Gemini 2.0 体验
更新(2025.3.26)
Gemini 2.5 Pro都出来了,看了一些博主测评后,感叹Gemini OCR能力更上一层楼了。
更新(2025.3.19)
昨晚,Gemini App又戳戳戳更新了。via: https://blog.google/products/gemini/gemini-collaboration-features/
- Canvas
类似Claude Artifacts、ChatGPT Canvas的玩意,ChatGPT的Canvas在今年1月份也支持代码的渲染了。
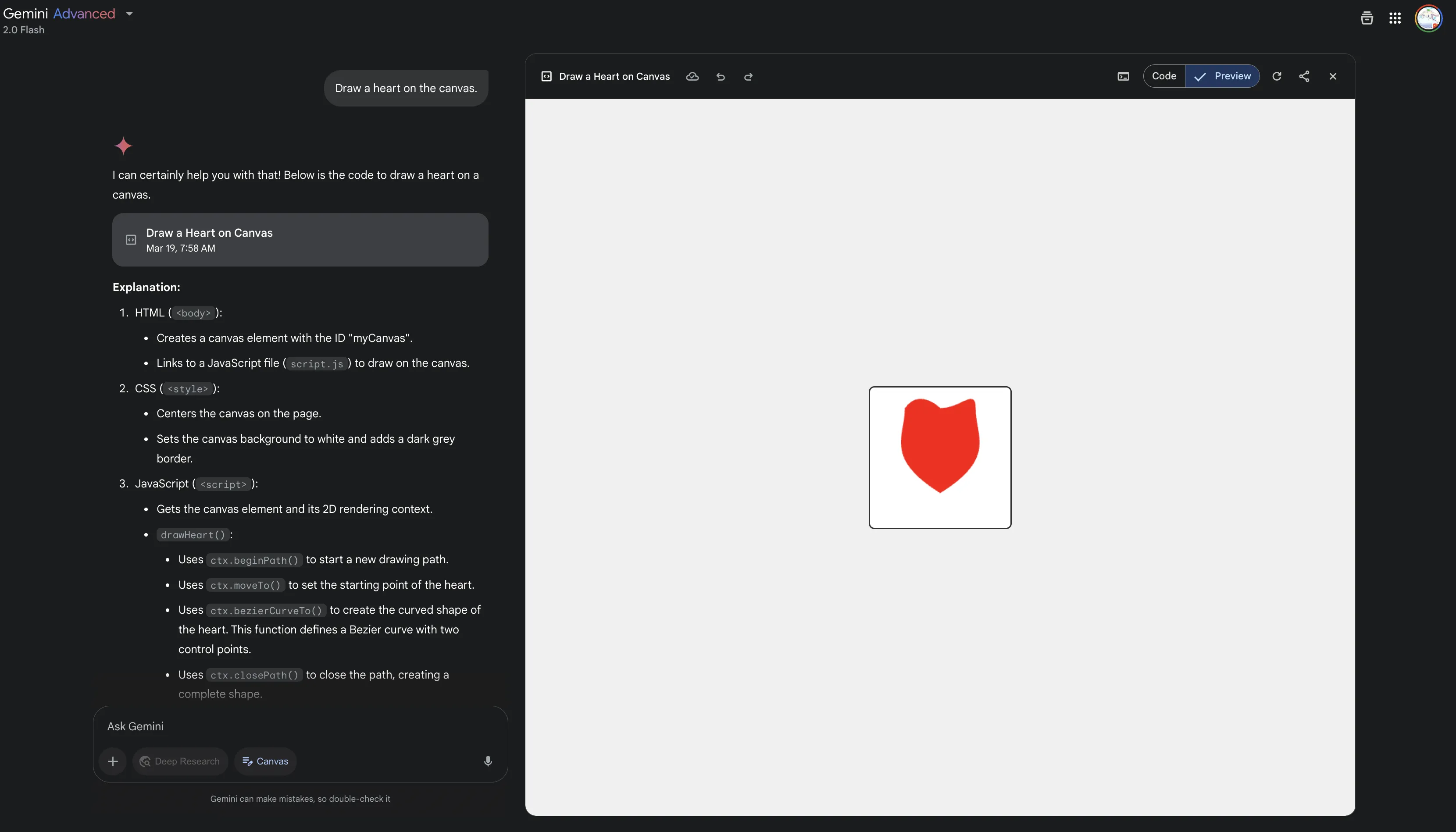
- Audio Overview
给Gemini加入了NotebookLM里面的Audio Overview功能,还是一如既往地只支持英文播客。
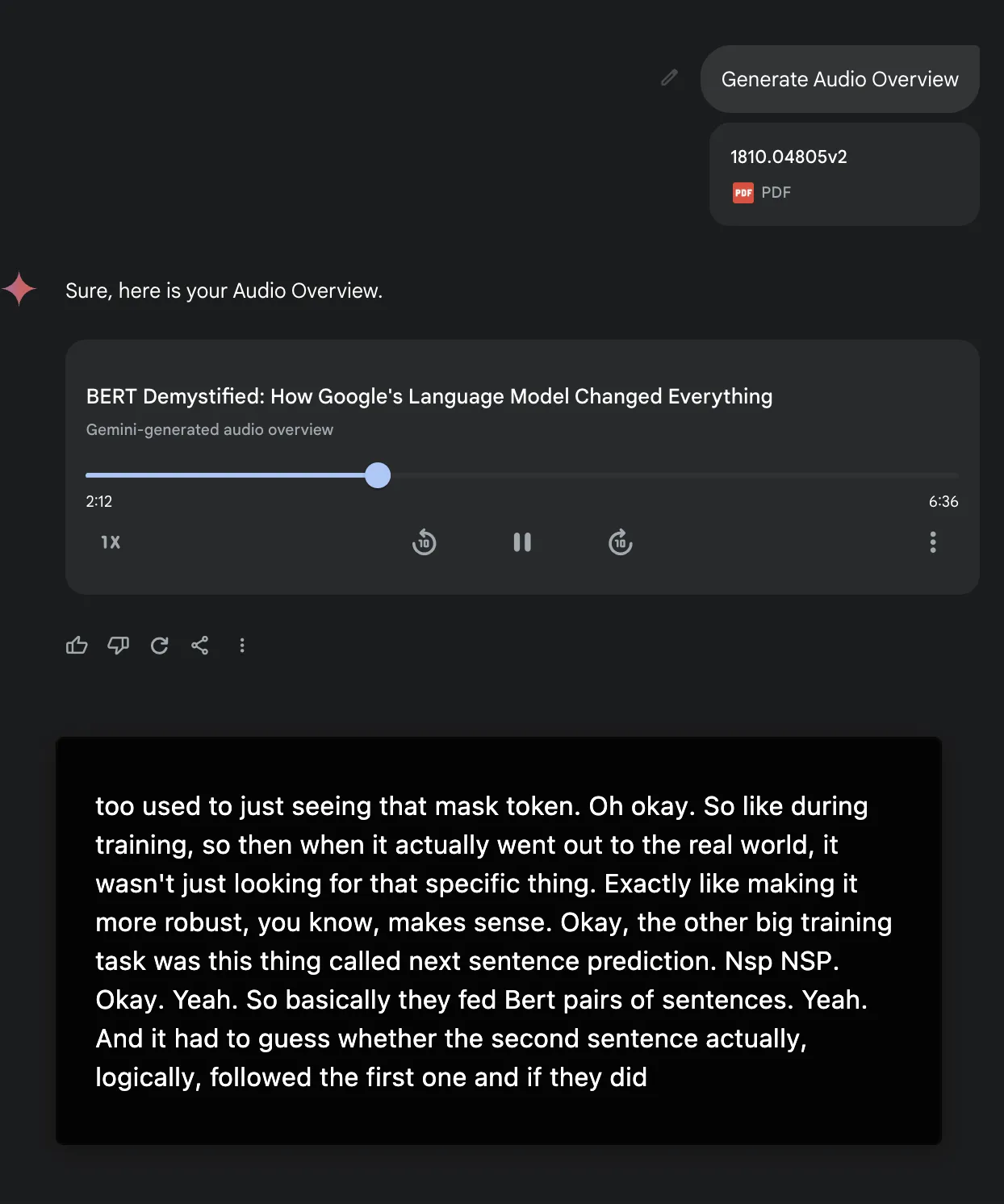
不得不吐槽,为啥Gemini 2.0 Pro还在Exp。Flash模型再加更多的新功能依旧不耐打!预计2.0 Pro在5月份正式蜕去Exp的外衣。
更新(2025.3.14)
昨天晚上,Gemini App更新了Deep Research【免费用户额度由原本的5次/月变更为了10次/月】,将模型由原本的1.5 Pro替换为了2.0 Flash Thinking Experimental。非Advanced用户也能用。目前Advanced用户比免费用户多的一个选项为2.0 Pro Experimental,更聊胜于无了。
