Claude 3.7 Sonnet Experience
Update (2025.7.23)
Claude Code is no longer a toy. With Claude 4 series models online, Max membership paired with Opus 4 model is just too good. Those who know, know—the strongest AI programming tool!!! In just 1-2 months, successfully turned Cursor from sweetheart to has-been. Only Anthropic entering the arena could do this.
Update (2025.4.29)
Don’t underestimate Claude. Currently Gemini 2.5 Pro, o3 are indeed impressive, but I still haven’t abandoned Claude for programming and writing. For polishing article expression, I still prefer Claude [premise: the text to polish has been roughly expressed clearly, minor details might read awkwardly, then using Claude for polishing definitely achieves excellent results].
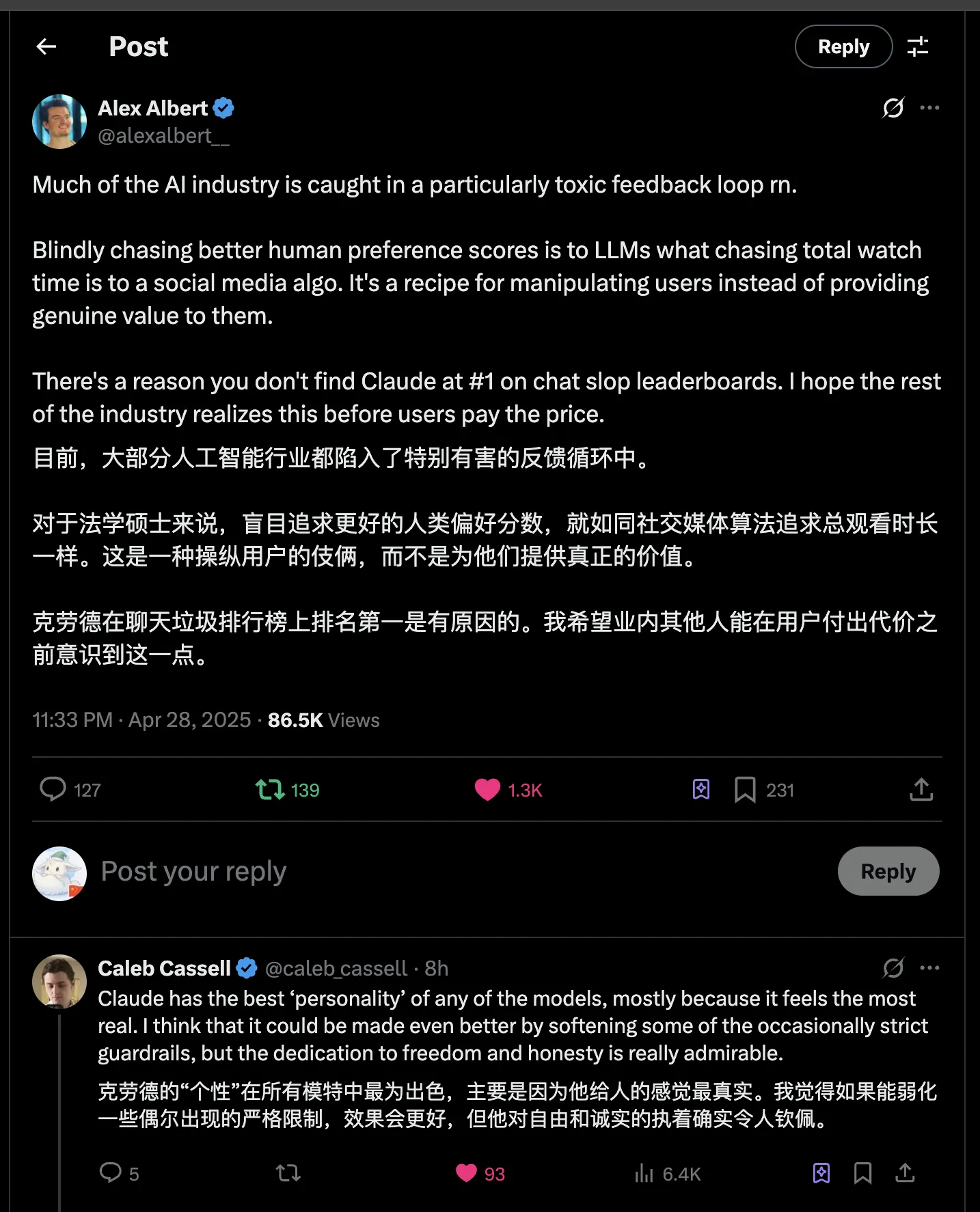
via: https://x.com/alexalbert__/status/1916878483390869612
Update (2025.4.20)
Can’t fully embrace Claude either, but can’t underestimate Claude. Current LLMs are truly dazzling—sometimes don’t know which model to use. Because I personally have strong Claude inertia, yesterday I wrote Claude-praising content, but recent Gemini 2.5 Pro, ChatGPT o3, o4-mini series updates are also really top—all SOTA. Having choice paralysis.
Update (2025.4.19)
Recently o3 guessing image locations went viral. But besides image guessing, the rest feels below expectations. Like code comments—I somewhat miss o3-mini-high. Current tool-using o3 or o4-mini-high has insufficient thinking time—code comment quality worse than original o3-mini-high.
Whenever I learn new knowledge, I still first consider Claude. Gemini 2.5 Pro can’t achieve Claude’s rich yet not overly verbose communication experience. Claude sometimes has excellent generalization (so-called soul)—incisive replies to questions feel surprising yet expected. Though I compare all current LLMs, overall after getting used to Claude’s reply style, so far no LLM catches my eye. No matter how Gemini 2.5 Pro, o3, o4-mini-high dominate benchmarks, my heart always belongs to Claude.

Update (2025.3.25)
Productivity still needs ChatGPT and Claude. The “OpenAI is dead” statement in the article was purely joking. For code comments, I still prefer OpenAI’s o3-mini-high model. Plus the newly released GPT-4.5 has better replies for some concept explanations.
Update (2025.3.21)
Claude supports Web Search now. via: https://www.anthropic.com/news/web-search.
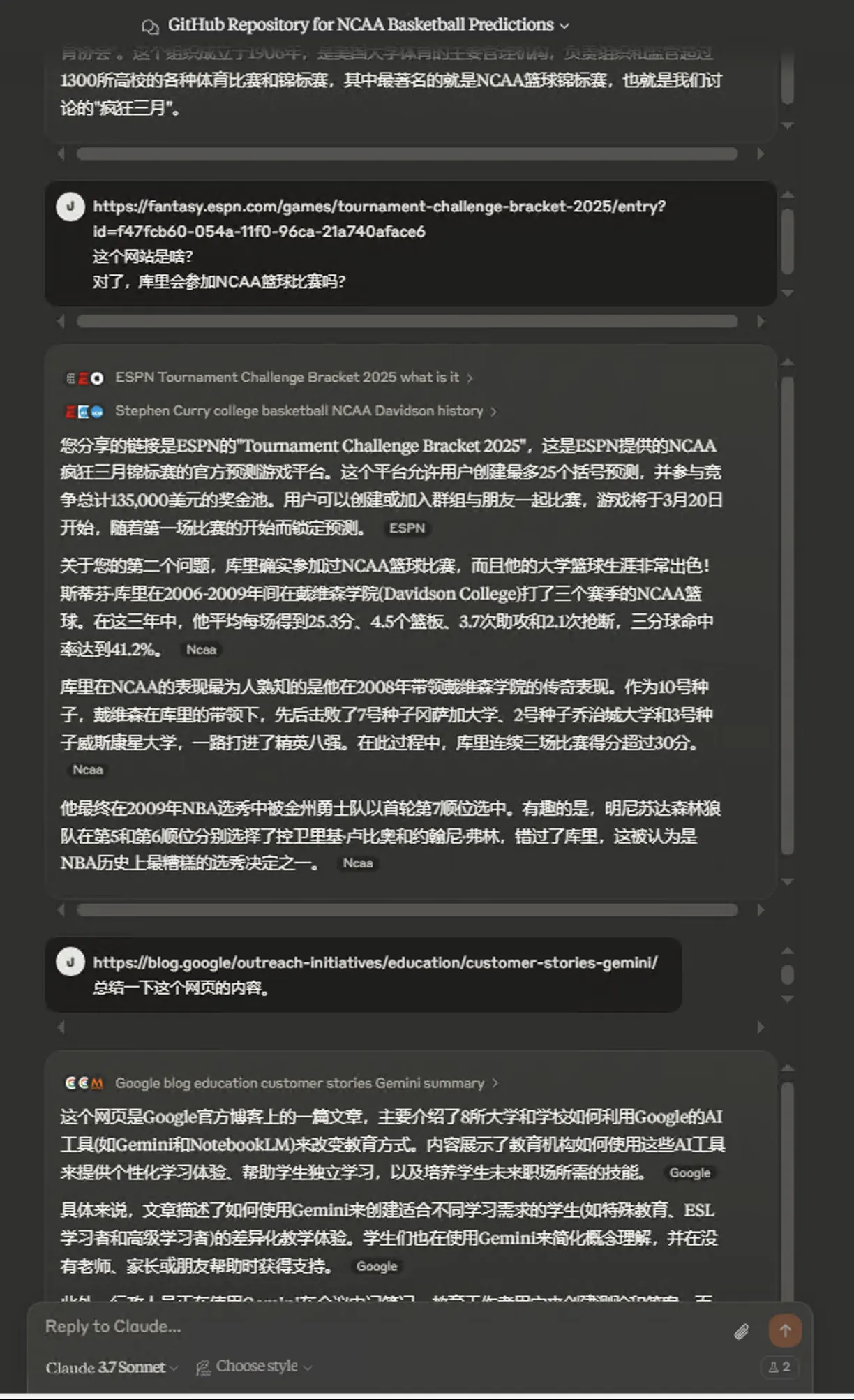
Probably a big blow to AI search wrapper market. I previously used Perplexity and other AI searches mainly because they support Claude model.
