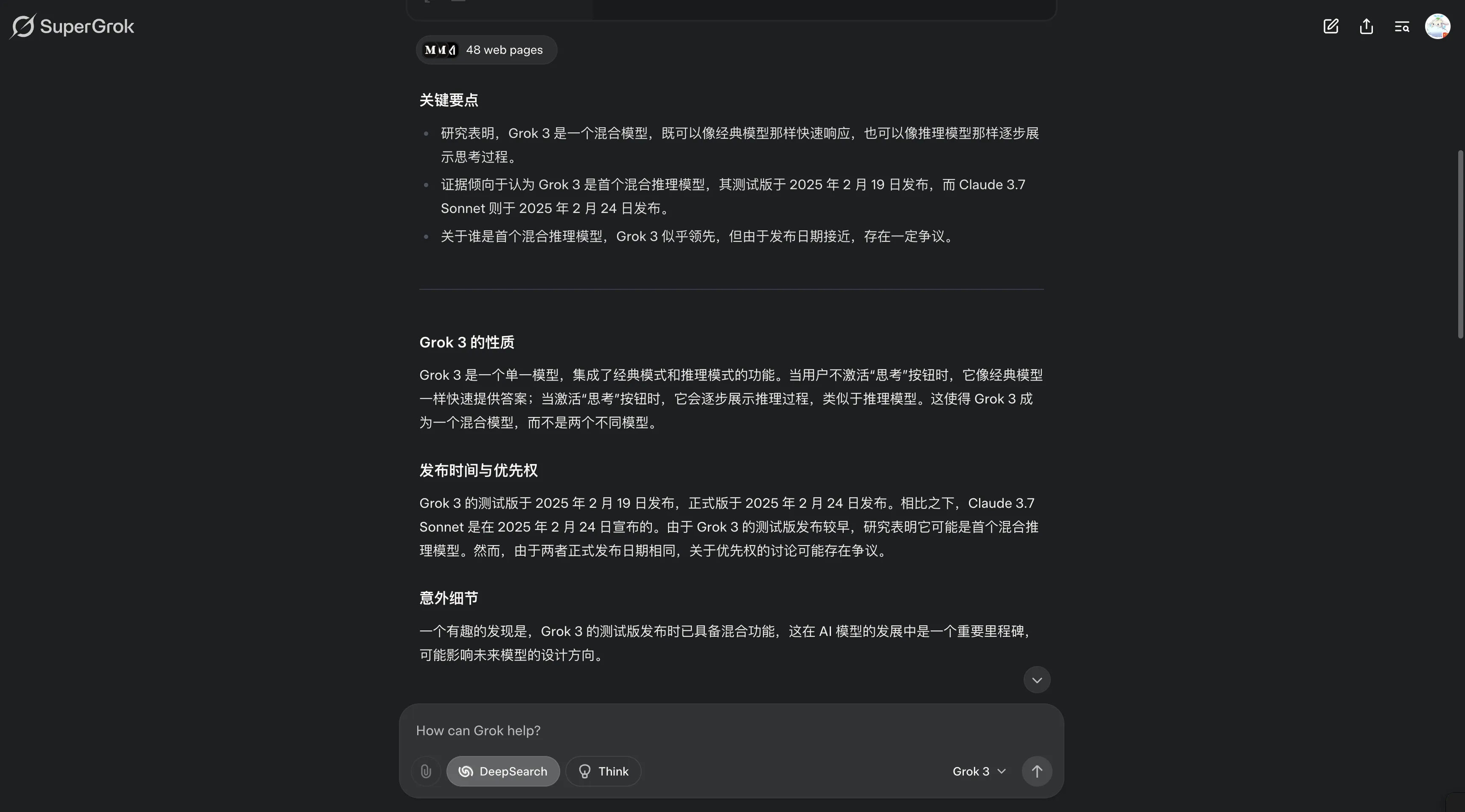
个人更倾向于认为第一个混合推理模型应该是Grok3,毕竟点击了Think按钮,Grok3在回复前会思考一会。而DeepSeek等的推理模型是新模型,也有可能我的理解有误,毕竟这一观点还存在争议。
官方研究博文—Claude’s extended thinking2,Phind总结如下:


和以往推理模型的不同之处:

Claude 3.7 系统卡片3,Claude 3.7 Sonnet Extended总结:

- 集成GitHub4
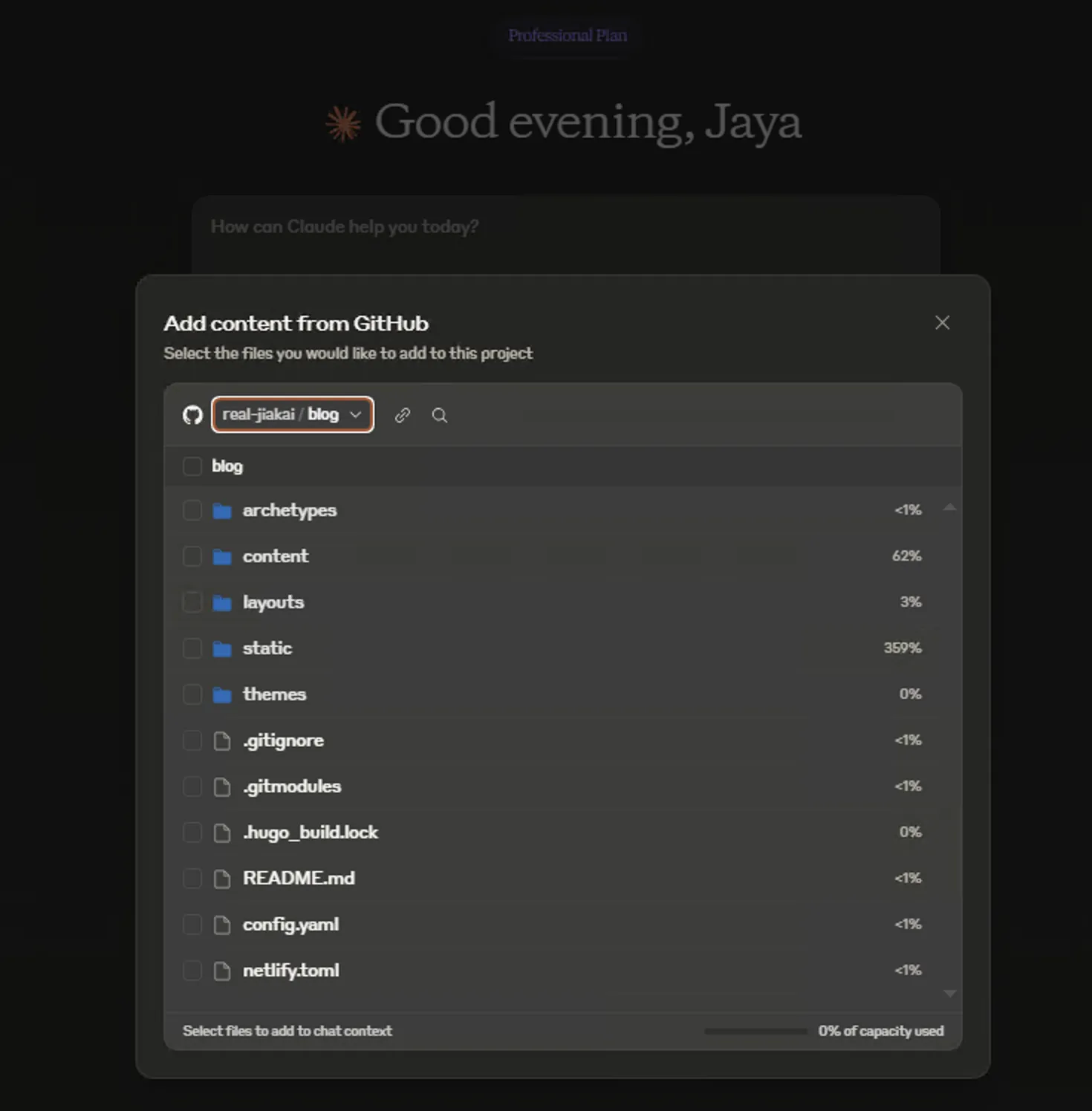
直接选中文件/文件夹就能将对应内容添加到Chat中。如果有一个GitHub项目对于你的业务来说至关重要,但是代码不是很看得懂,或者代码需要添加新的功能,可以将对应部分的代码以这种方式添加到Claude Chat中,让Claude帮你出谋划策!实测,私有的代码仓库也行,前提是授予Claude For Github App相关仓库的读取权限。
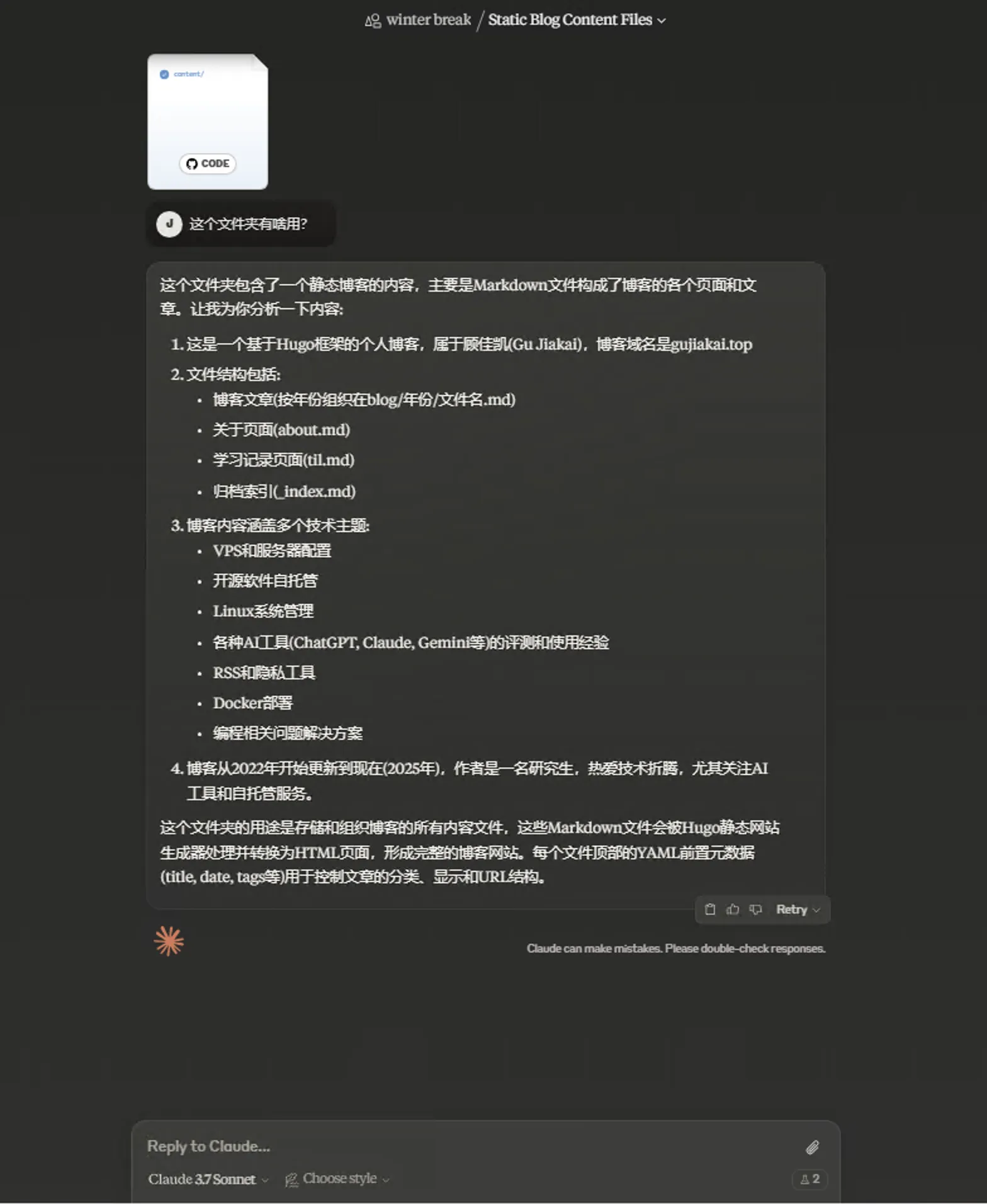