Gemini系列模型确实可以完全白嫖,毕竟现在的AI Studio中的2.0 Pro Experimental也支持总结Youtube视频了,而Gemini App中的2.0 Pro Experimental依旧无法与Youtube联动。
Gemini users can try Deep Research a few times a month at no cost. 完全可以白嫖,和Grok一个逻辑,多注册几个账号肯定够用。
更新(2025.3.13)
Google AI Studio添加了对于Youtube视频的支持。
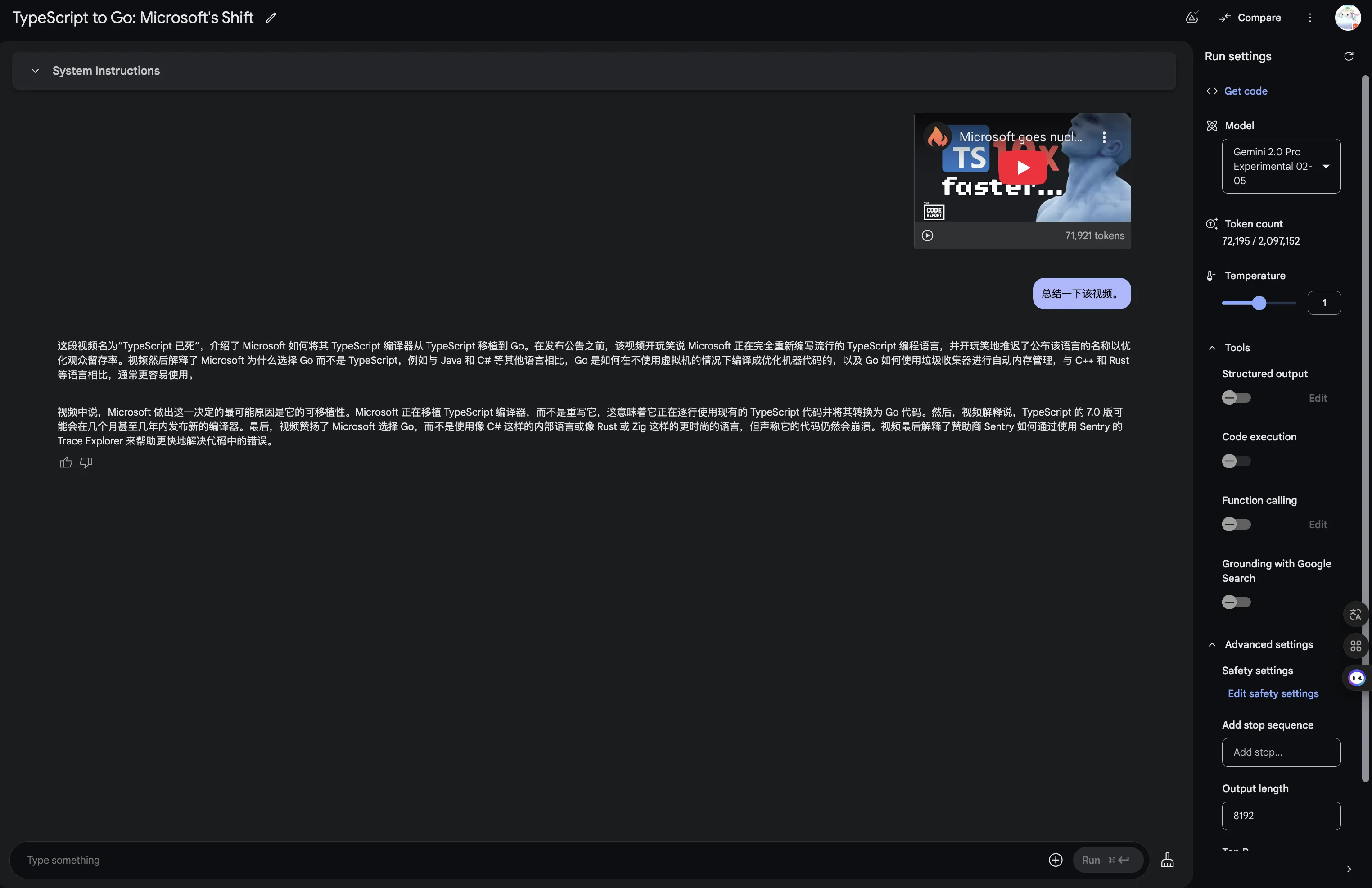
感觉是模型原生的视频理解能力,并不是通过Youtube字幕总结实现的。
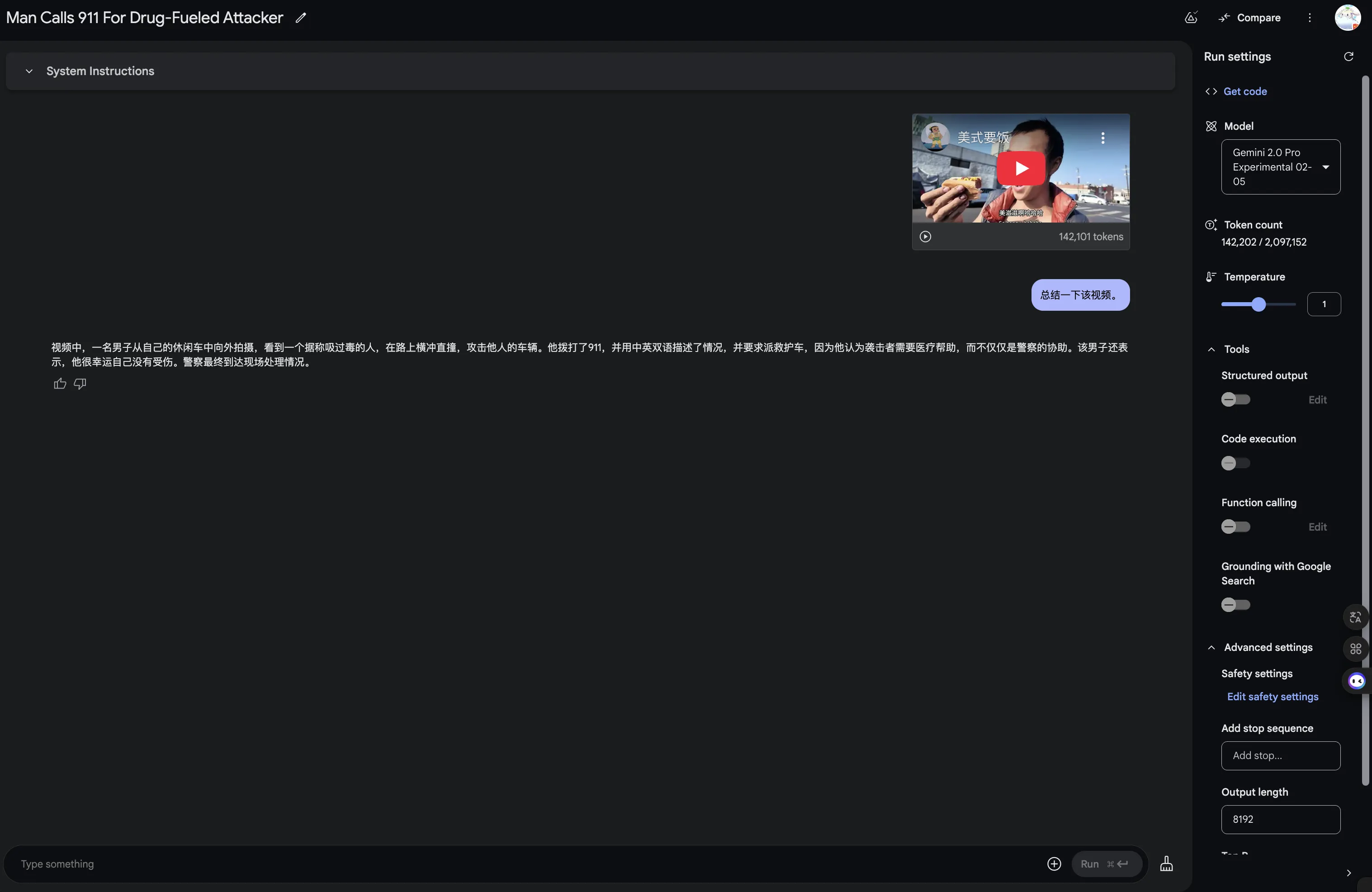
没字幕的Youtube视频也能理解个大概。
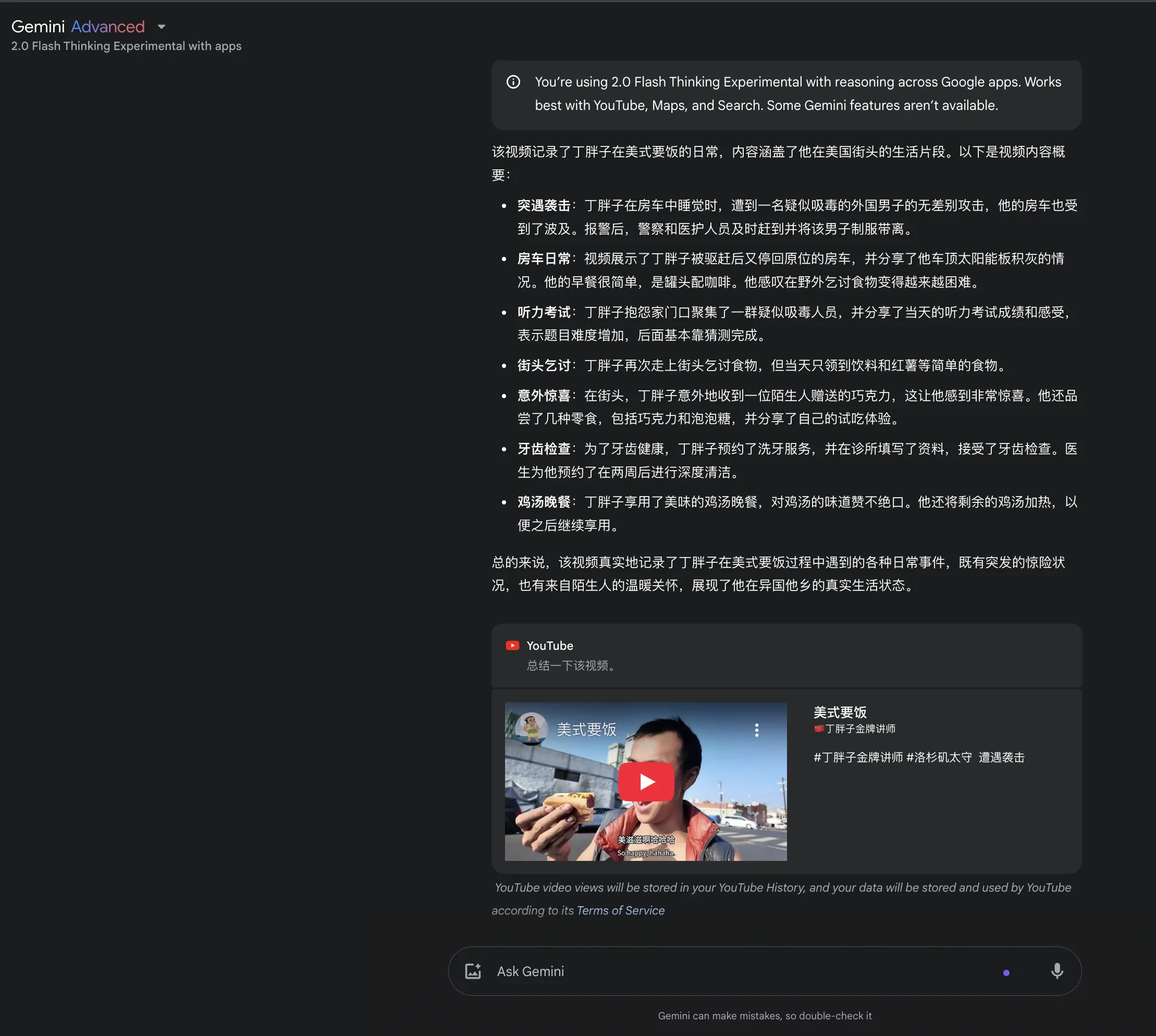