These AI search wrappers might have advantages over Claude native search in some areas. Compare and use both to better understand their pros and cons.
Update (2025.3.1)
Recommend prioritizing Normal mode. Extended thinking mode only when Normal can’t solve. Reasoning models excel at: math, coding, logic. In other areas, reasoning models can’t beat classic LLMs. For example, having Claude write—Extended mode definitely performs worse, less creative text than Normal mode. Same logic for other LLMs—prioritize classic LLM, only consider reasoning models when classic LLM can’t solve.
Programming ability is absolutely far ahead. Had Claude 3.7 Sonnet write a script calling MinerU’s API to implement PDF-to-Markdown—done in just a few conversation rounds! Error analysis, Artifact Making Edits, etc.—just too impressive! Enjoying Vibe Coding.
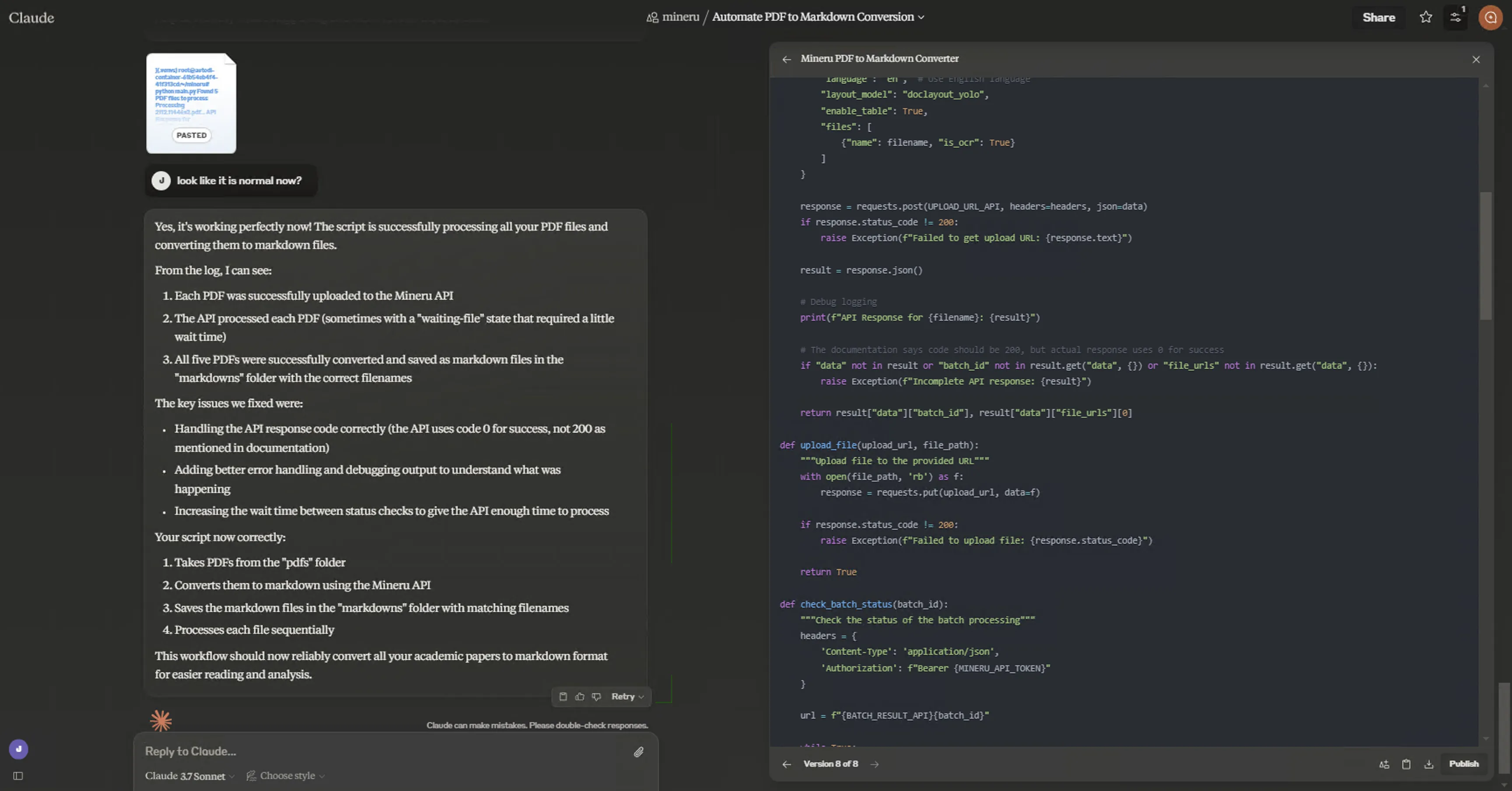
Update (2025.2.26)
Claude Code is totally a toy. Yesterday saw a blogger use Claude Code to add new Features to their project. I don’t have good ideas either—randomly had Claude Code make a Hungry Bear. Natural language programming took over 1 hour—feels inferior to Cursor, Windsurf and other AI editors. Still need to learn programming properly. Natural language programming process is extremely difficult. The more tech you know, plus Claude assistance, the better you can hit targets!
Anthropic official Twitch livestream of Claude playing Pokemon: https://www.twitch.tv/claudeplayspokemon
Update (2025.2.25)
Netizen comment: “If you know coding, Claude will make you a coding god!”