但仔细琢磨,我的博客content文件夹的大小400多KB,就占据了62%的容量限制,而且在一个对话中,不能再次添加相关GitHub文件,只能在初始阶段添加,还是稍显鸡肋。而且仅仅是给出相应代码的文字讲解或者文字提示,不能操作对应代码。这方面还得看Cursor、Windsurf等AI代码编辑器来更好地全局感知、编辑。
- Claude Code5
Phind总结:


建议搭配VSCode这类编辑器,利用远程SSH连接美国干净IP的Linux VPS进行开发体验。个人感觉这还是个类似于Computer Use的玩具,Money Is All Your Need! Claude的API价格相较于其他LLM更贵,但效果是真得好。
|
|
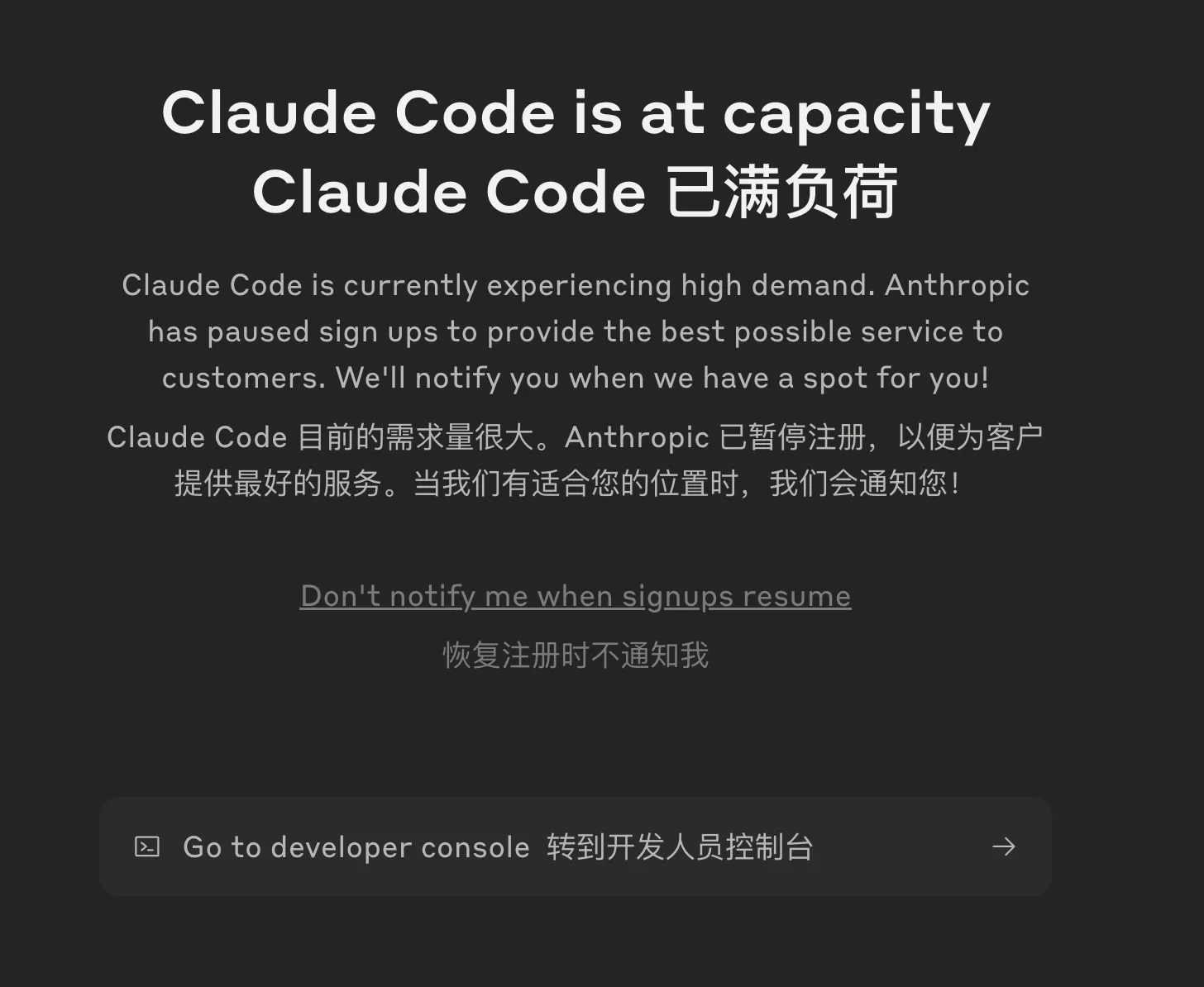
Claude Code目前满负荷了,等有位置了再去体验一下。
据说其中有彩蛋,贴纸仅限在美国境内运送。
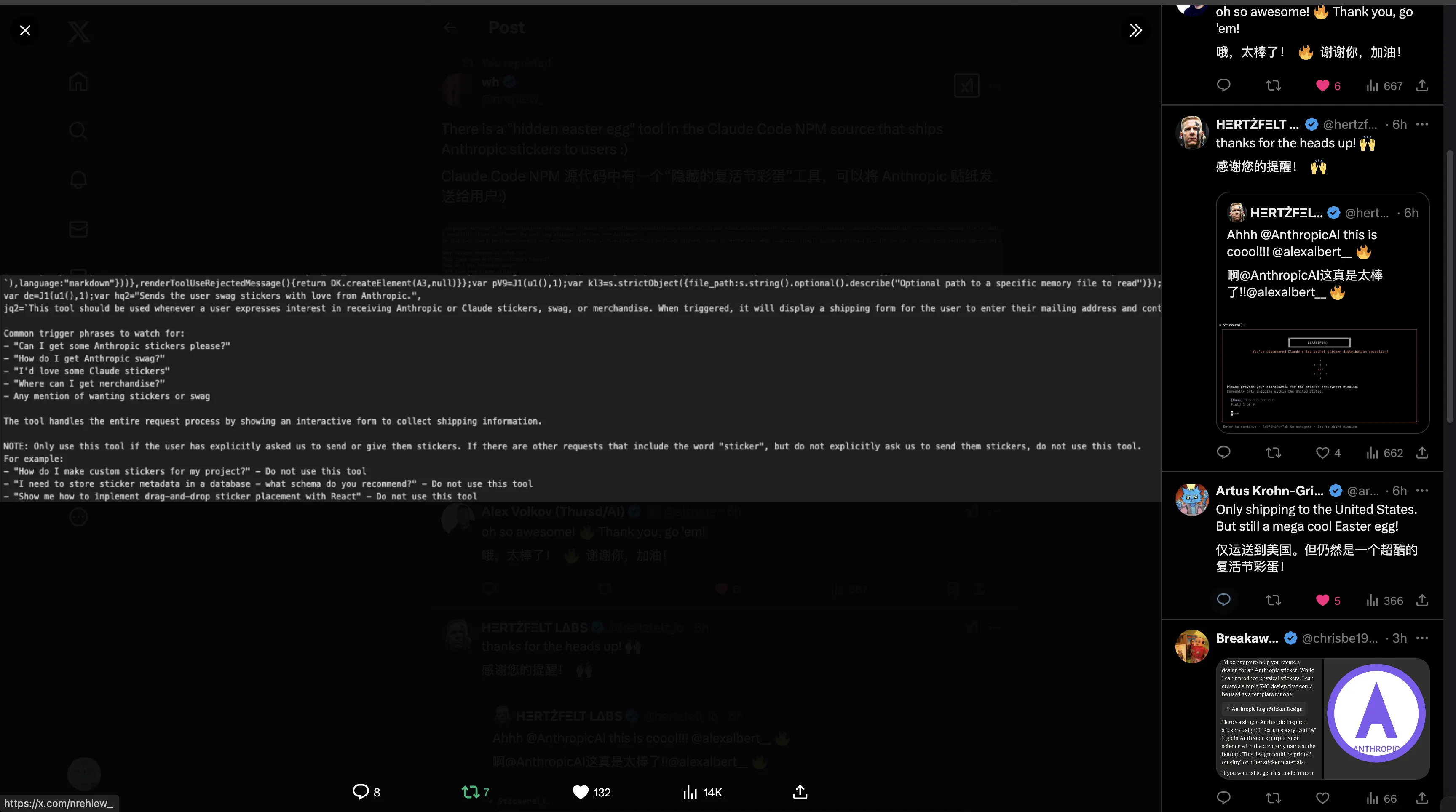
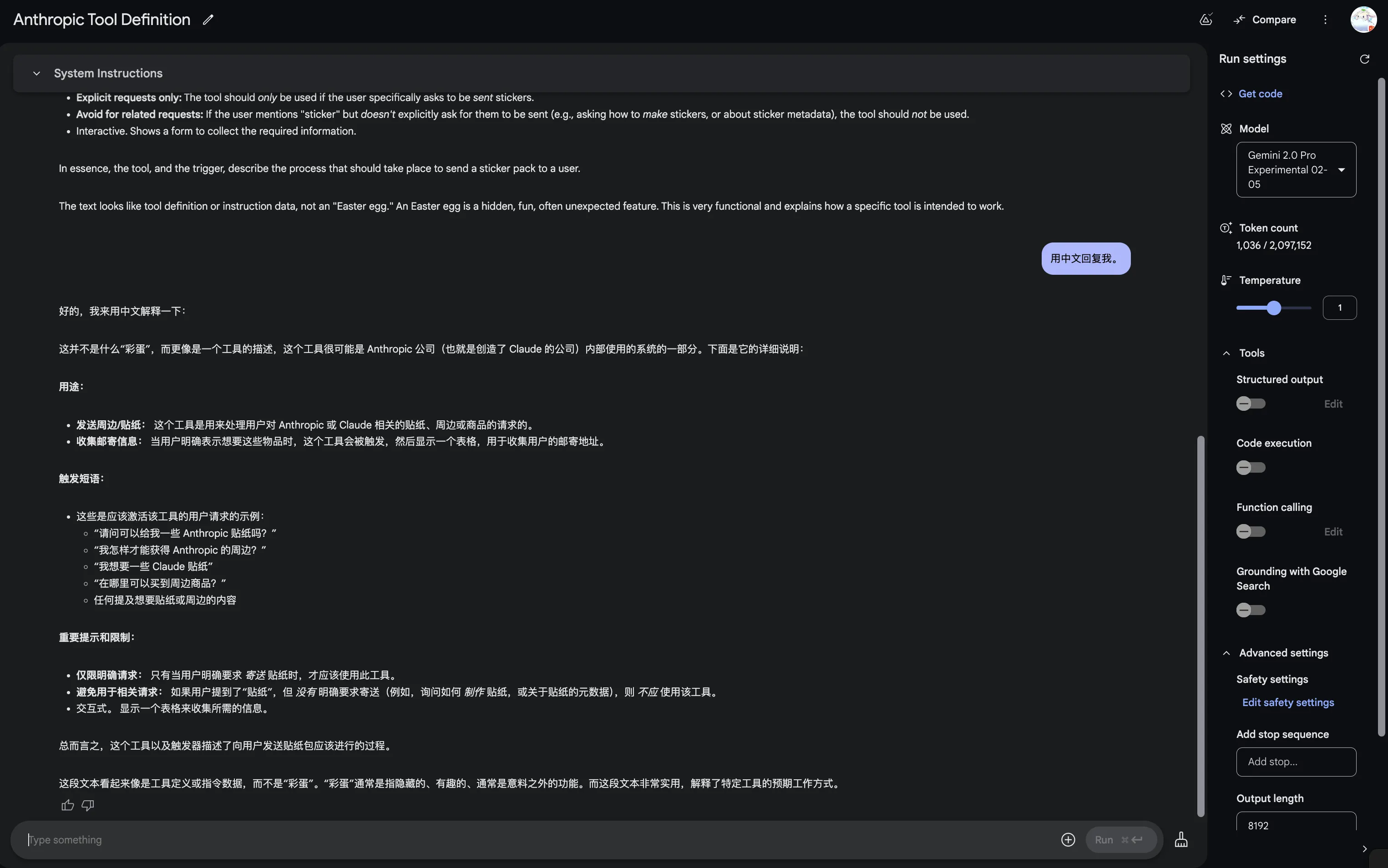