有些时候不禁怀疑,Gemini理解Youtube视频到底是通过字幕,还是纯原生的视频理解能力。关键该视频压根没字幕。反正Youtube属于Google生态,总结视频摘要属于信手拈来的事情。 备注:据负责AI Studio的Logan说是原生的视频理解能力。Native Video Understanding!
没字幕的视频,Monica也能总结。

与此同时,Gemini 2.0 Flash Experimental添加了原生的图片输出!真正的多模态!
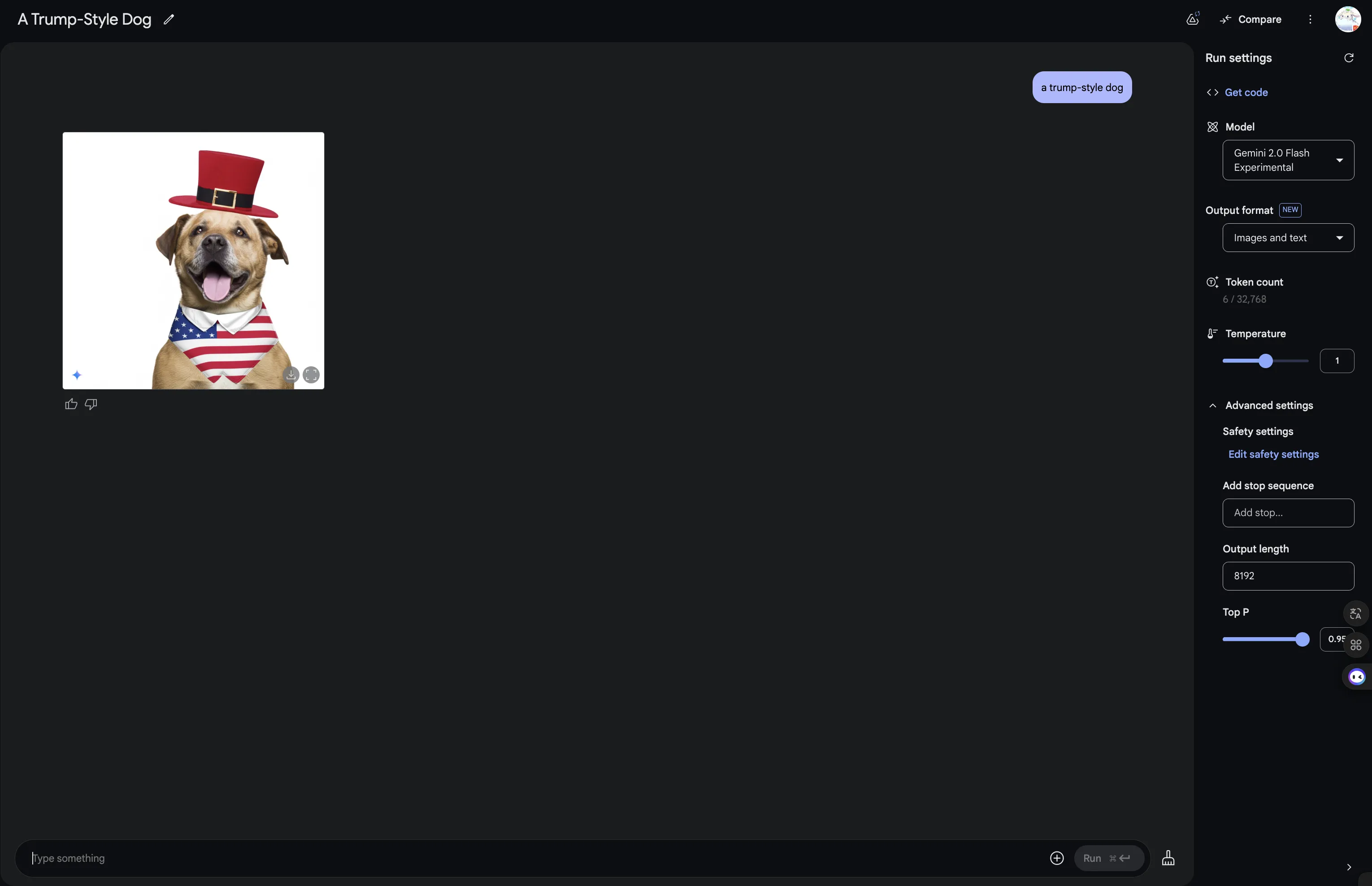
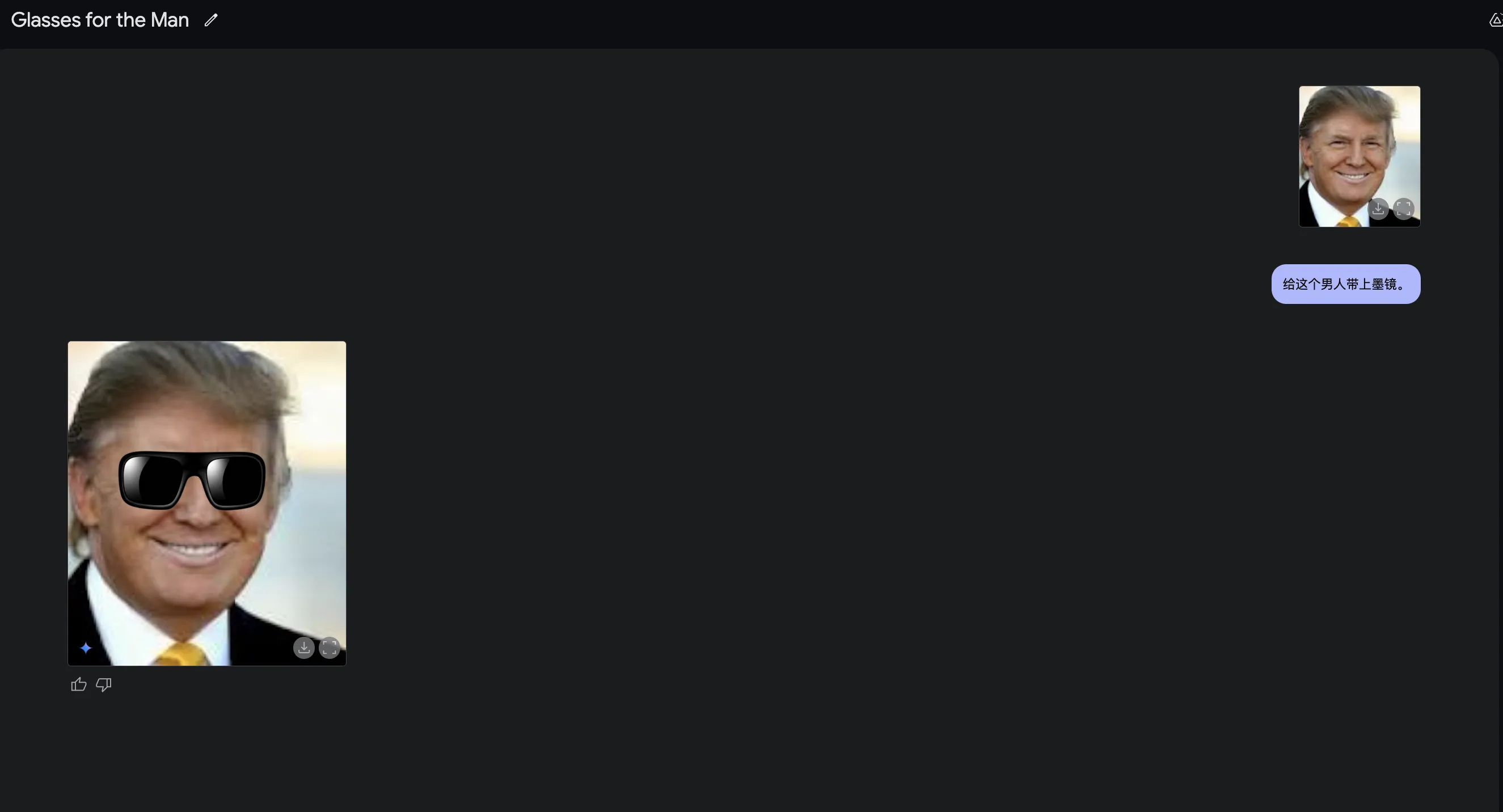
Native Image Output!

更新(2025.3.1)
Gemini总结视频看个大概,2.0 Flash更稳定,推理模型可能有输出俄语、不自动调用Youtube扩展等弊端。
北京时间2025年2月6日凌晨,Gemini 2.0发布了新的更新1。
Gemini App
Gemini 2.0 Flash在API上线。Gemini 2.0 Flash在北京时间2025年1月31日凌晨就已经在App上线。
结合这些天的体验,Gemini 2.0 Flash在App端总结Youtube视频给我的感受是限制在增加,也就是其安全方面做得更激进了。 当然如果都是健康向上、不涉及Trump、有字幕的视频基本上都能概括。