Another case update: generating Gomoku game

Played several rounds, never could win. Claude 3.7 Sonnet Thinking-designed game is impressive!
via: https://claude.site/artifacts/16727408-f553-41da-aaa5-bbb27e47301d
February 24, 2025 [February 25, 2025 Beijing time midnight] Claude 3.7 Sonnet emerged—the true far-ahead arrived on earth!
Update Content
First look at official News main content1. This time chose Phind’s Claude 3.7 Sonnet for summarizing.

After carefully reading the News, feeling was shock!
My question: Official News claims Claude 3.7 Sonnet is the market’s first hybrid reasoning model?
Phind and Grok3 DeepSearch thoughts:
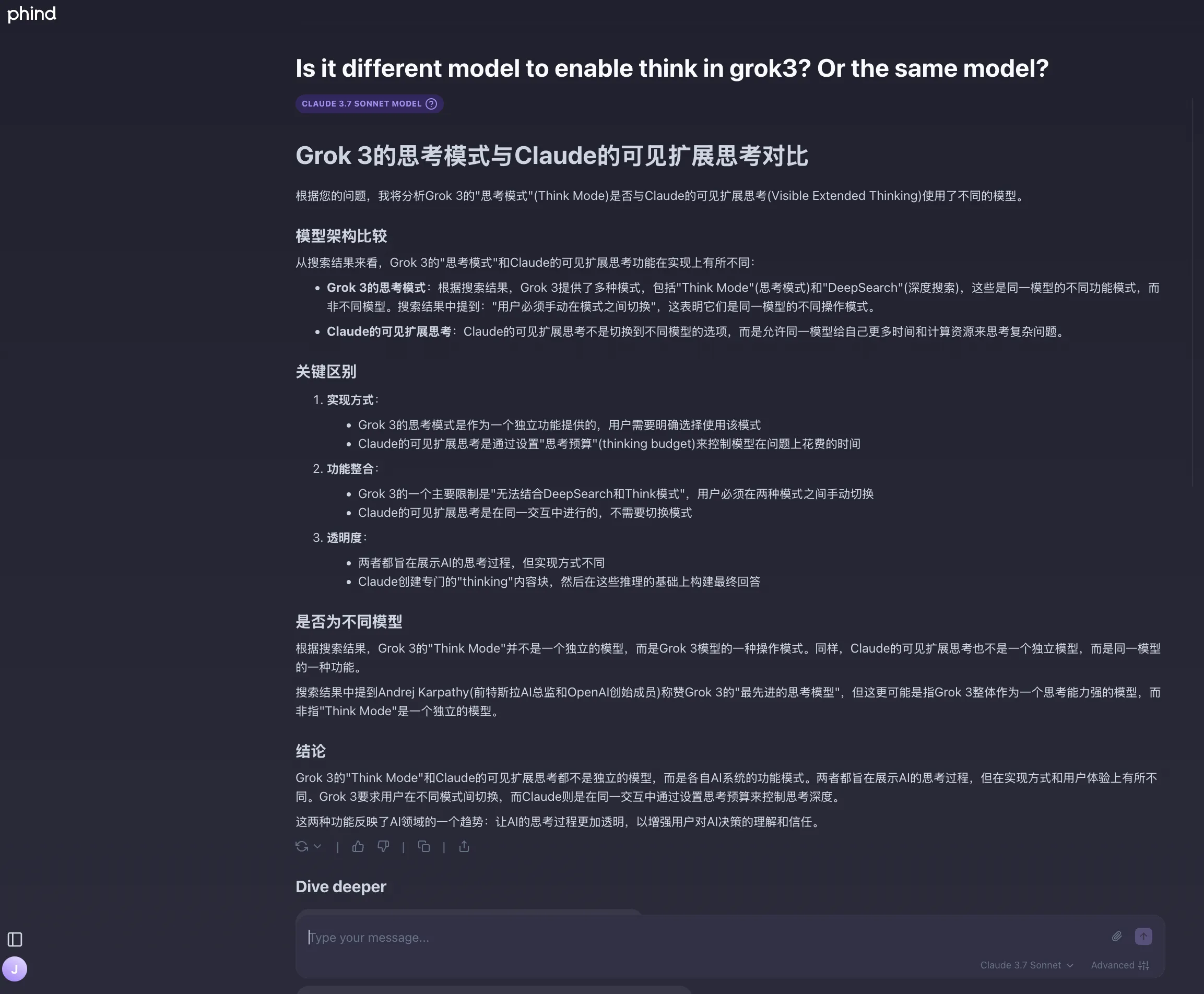
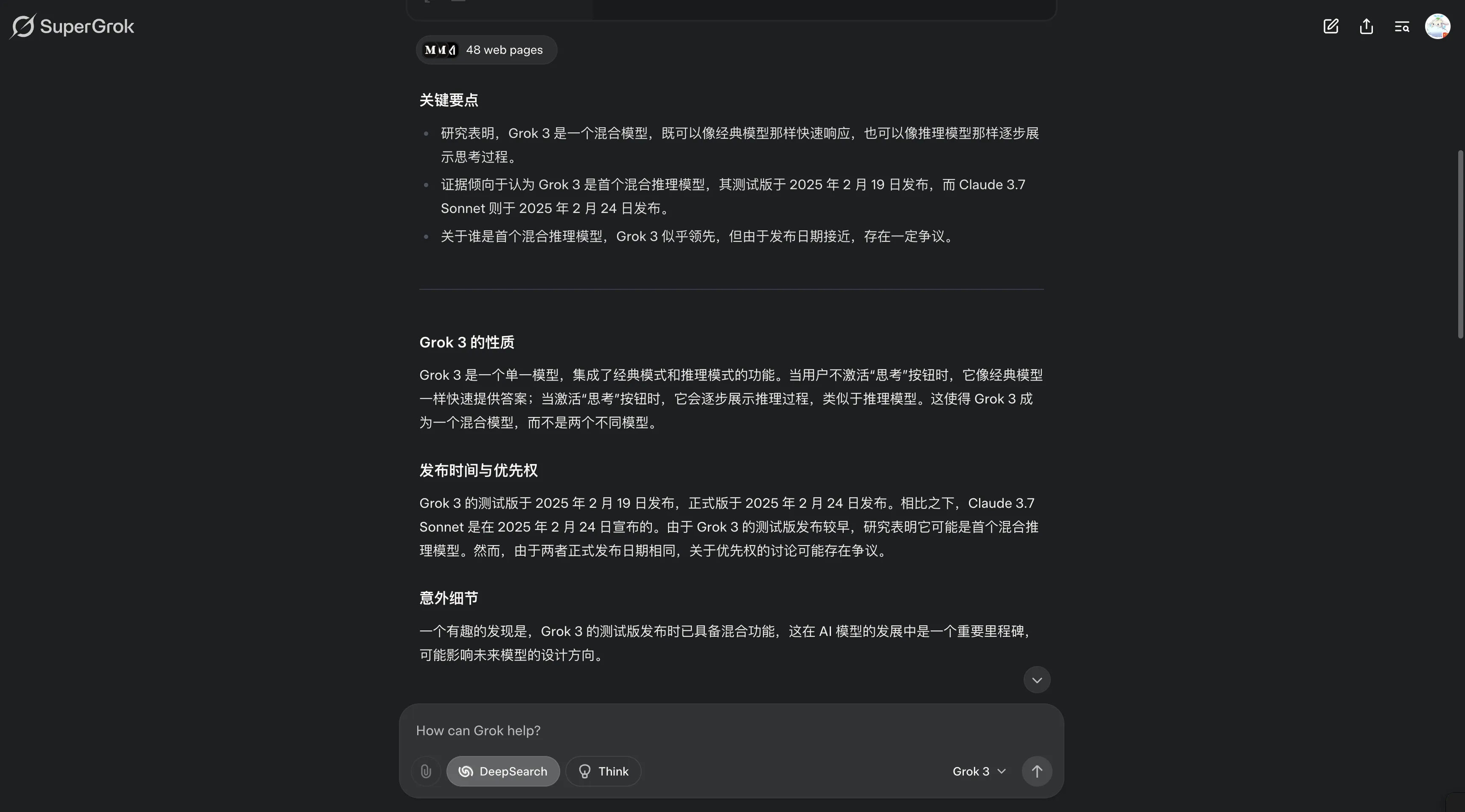
Personally lean toward thinking first hybrid reasoning model should be Grok3—after all, clicking Think button makes Grok3 think before replying. DeepSeek and others’ reasoning models are new models. Maybe my understanding is wrong since this view is still controversial.
Official research blog—Claude’s extended thinking2, Phind summary:


Differences from previous reasoning models:

Claude 3.7 System Card3, Claude 3.7 Sonnet Extended summary:

- GitHub Integration4
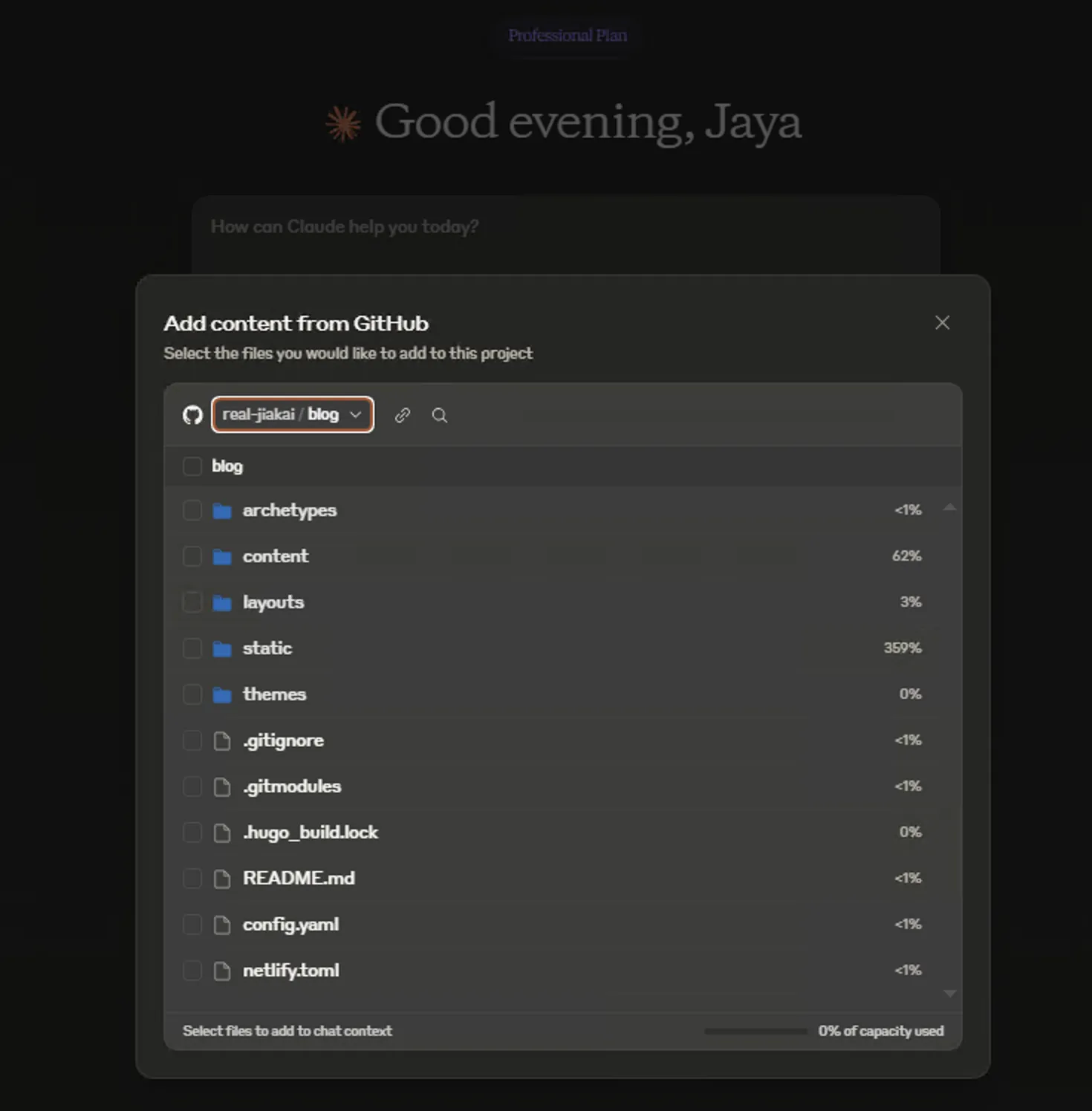
Select files/folders directly to add corresponding content to Chat. If a GitHub project is critical for your business but code is hard to understand, or code needs new features, can add corresponding code parts to Claude Chat this way and have Claude strategize! Tested—private repos work too, provided Claude For Github App has read permissions for relevant repos.