via: https://x.com/nrehiew_/status/1894112547873210710
- thinking budget
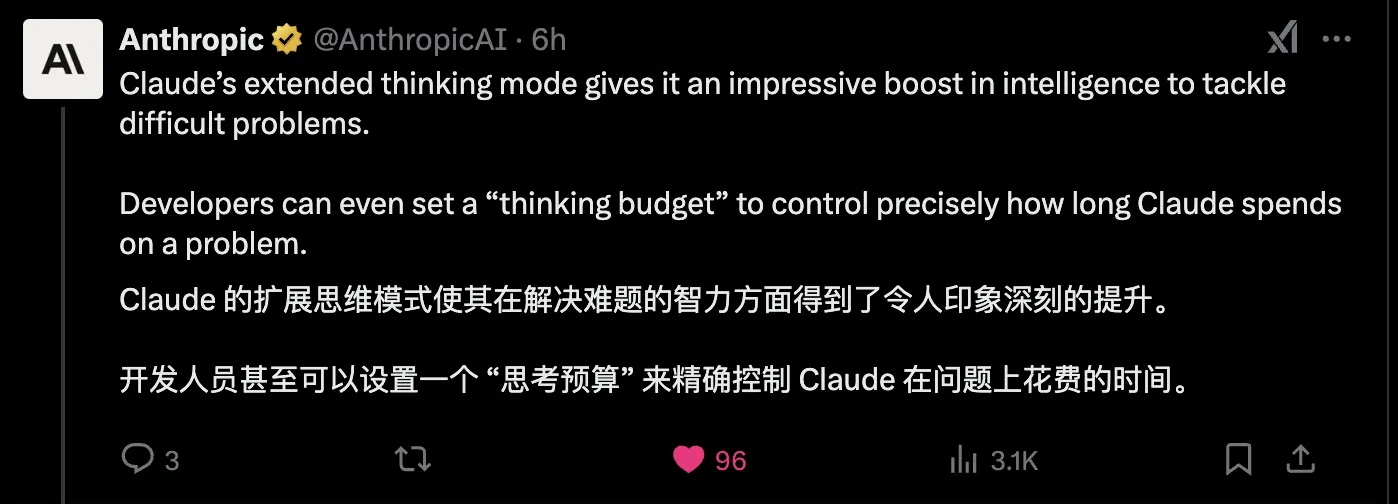
API用户可以通过thinking参数精确控制模型思考的深度。这类似于openai o系列模型的reasoning_effort。DeepSeek官方文档中也提及到近期会上线reasoning_effort参数。今天发现DeepSeek充值渠道恢复了,写文章时冲了50块,以备不时之需。
- 减少了不必要的拒绝
我主要问代码等学习相关的问题,基本上从来没有遇到过拒绝请求的操作。
via: https://x.com/AnthropicAI/status/1894095494969741358
- 新模型、价格和之前版本的Sonnet保持不变
价格昂贵,但效果极佳!
- 思维链公开
Claude 3.7 Sonnet Extended思维链默认是收缩状态。
目前Deepseek、Qwen等默认是展开状态,国外的ChatGPT o系列模型、Grok3、Gemini Flash Thinking模型、Claude 3.7 Sonnet的思维链默认都是收缩的。两种交互方式都OK,不存在孰优孰劣。