随着昨天的更新,于我而言,总结Youtube视频主力模型已经不再是2.0 Flash或1.5系列模型了,应该选择的模型是 2.0 Flash Thinking Experimental with apps【可联动Youtube、Google Maps、Google Search的推理模型】。
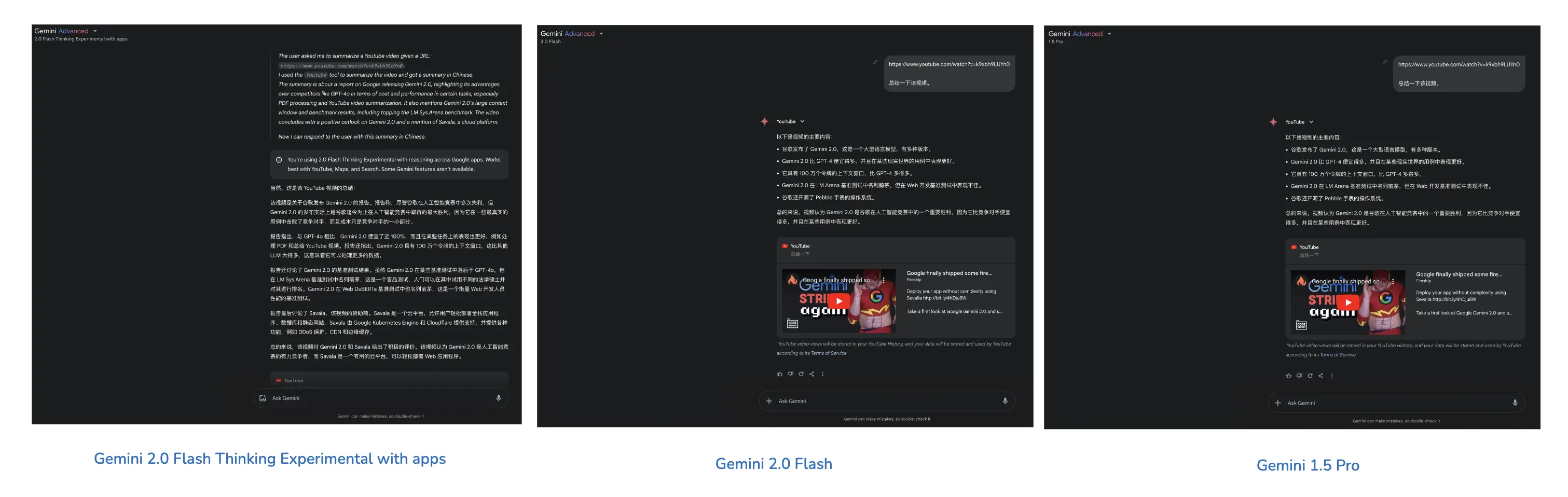
其总结的视频更加详细,如果仅仅是看个视频内容大概,可以选择Gemini 2.0 Flash或1.5 Pro。
其他的App端模型可以忽略,毕竟这些模型都是经过聊天优化的,会损失性能,使用Gemini模型不联动Google全家桶的一些服务建议优先考虑白嫖AI Studio中的模型。
目前为止Gemini Advanced比不开会员多了2.0 Pro Experimental、1.5 Pro with Deep Research、1.5 Pro,聊胜于无。
鼓励大家多用Gemini App总结Youtube视频、在Gemini App中调用Imagen3文生图,免费版就够用了。
Imagen3据说绘图能力较强,并且也已经上线了Gemini API2,付费版API生成一张图片的成本为0.03刀,而在Gemini App中调用则完全免费。
Gemini API
在AI Studio中白嫖的话,优先考虑使用gemini-2.0-pro-exp-02-05模型。
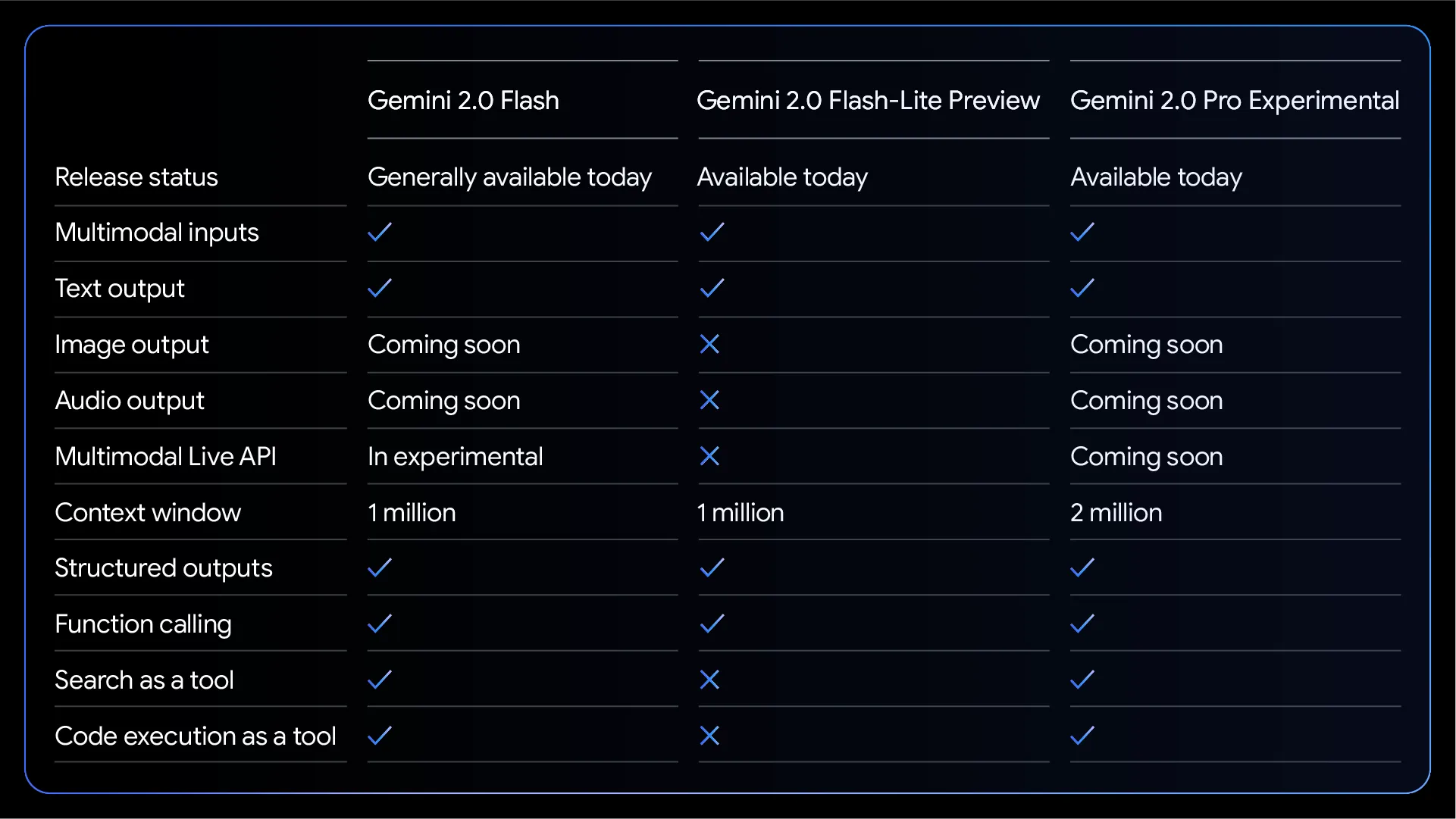