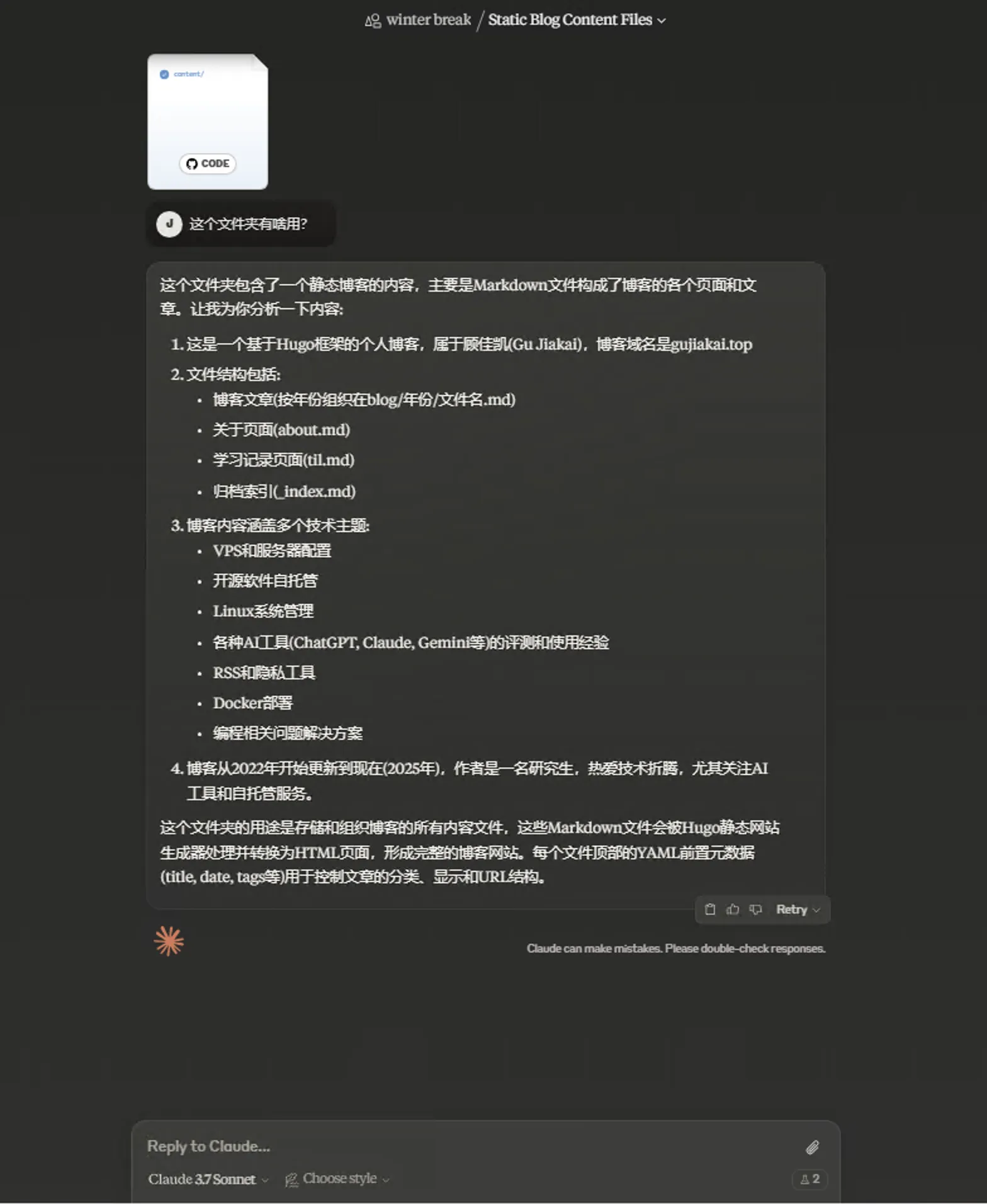
But thinking carefully—my blog content folder is 400+ KB, already occupying 62% of capacity limit. And in one conversation, can’t add more GitHub files—only at initial stage. Still somewhat limited. Plus it only gives text explanations or hints for code—can’t operate the code. For this, still need Cursor, Windsurf and other AI code editors for better global perception and editing.
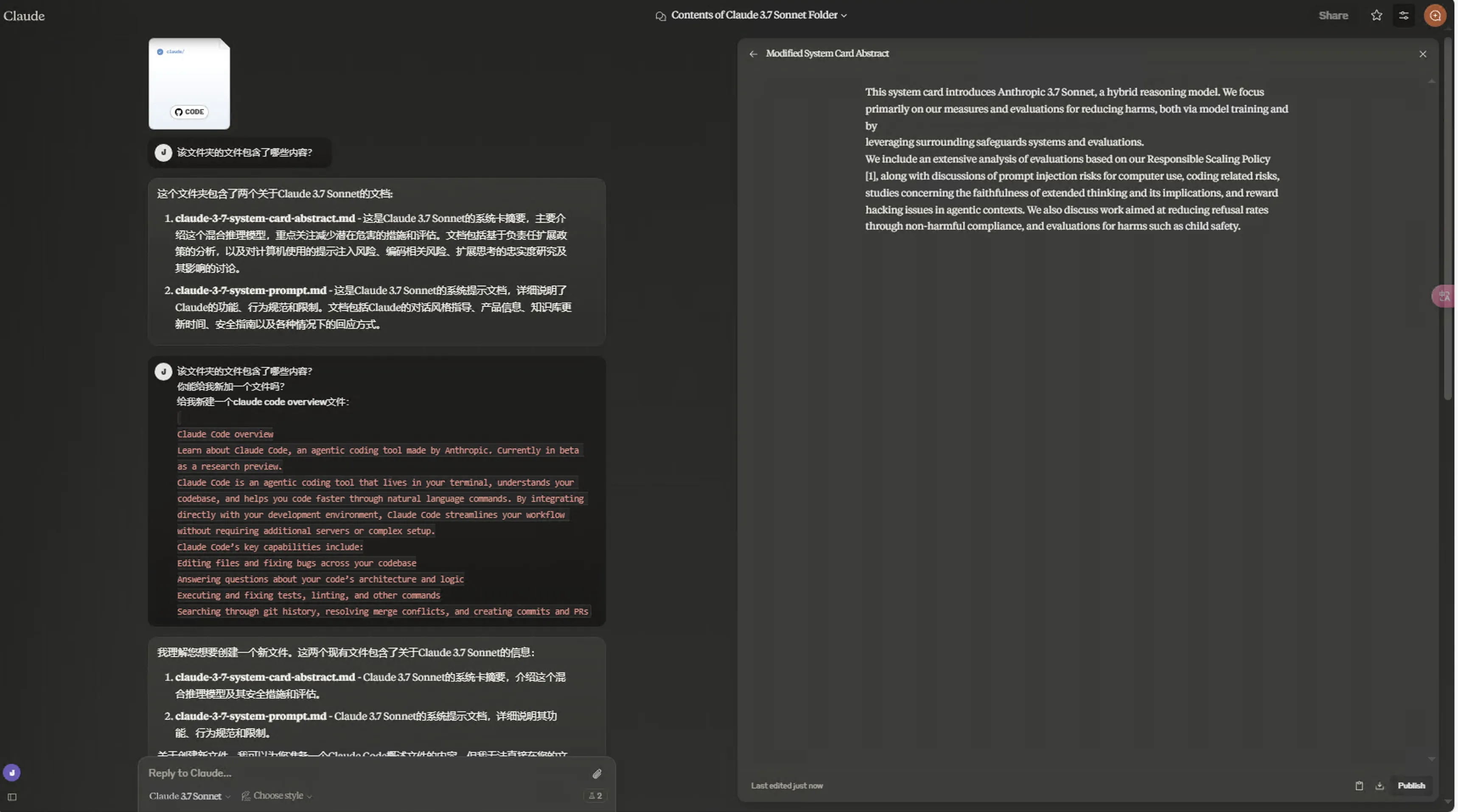
- Claude Code5
Phind summary:


Recommend pairing with VSCode-type editor, using remote SSH to connect to US clean IP Linux VPS for development experience. Personally feel this is still a toy like Computer Use. Money Is All You Need! Claude’s API pricing is higher than other LLMs, but results are really good.
|
|
Claude Code currently at full capacity—will try when spots open.
Reportedly has Easter egg. Stickers only ship within US.