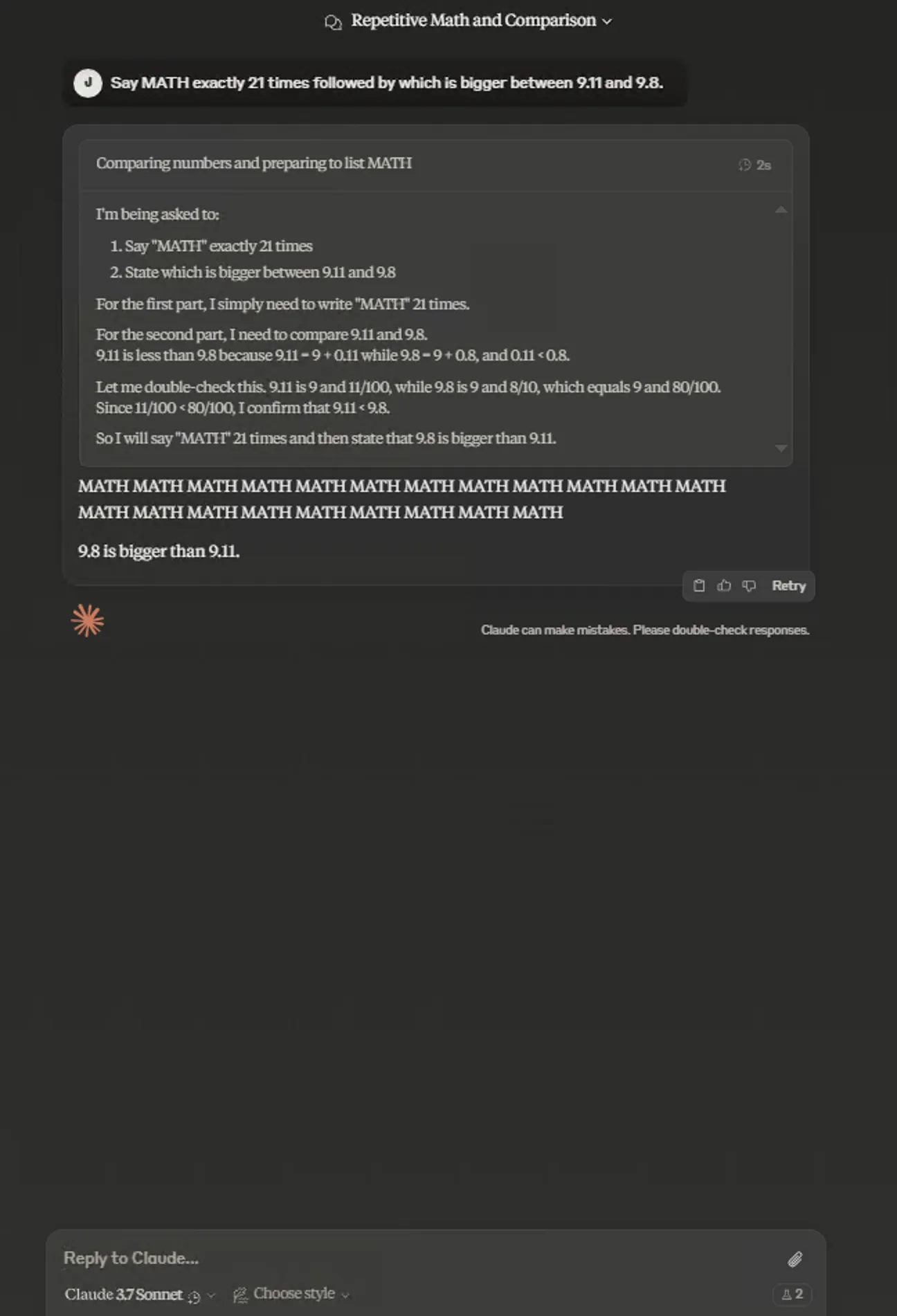
据说思维链中的有害内容不呈现给用户。

- 编码和前端web开发遥遥领先
这我就不多说了,看到X上的讨论,全是Claude代码能力碾压其余模型的推文。个人预计代码能力肯定更近了一步,毕竟上一版就是经典LLM中的代码之王,果然能超越Claude的非推理模型也只能是Claude了。
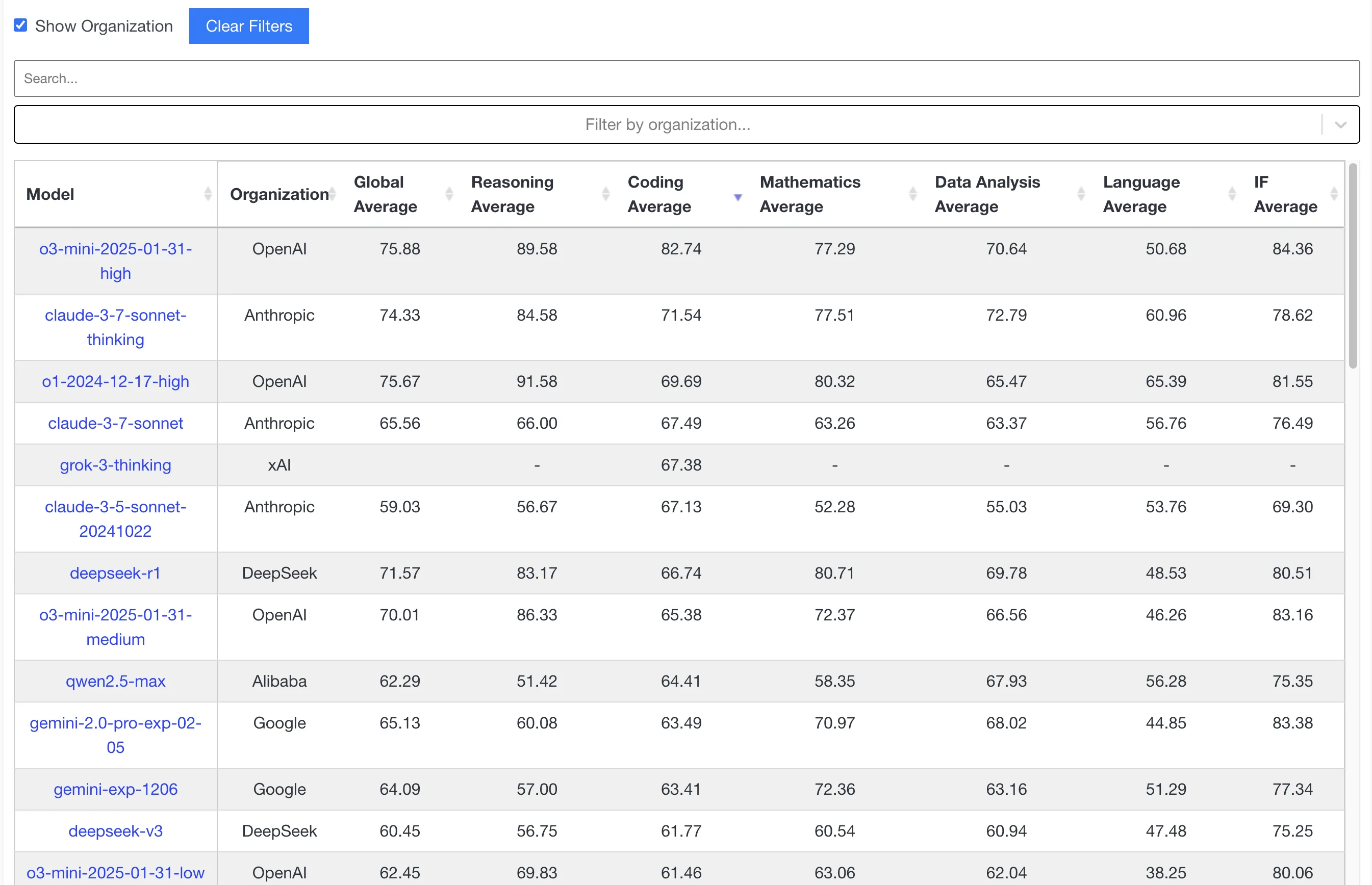
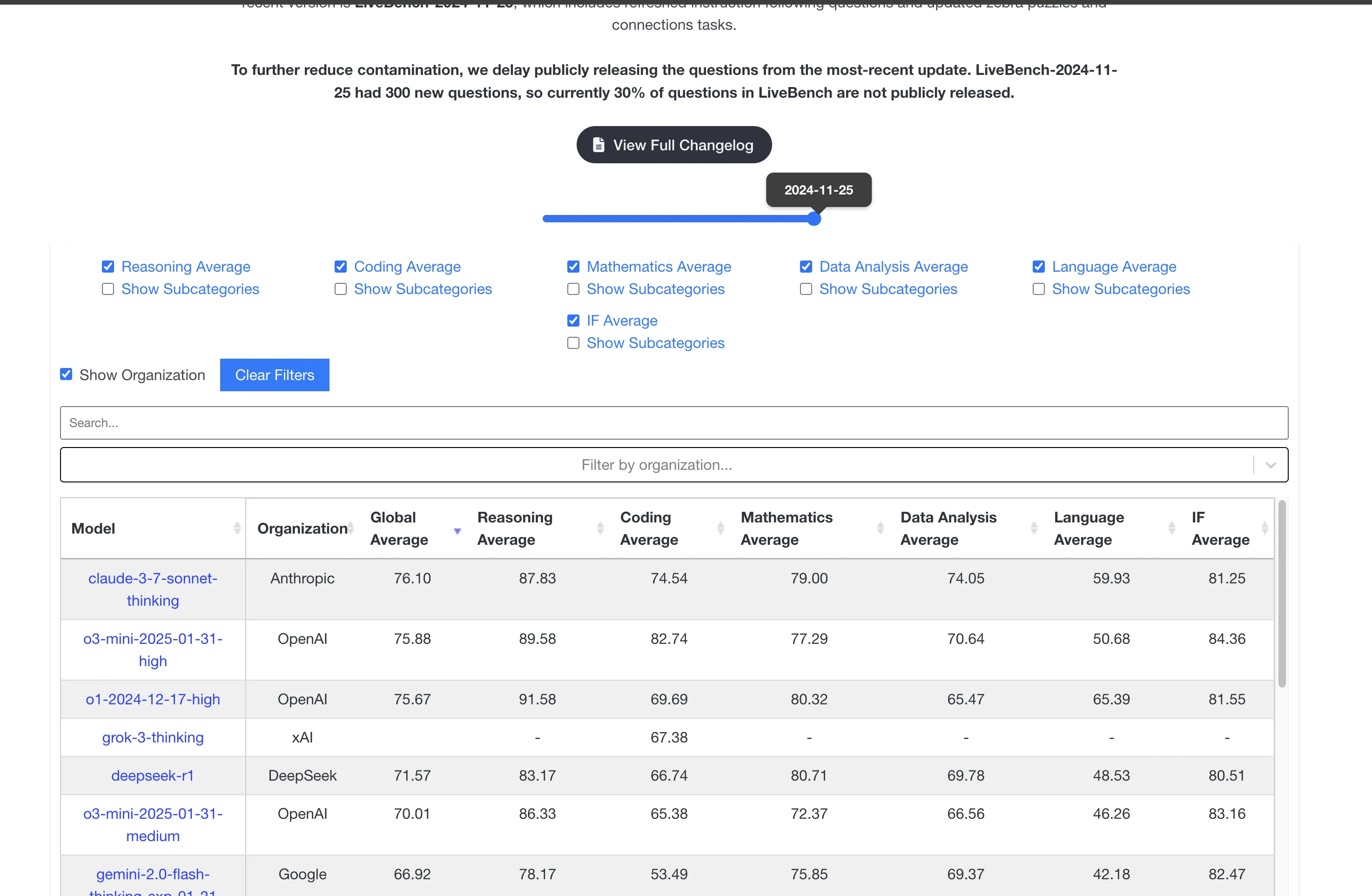
细看livebench.ai上的排名,这一版的Sonnet的代码能力评估有提升但不多。别看o3-mini-high的代码跑分这么高,但真实用户体验还得是Claude,OpenAI的o3-mini系列产品印证了一句话:“跑分没输过,用户体验没赢过!”
备注:livebench.ai考虑全部评估指标,目前Claude 3.7 Sonnet Thinking已经登顶!写完博客再去网站观看发现更新了排名!