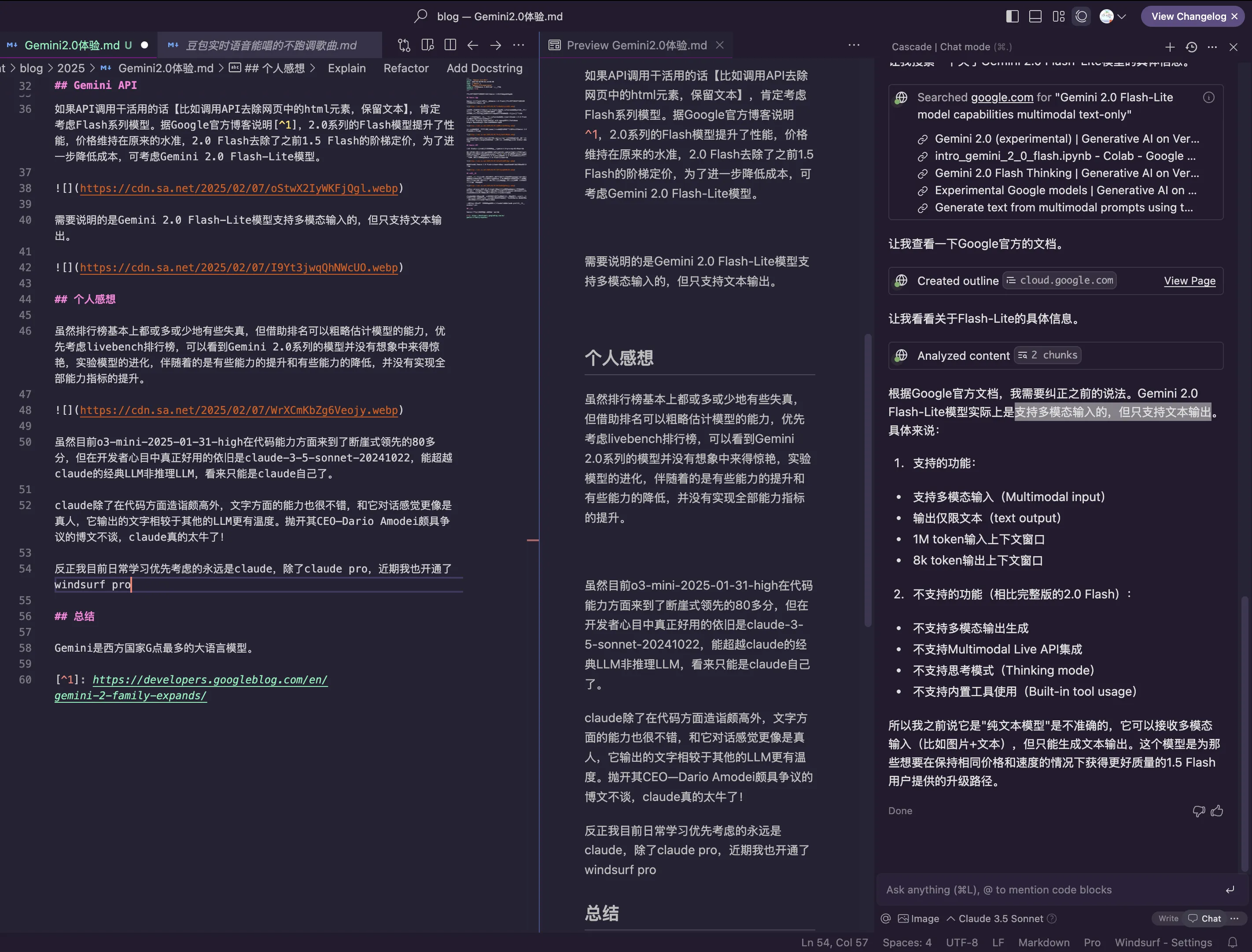
如果API调用干活用的话【比如调用API批量去除网页中的html元素,保留文本】,肯定考虑Flash系列模型。据Google官方博客说明3,2.0系列的Flash模型提升了性能,价格维持在原来的水准,2.0 Flash去除了之前1.5 Flash的阶梯定价,为了进一步降低成本,可考虑Gemini 2.0 Flash-Lite模型。

需要说明的是Gemini 2.0 Flash-Lite模型支持多模态输入的,但只支持文本输出。
排行榜及体会
虽然排行榜基本上都或多或少地有些失真,但借助排名可以粗略估计模型的能力,优先考虑livebench排行榜,可以看到Gemini 2.0系列的模型并没有想象中来得惊艳,实验模型的进化,伴随着的是有些能力的提升和有些能力的降低,并没有实现全部能力指标的提升。
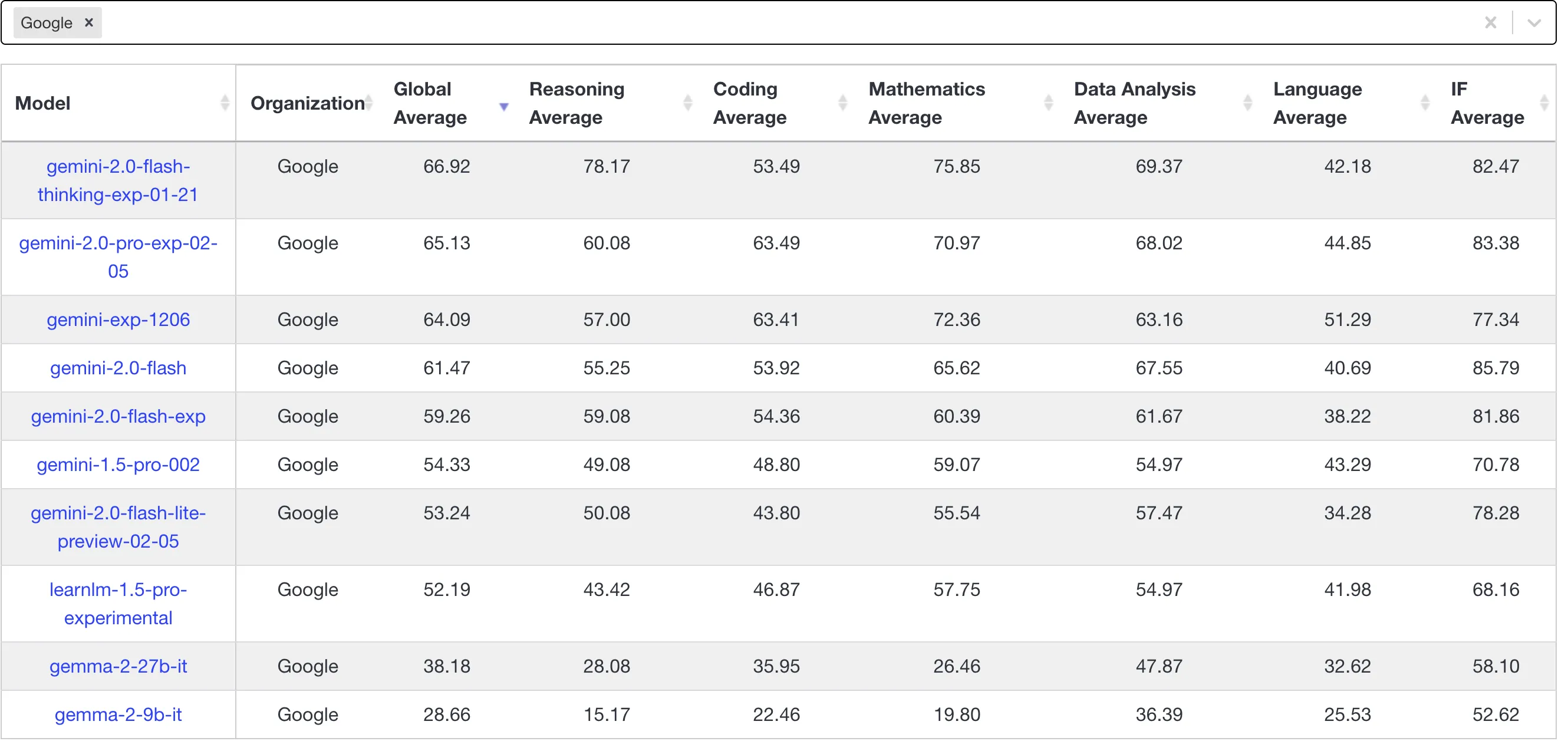
目前o3-mini-2025-01-31-high在代码能力方面来到了断崖式领先的80多分,但在开发者心目中真正好用的依旧是claude-3-5-sonnet-20241022,能超越claude的经典LLM非推理LLM,看来只能是claude自己了。