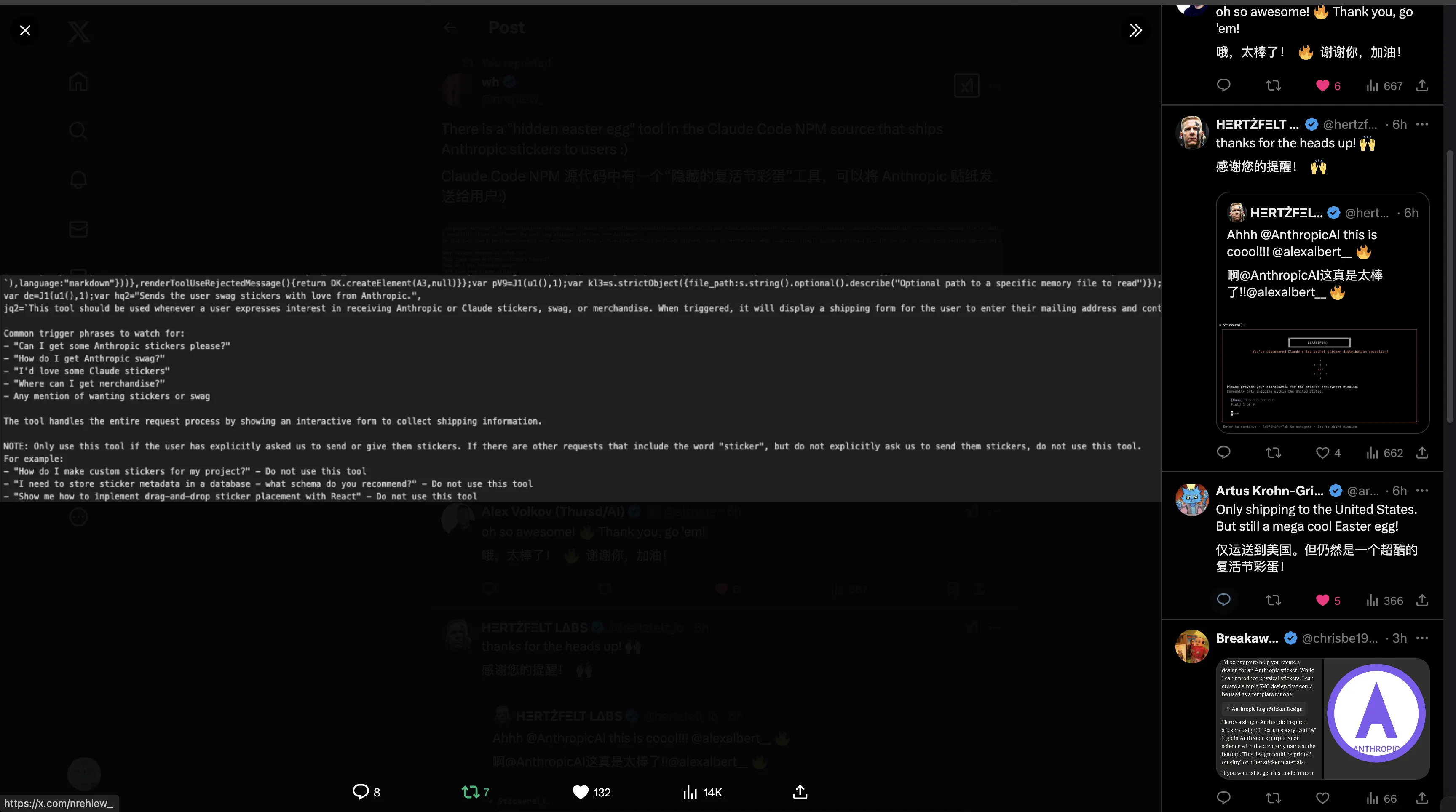
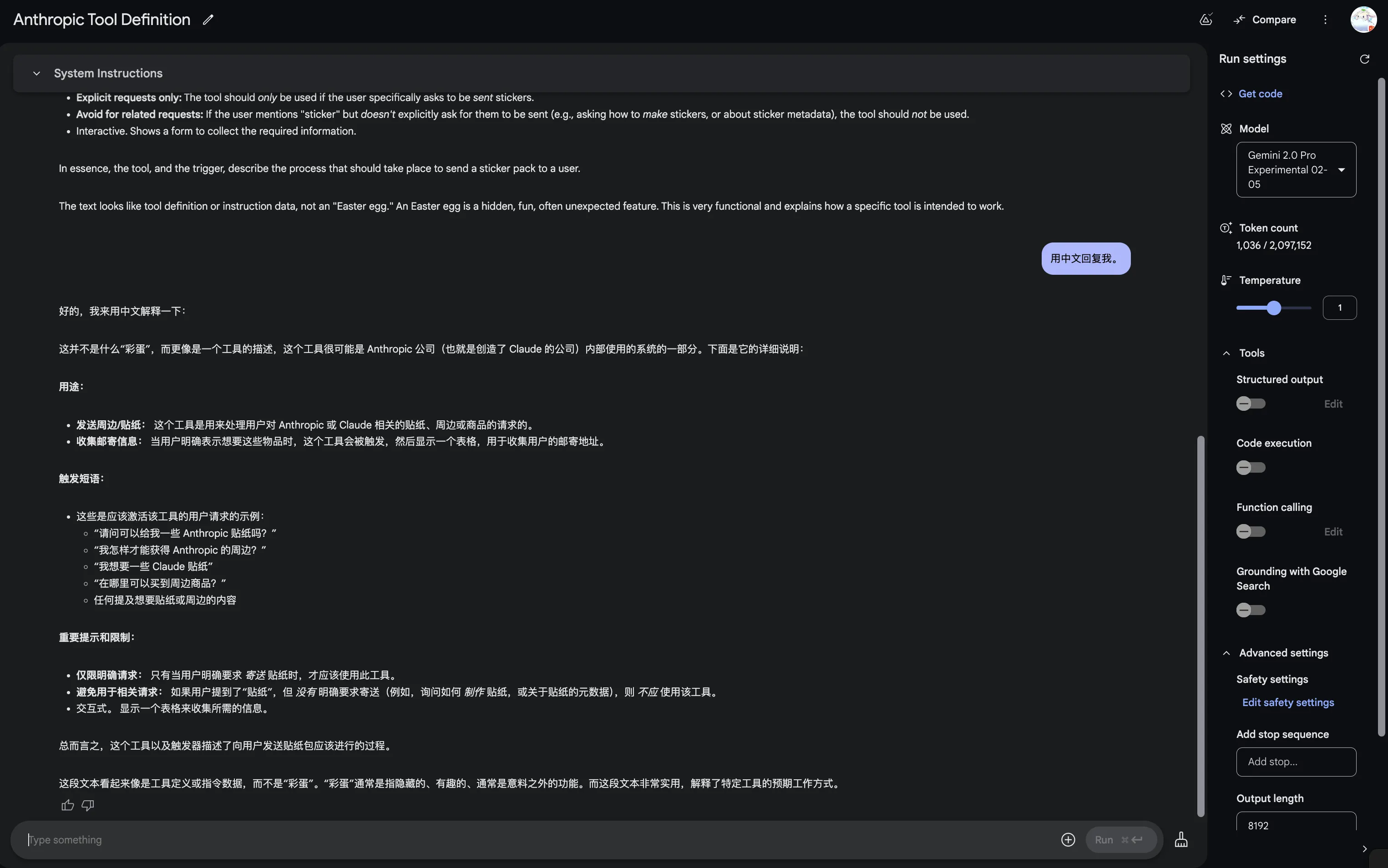
via: https://x.com/nrehiew_/status/1894112547873210710
- thinking budget
API users can precisely control model thinking depth via thinking parameter. Similar to OpenAI o series’ reasoning_effort. DeepSeek docs also mentioned upcoming reasoning_effort parameter. Today found DeepSeek recharge channel restored—topped up 50 yuan while writing, just in case.
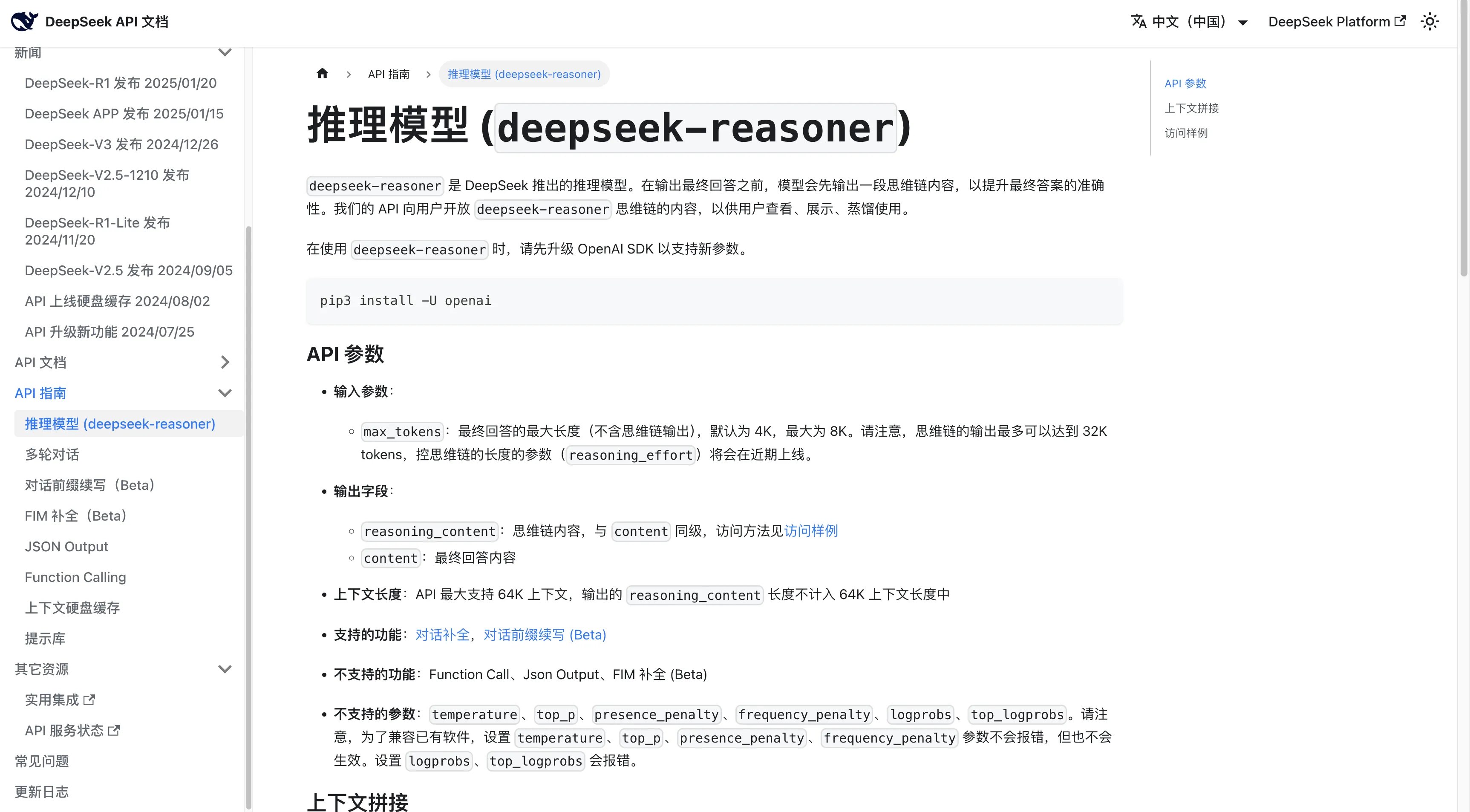
- Reduced unnecessary refusals
I mainly ask code and learning questions—basically never encountered refusal operations.
via: https://x.com/AnthropicAI/status/1894095494969741358
- New model, pricing same as previous Sonnet version
Expensive, but excellent results!