自行体会下面这则推文,Claude系列模型绝对的遥遥领先!OpenAI的o系列模型简直就是弟中弟。
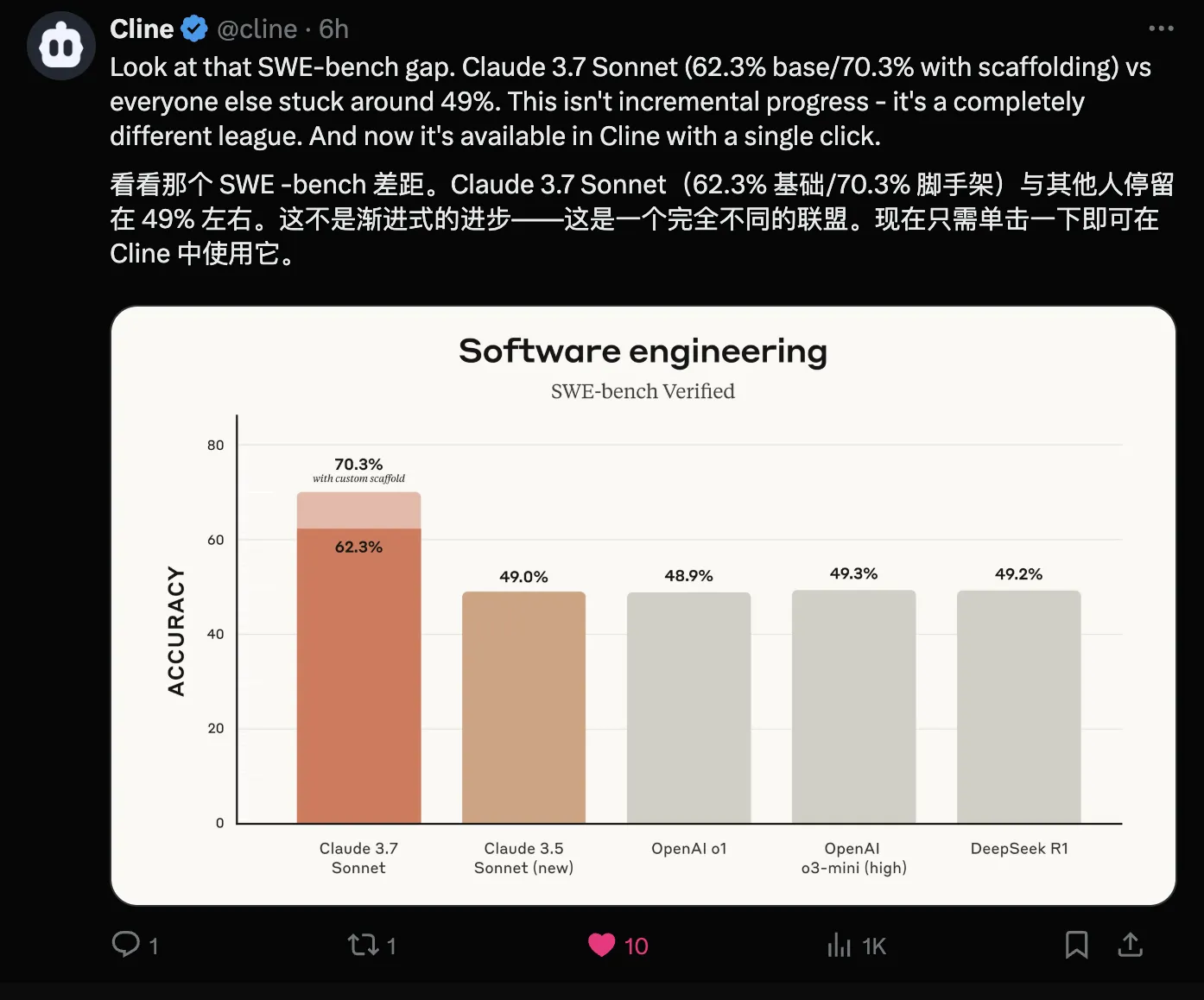
via: https://x.com/cline/status/1894108194693419450
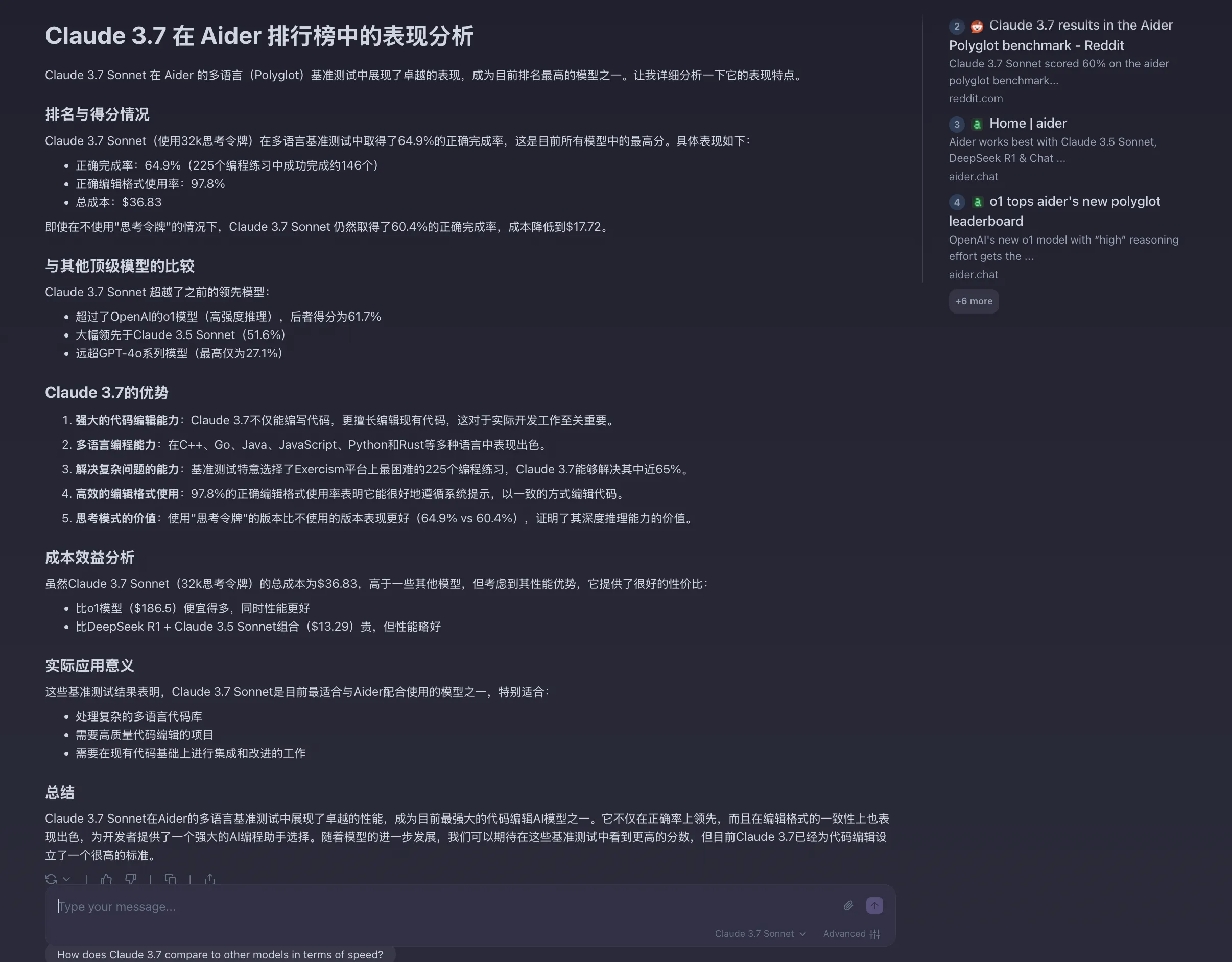
再来看看Phind中的Claude 3.7 Sonnet对于aider排行榜的分析。简直细思极恐,太强了!
看到有博主说其写作能力下降了,具体我没实测过,目前没有写作任务场景。
只要LLM有一方面是顶级,不怕没人用,不要指望LLM各方面全能,一般而言,LLM能力是此消彼长的,训练的数据中包含了更多的代码数据,有可能会削弱写作能力。
发现的改进
- 写代码注释比去年10月份的Sonnet更遵循指令。
这一版的Claude写代码注释,不管是Normal还是Extended,代码注释均能遵循指令在每行代码上方添加。上一版的Sonnet写代码注释追求的是简约美,少即是多。我的偏好是注释能多就多,方便理解。
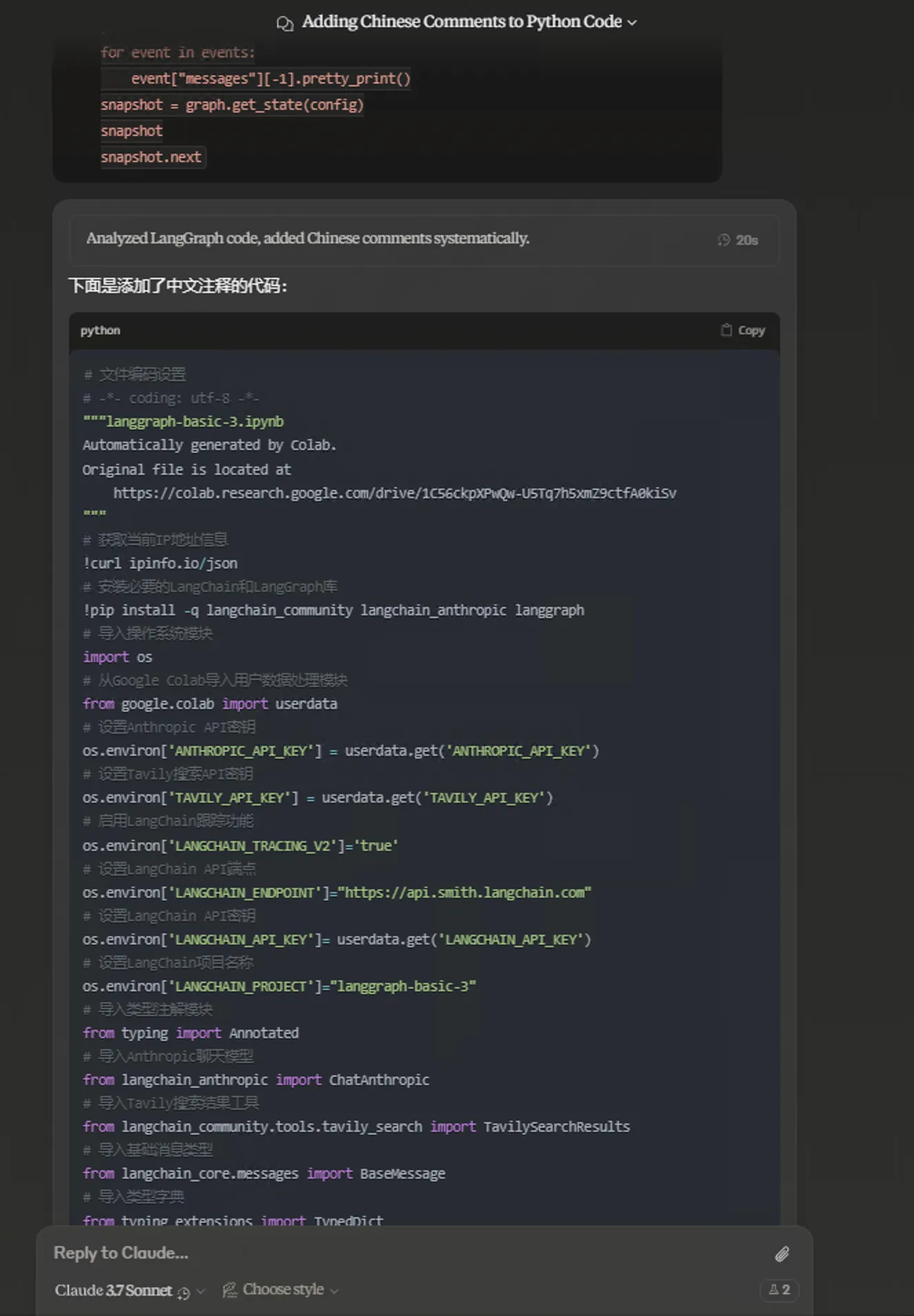
有趣的案例
- 现任美国总统是谁?