claude除了在代码方面造诣颇高外,文字方面的能力也很不错,和它对话感觉更像是真人,它输出的文字相较于其他的LLM更有温度,除了有些懒。抛开其CEO—Dario Amodei颇具争议的博文不谈,claude真的太牛了!
我目前日常学习优先考虑的永远是claude,除了claude pro,近期我也开通了windsurf pro,cascade这个ai agent使用体验较好,而且成本相较于cursor的20刀/月更低。
个人感想
Gemini系列模型,我的使用场景:
- App总结Youtube视频
Gemini App对我而言主要是总结Youtube视频,除非视频足够吸引我或者是实操类的视频,不然我更愿意用Gemini总结节约我时间。
- Flash系列模型生产中用
在生产中处理数据,可使用Flash模型实现最高的性价比,最近看到一篇名为《Ingesting Millions of PDFs and why Gemini 2.0 Changes Everything》4 5的博文,作者指出Gemini 2.0 Flash在成本效益上表现突出, OCR准确率近乎完美且价格低廉。
- Glarity Chrome扩展中使用Flash模型总结网页文章
每天使用Page Summary的次数在10~20次左右。一个月的成本很低,2025年1月份Gemini API的GCP账单费用为0.06刀。

虽然目前有很多免费的网页总结扩展,但我还是更倾向于用Gemini Flash系列模型总结,毕竟其上下文窗口大,而且成本也很低。