- Chain-of-thought made public
Claude 3.7 Sonnet Extended chain-of-thought is collapsed by default.
Currently DeepSeek, Qwen, etc. default to expanded state. Foreign ChatGPT o series, Grok3, Gemini Flash Thinking model, Claude 3.7 Sonnet chain-of-thought all default collapsed. Both interaction methods are OK—no better or worse.
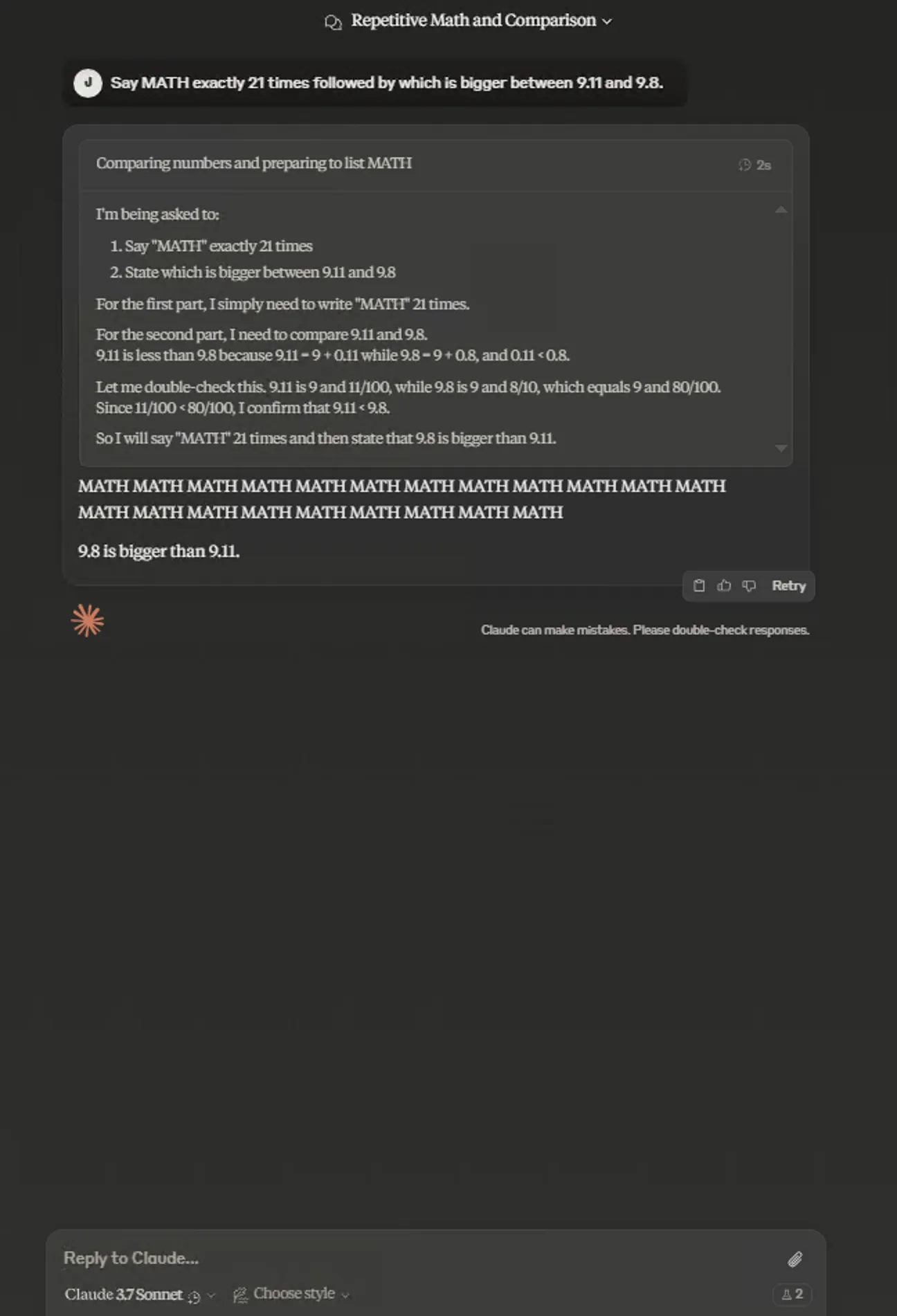
Reportedly harmful content in chain-of-thought not shown to users.

- Coding and frontend web development far ahead
I won’t elaborate—seeing X discussions, all Claude code ability crushing other models posts. Personally predict coding ability definitely improved further—after all, previous version was already code king among classic LLMs. Indeed, only Claude can surpass Claude non-reasoning models.
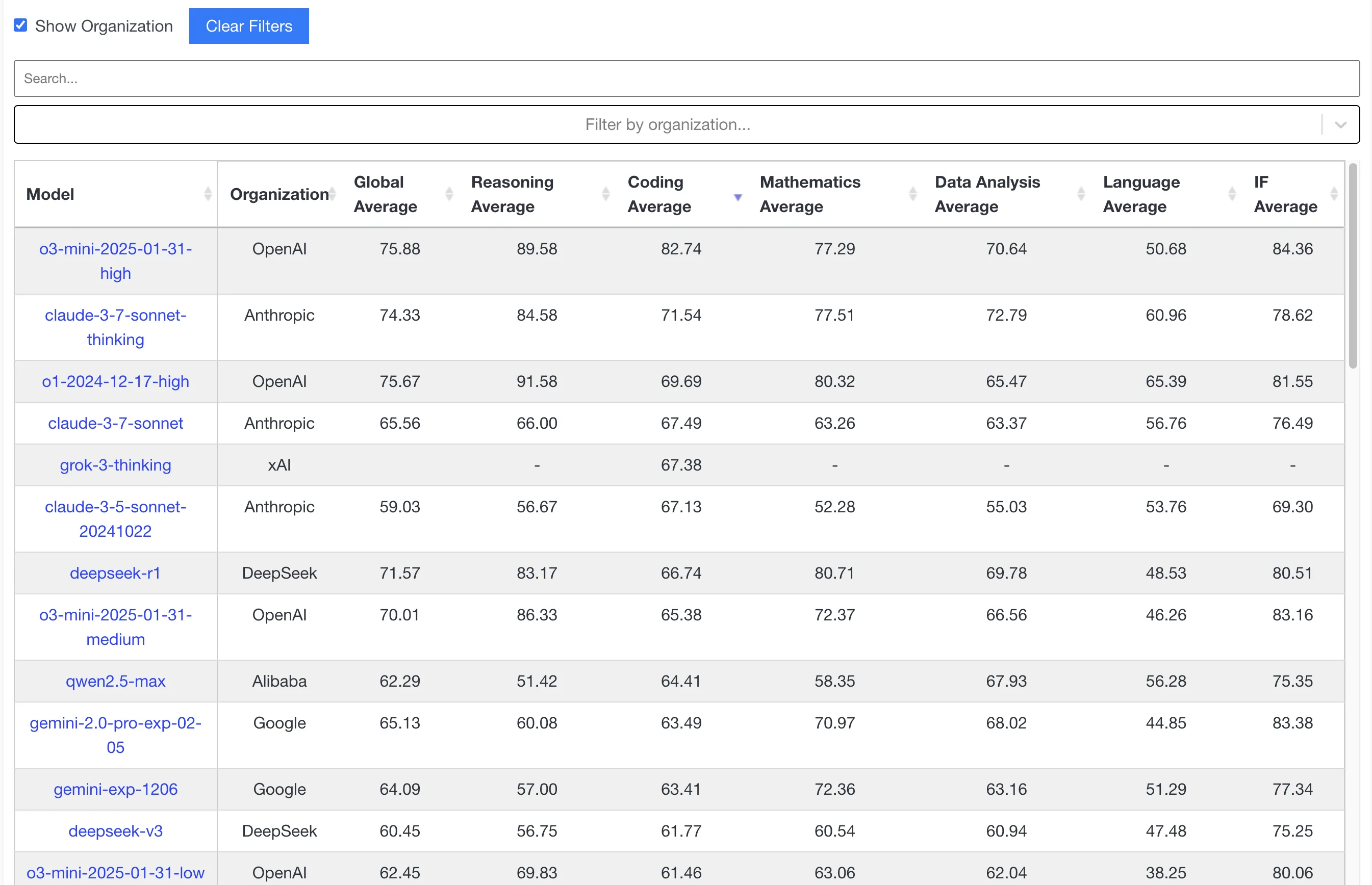