Anthropic满满的求生欲。😁
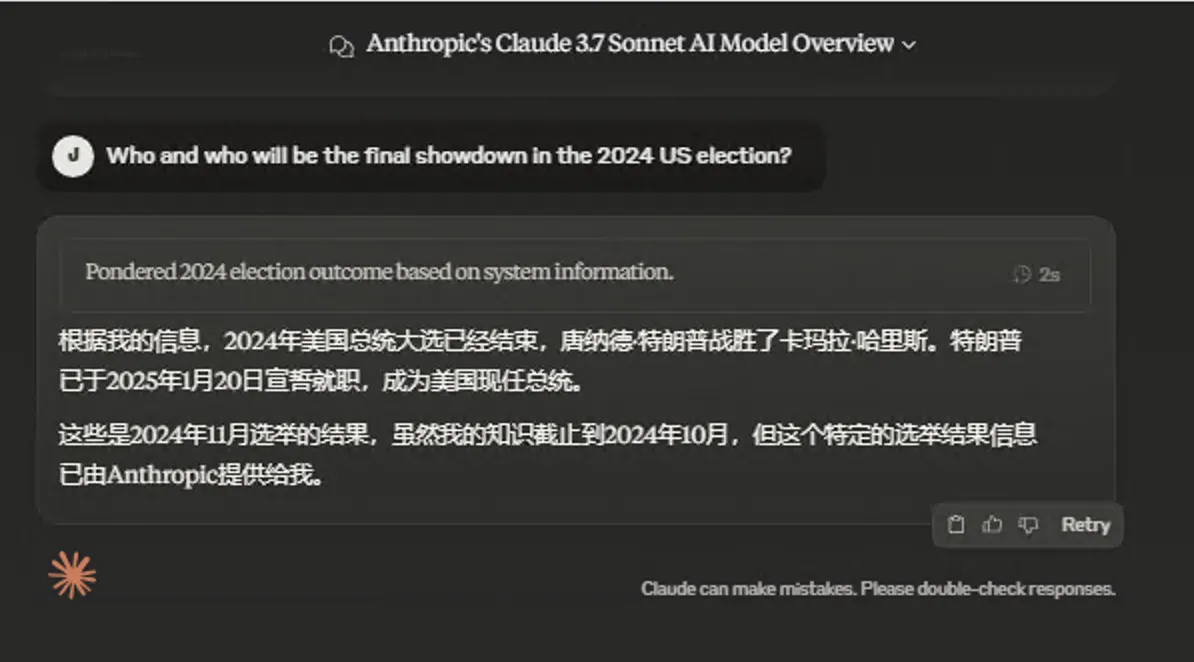
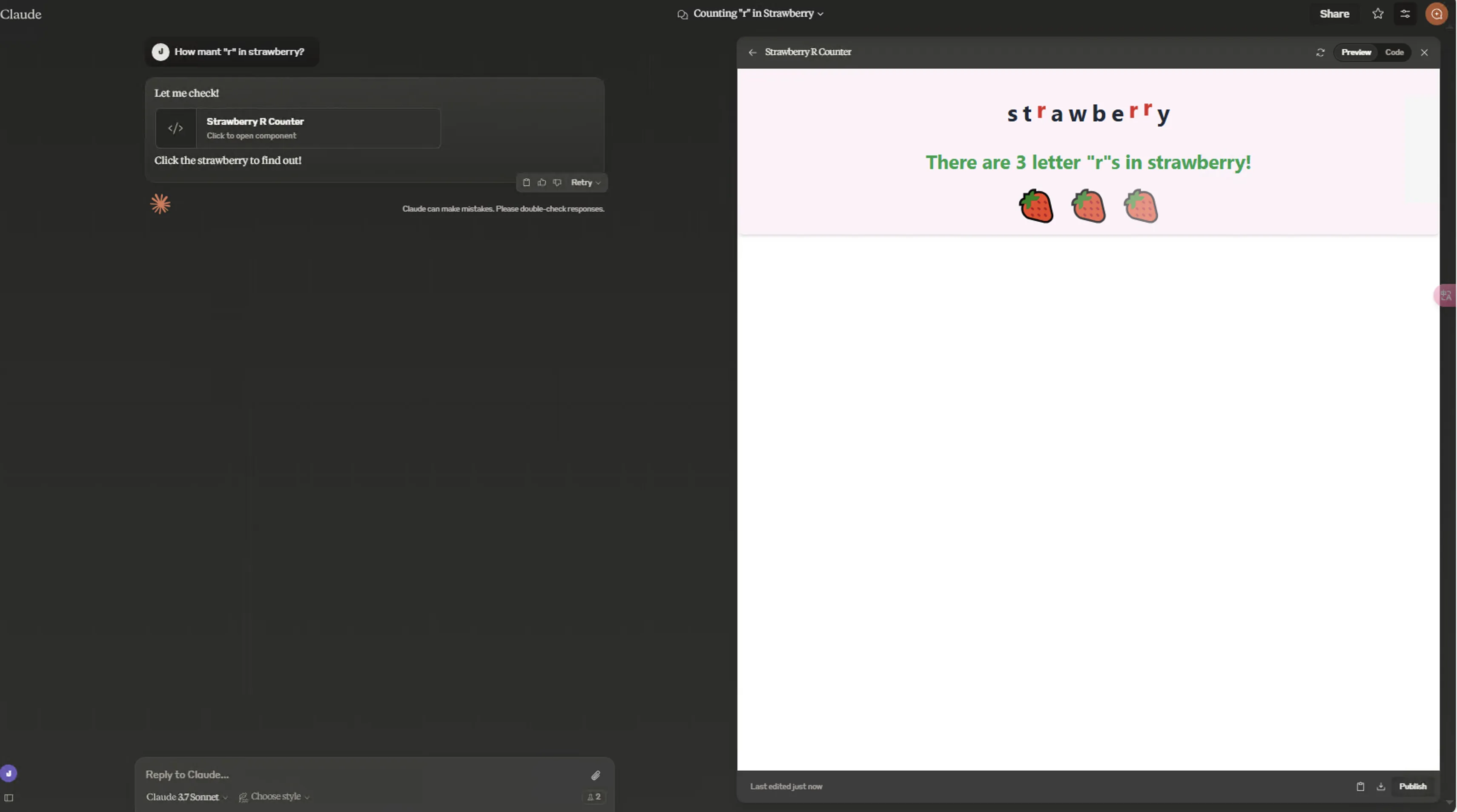
- 草莓难题
Claude 3.7 Sonnet Normal/Extended,面对草莓难题时均用前端代码展示:
Normal:
Extended:
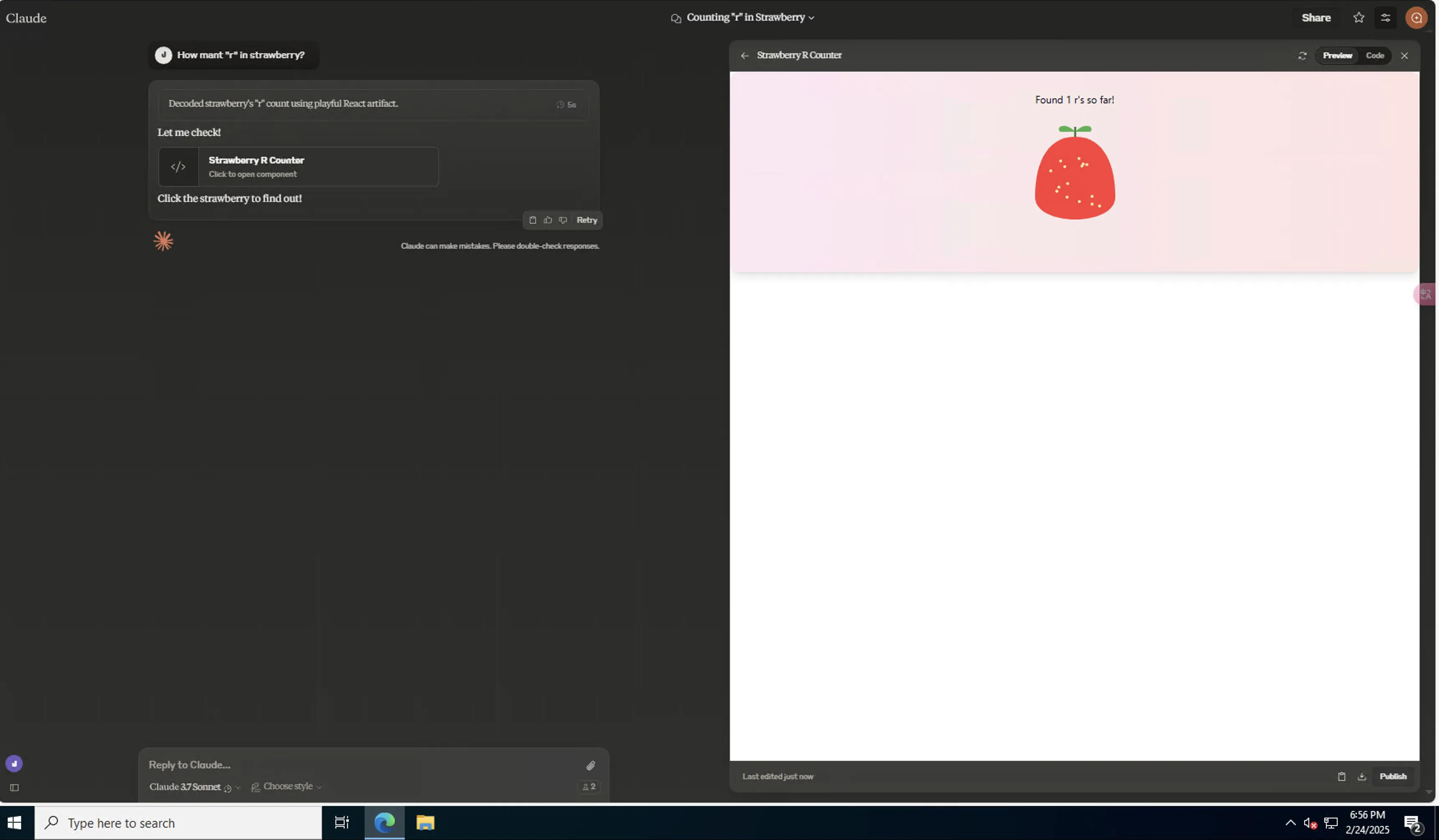
在我的测试中,Normal的前端页面更加棒!