- …
Gemini宣称的上下文窗口较大,我使用了这么长时间的Gemini还没有哪一次对话超出该窗口的情况,这方面不好评价。大的上下文窗口表面上利好RAG,但其实上下文窗口并不是越大越好,容纳的东西越多也意味着噪声越多。
Gemini模型的视觉能力很强,上个学期使用Gemini提取图片新闻里面的汉字,一张挤满了多条新闻的图片,Gemini几乎将其中的汉字全部识别出来了,多模态能力确实强。
等到Project Astro正式推出时,估计能给我带来更多惊喜。
总结
Gemini模型现阶段可圈可点,平时多和其他模型对比使用,方能更好地发现其优势和不足。Google系列模型强就强在和它的全家桶集成较好,生态是Gemini独有的。
Gemini绝对是一款被低估的模型,不要因为Google Bard在2023年的捉襟见肘,而忽视了其在2024年、2025年的逐步变好。从Bard更名为Gemini,是一次成功的品牌变更,其试图摆脱Bard的负面形象,而Gemini系列模型的一次次更新确实证明了Google的实力。
面对DeepSeek爆火的当下,可能你会问日常难道不用DeepSeek?
个人认为DeepSeek确实有东西,但并不意味着已经天下无敌,完全实现了东升西降!只能说是开源逼近闭源6,就比如DeepSeek目前欠缺的有多模态,实时语音方面落后豆包等一众模型。