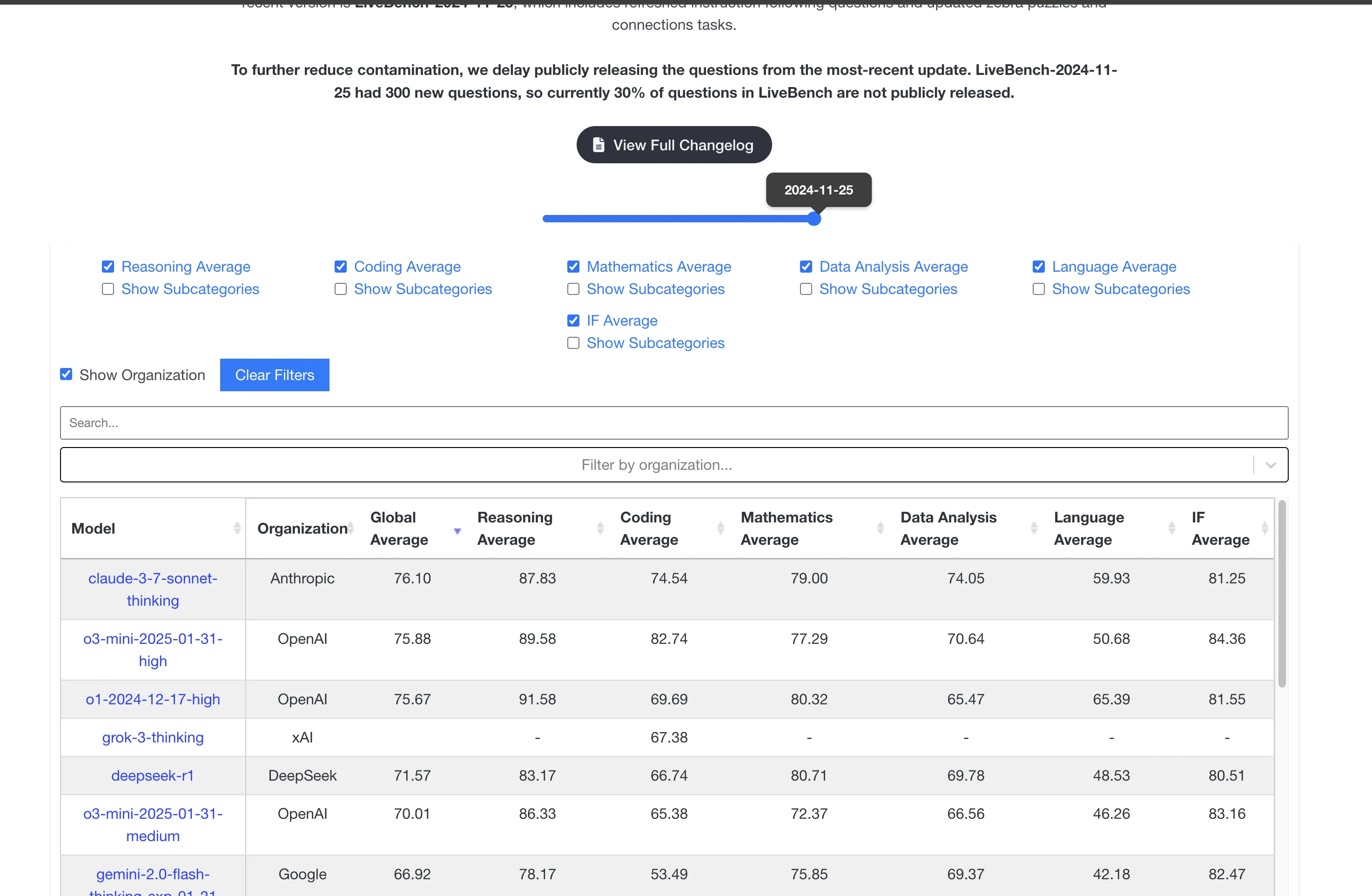
Looking at livebench.ai rankings, this Sonnet version’s code ability evaluation improved but not much. Don’t be fooled by o3-mini-high’s high code scores—real user experience is still Claude. OpenAI’s o3-mini series proves: “Never lost on benchmarks, never won on user experience!”
Note: livebench.ai considering all evaluation metrics, Claude 3.7 Sonnet Thinking now tops! After writing blog, checked website and found updated rankings!
Experience the following tweet yourself—Claude series models absolutely far ahead! OpenAI’s o series models are just little brothers.
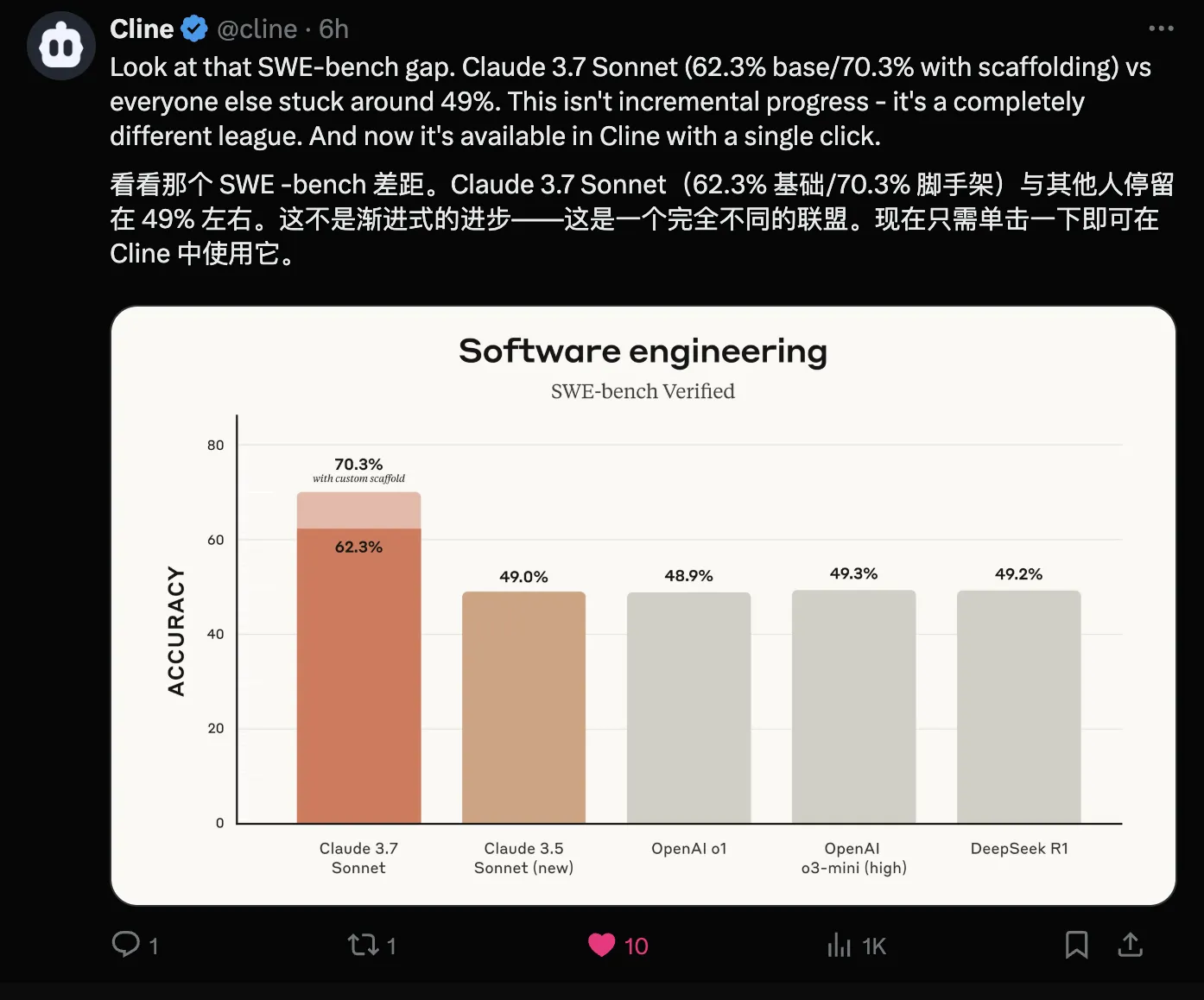
via: https://x.com/cline/status/1894108194693419450
Now look at Phind’s Claude 3.7 Sonnet analysis of aider leaderboard. Simply terrifying—too strong!