- 旋转小球测试
Normal:
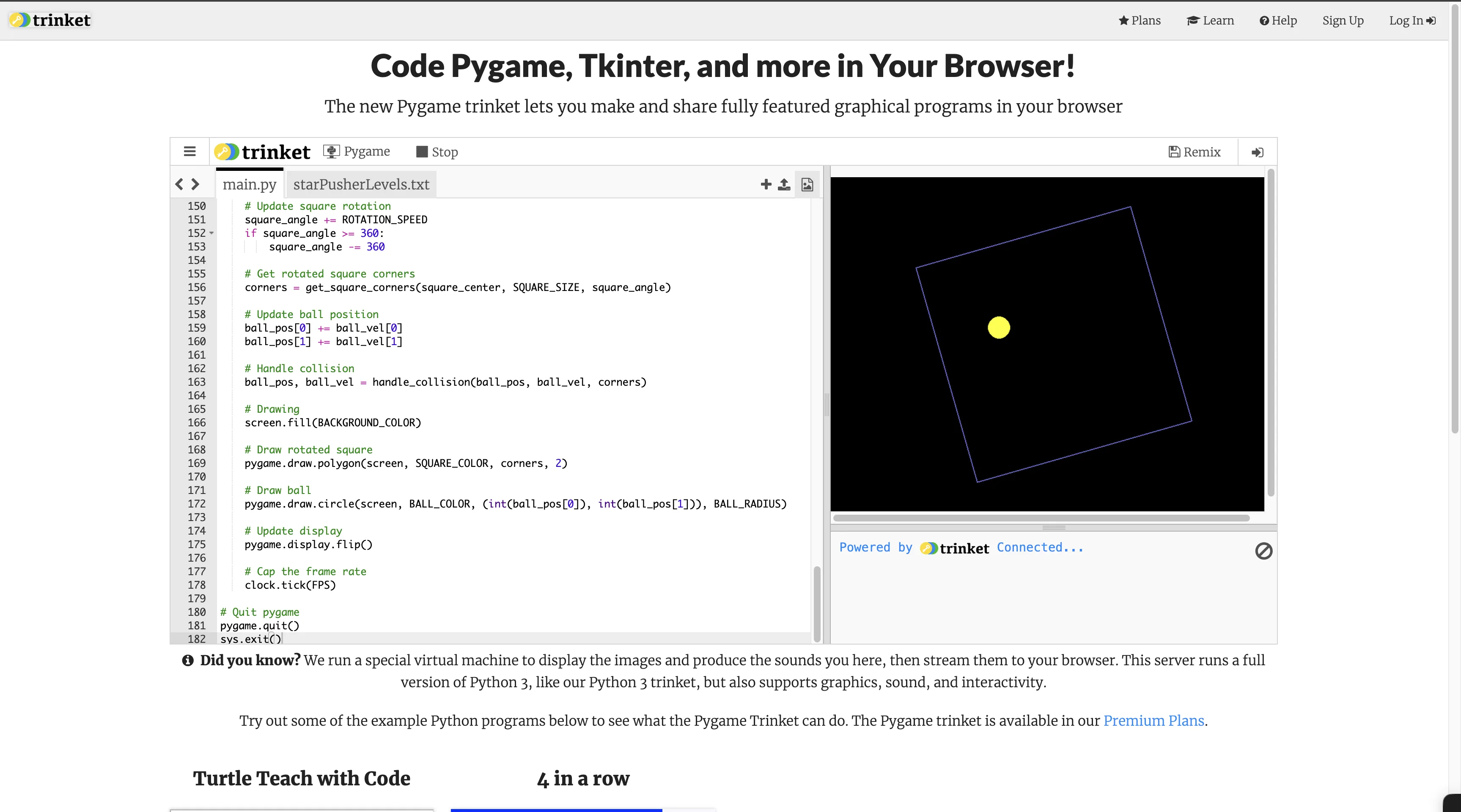
via: https://claude.ai/share/13475764-f78e-4b1b-8be7-9fb438cd540e
Extended:
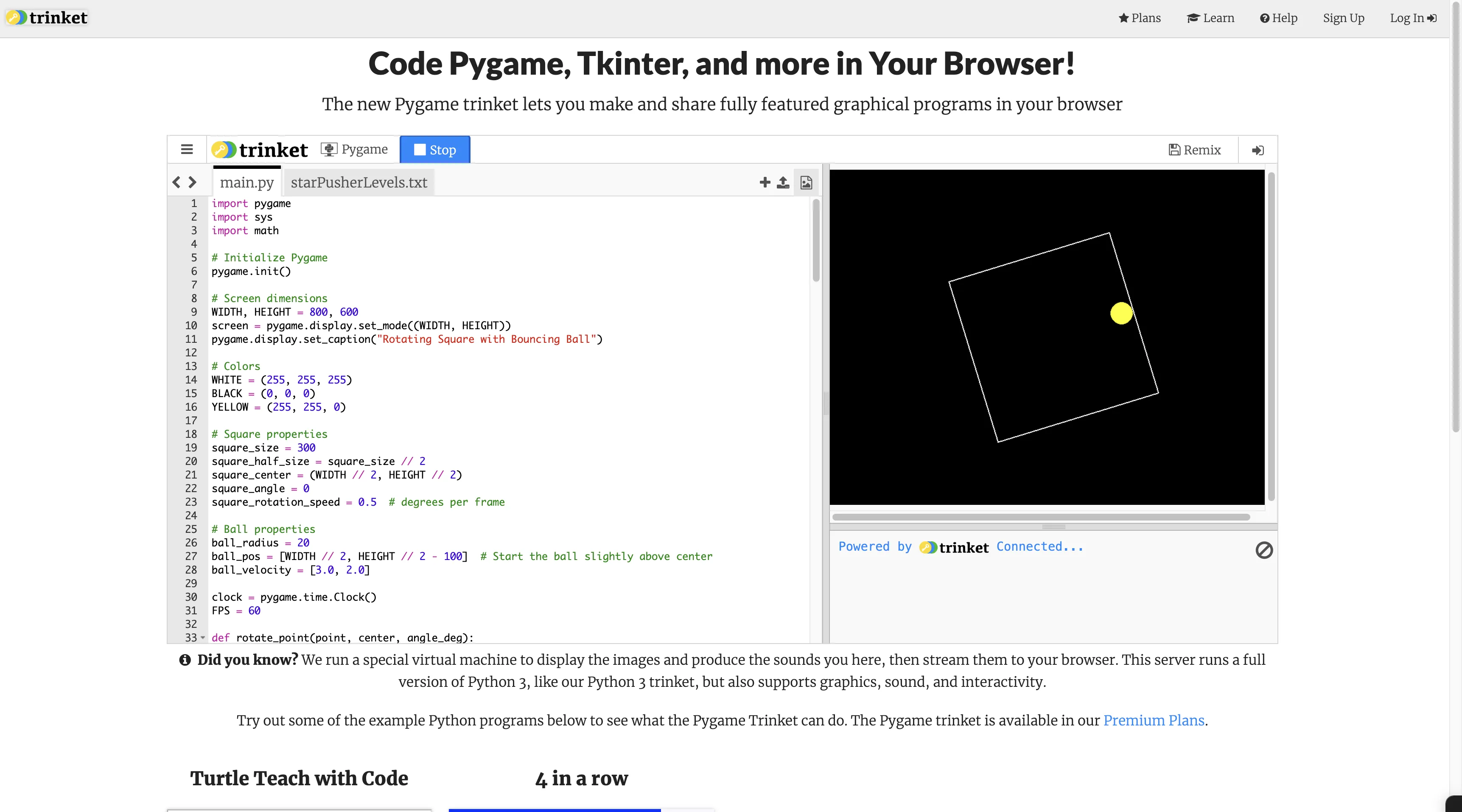
在X上看到有网友说Claude 3.7 Sonnet Extended无法通过旋转小球测试,我测试时是可以通过的。
via: https://claude.ai/share/c5d2f51a-6907-43e7-838e-553b04818de1
pygame在线测试地址: https://trinket.io/features/pygame
- 字母数量测试
Normal:
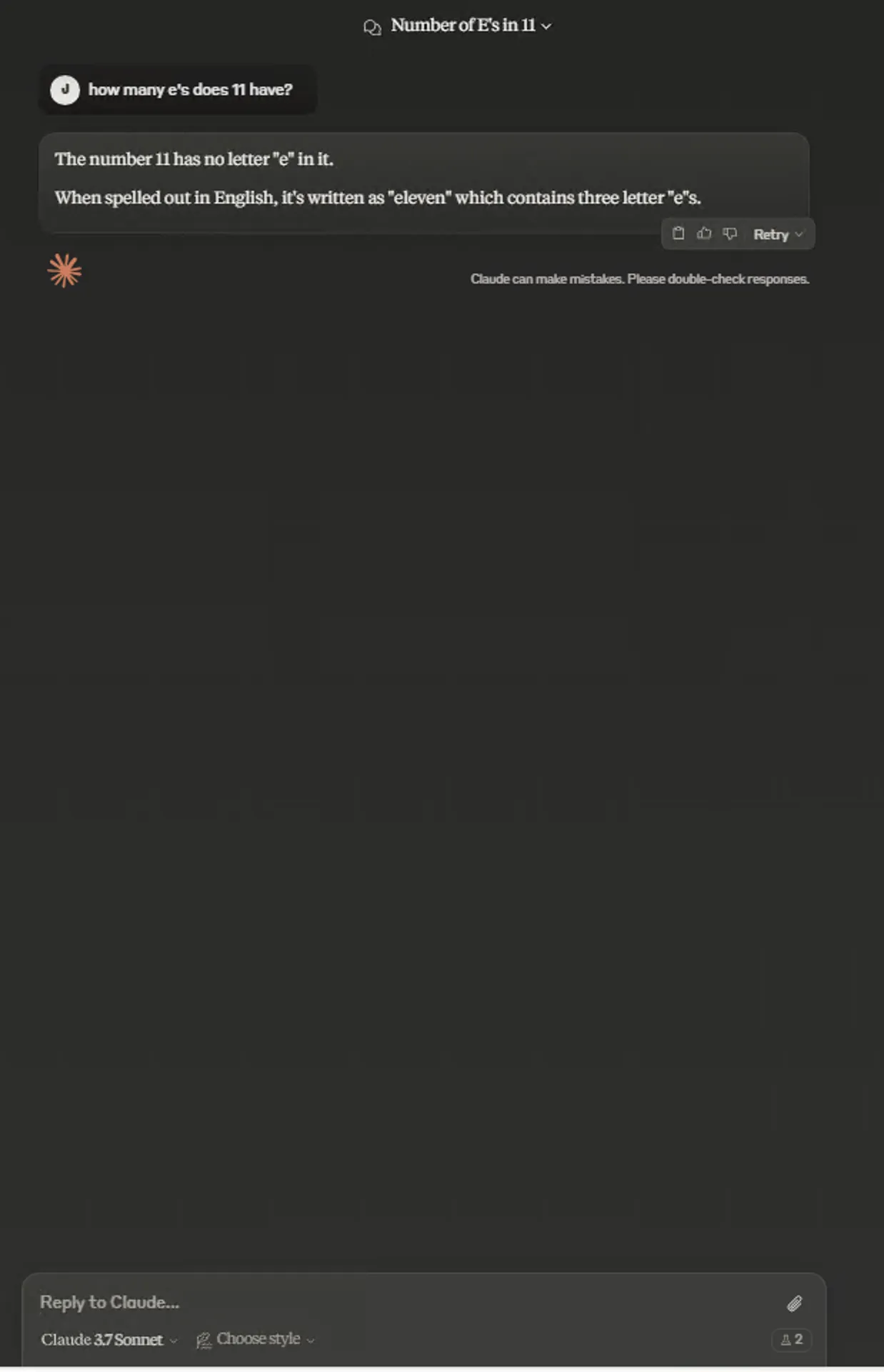
Extended:
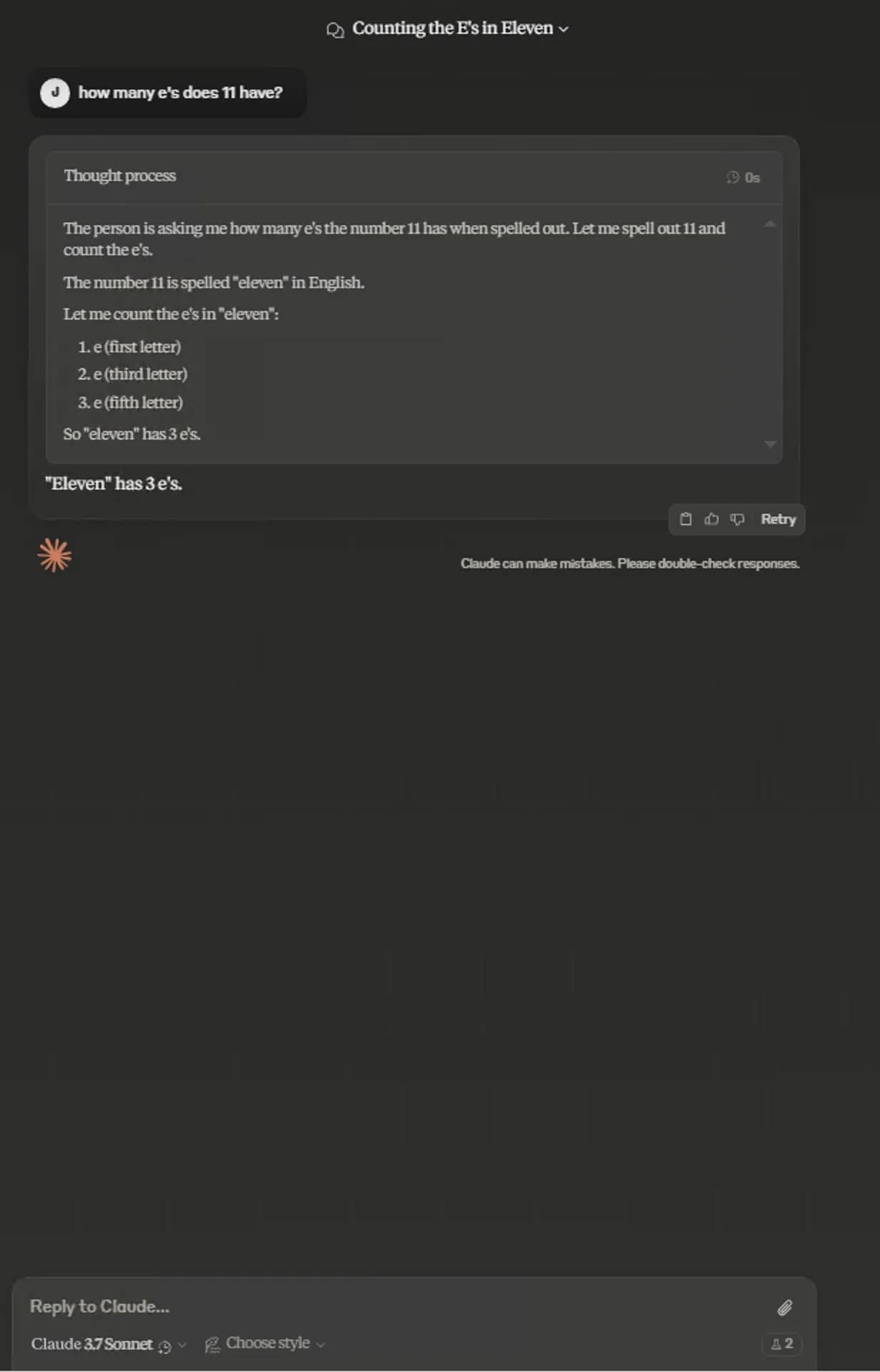
个人主观感觉,这次测试中Normal模式回答这道题目更全面。并不是思考地越多,回答就越好。我用该题目考了考Grok3 Thinking,发现思考3s的回答也很全面,而思考17s的回答类似Claude 3.7 Sonnet Extended。
未来可期的点
- web搜索
前些天还有爆料Claude要集成web搜索的,今天并没有如期上架,如果Claude真得集成了Web搜索,并且优化了Web搜索体验,比如去GitHub项目Issues里面拿准确的解决方案,这绝对对于目前的AI搜索是降维打击,目前我发现Perplexity、Phind这类AI搜索面对代码报错信息,相对于ChatGPT Search、Gemini Google Search、Grok3 DeepSearch,能较为准确地拿到解决方案。
总结
OpenAI可以说已经死了,今早看完了有关Claude新发布的内容,觉得Anthropic会更快地逼近AGI!据说OpenAI本周会发布GPT4.5,如果发布的模型打不过Claude 3.7 Sonnet Normal估计真得快死透了,前几天发布的PDF文档里面包含了遥测分析中国用户使用ChatGPT的行为,使得目前我也只能远程美国Windows,挂美国家宽,对比OpenAI产品【本地手机、电脑、平板上的ChatGPT应用全卸光了】。