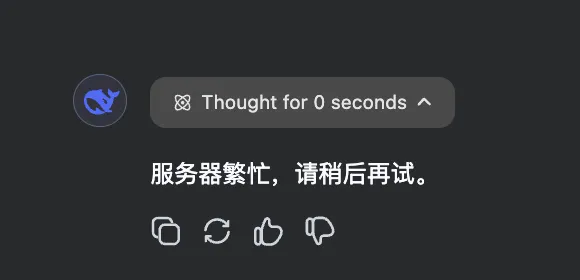
而且近期DeepSeek的爆火已经使得其服务不堪重负,如果仅仅是调用R1 API,总感觉差点意思,R1+搜索才能实现最佳的DeepSeek体验,准备等深度求索服务稳定了再加入我的日常LLM询问选项,不然问一个问题后,就直接服务器繁忙的,很影响体验。
-
https://blog.google/technology/google-deepmind/gemini-model-updates-february-2025/ ↩︎
-
https://developers.googleblog.com/en/imagen-3-arrives-in-the-gemini-api/ ↩︎
-
https://developers.googleblog.com/en/gemini-2-family-expands/ ↩︎
-
https://www.linkedin.com/posts/yann-lecun_to-people-who-see-the-performance-of-deepseek-activity-7288591087751884800-I3sN ↩︎
文档信息
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享4.0许可证)