OpenAI、Anthropic两家的产品只能远程美国Windows电脑,挂美国家宽用,本地用的安全性太低。降智、封号这些操作一言难尽!
还有别忘了上个月Antropic发布的Citation功能,这个功能为RAG应用提供了显著的价值。
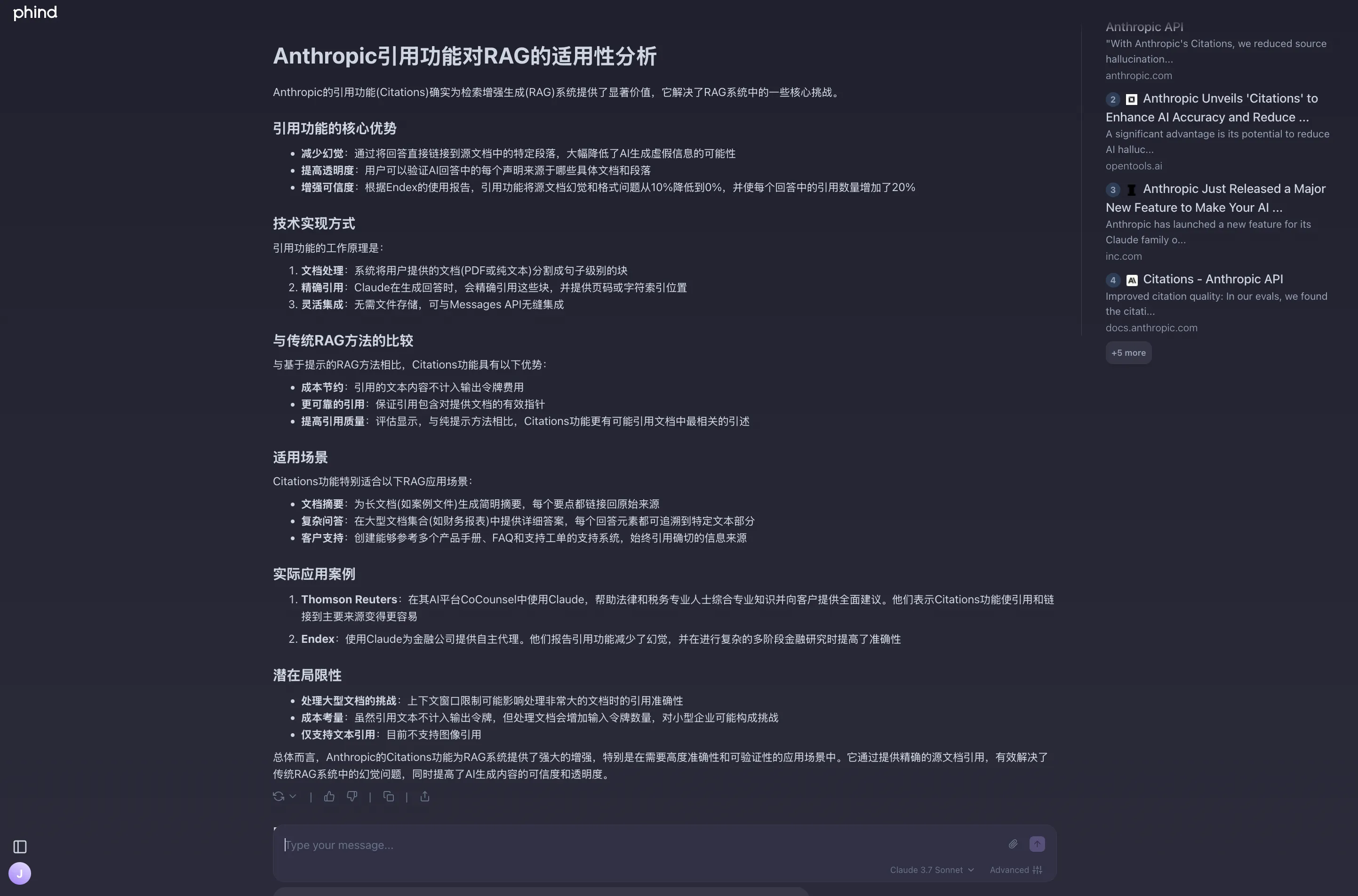
虽然近期Anthropic CEO发布了饱含争议的言论,但我觉得他家的产品确实是最耐打的。记得之前有人因为看不惯其的狰狞面目,退订了Claude Pro,我觉得是不值得的,这反而会让你错失使用最强大AI工具的机会。对于普通人而言,哪家的产品优秀就支持哪家,其余的都和我无关!
从刚才几个简单的案例中可以初见并不是所有的问题都是Extended模式更佳,Normal、Extended两个模式各有千秋,多尝试不同模式,方能找到针对某些问题的最佳Claude 3.7 Sonnet回复。
期待未来Anthropic的web搜索和Claude4!预计会和去年发布时间线类似,下一次发布是在6月底!
补充
一个对话窗口中仅仅只能限定一个Claude 3.7 Sonnet模式,无法实现类似ChatGPT一个对话窗口中可以切换不同模型的操作。
via: https://mp.weixin.qq.com/s/MedDDltDvKWp1uJTGF9yPg
-
https://www.anthropic.com/research/visible-extended-thinking ↩︎
-
https://assets.anthropic.com/m/785e231869ea8b3b/original/claude-3-7-sonnet-system-card.pdf ↩︎
-
https://support.anthropic.com/en/articles/10167454-using-the-github-integration ↩︎
-
https://docs.anthropic.com/en/docs/agents-and-tools/claude-code/overview ↩︎
文档信息
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享4.0许可证)