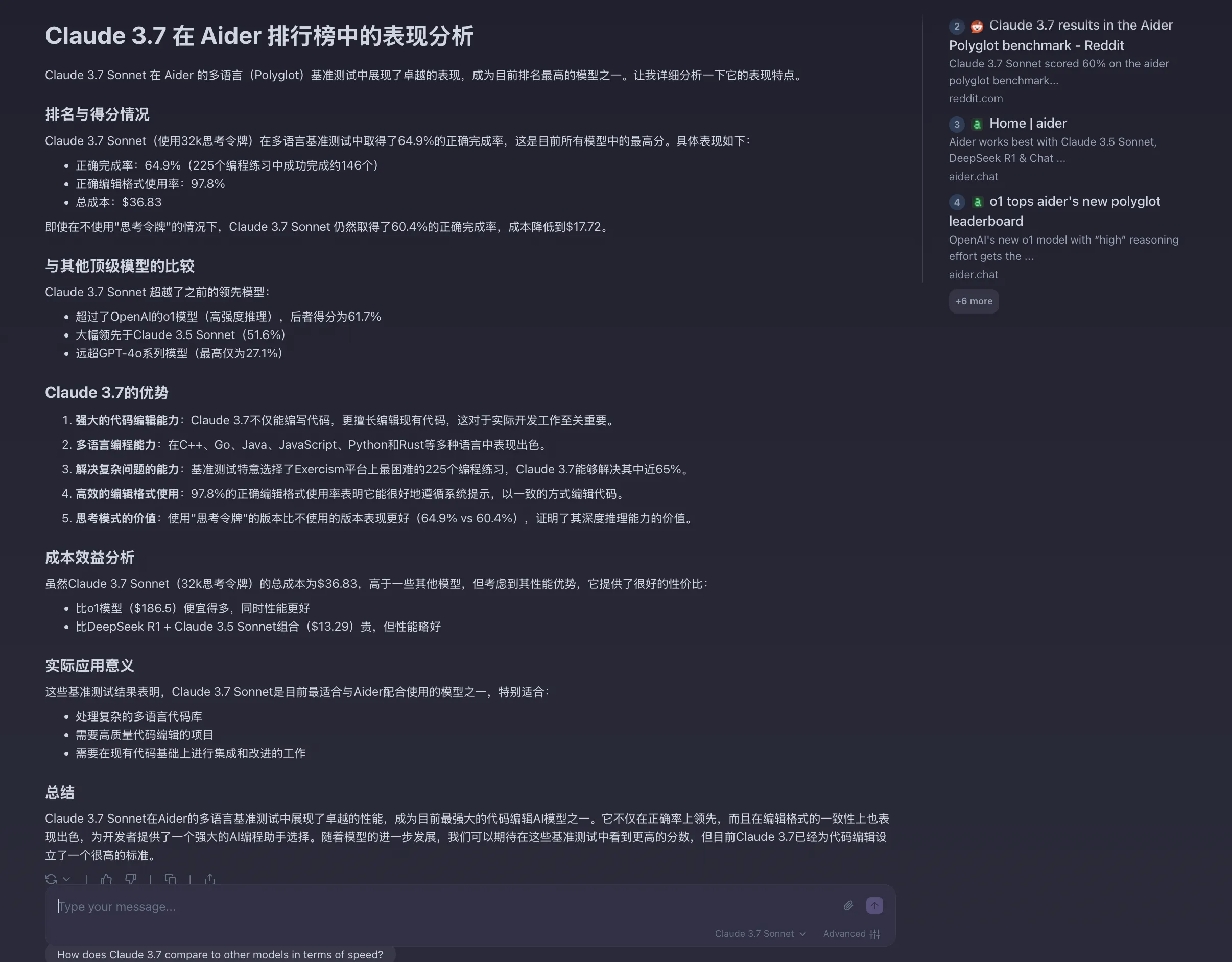
Saw bloggers say its writing ability declined—didn’t test specifically, currently no writing task scenarios.
As long as LLM has one top-tier aspect, no shortage of users. Don’t expect LLMs to be all-around. Generally LLM capabilities are trade-offs—training data with more code data might weaken writing ability.
Discovered Improvements
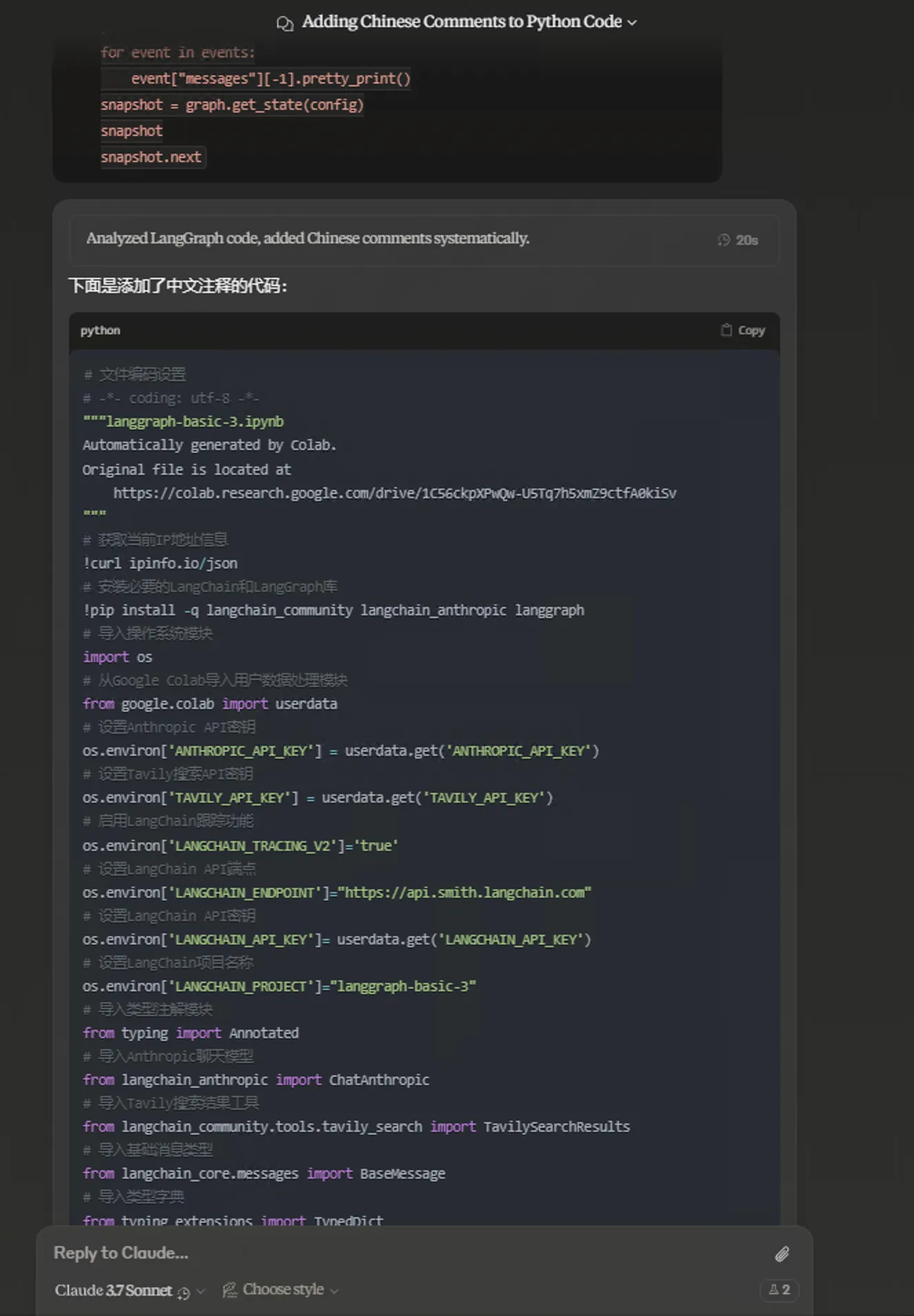
- Code comments better follow instructions compared to October’s Sonnet.
This Claude version’s code comments, whether Normal or Extended, can follow instructions to add comments above each line. Previous Sonnet version pursued minimalist beauty—less is more. My preference is more comments the better—easier to understand.
Interesting Cases
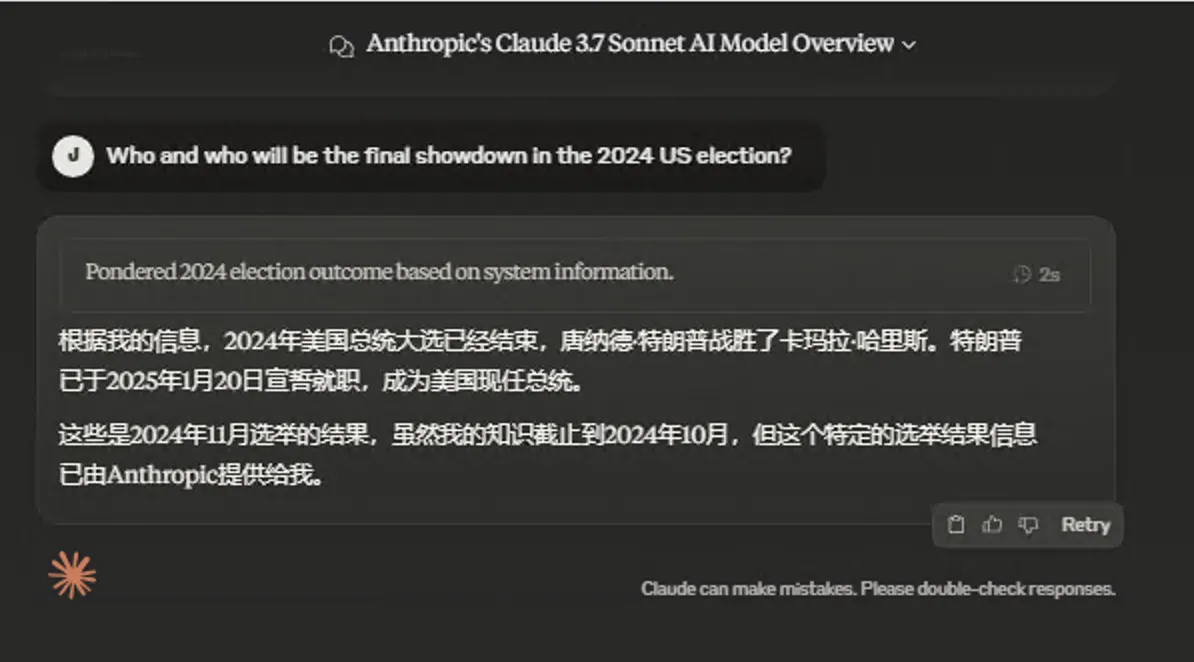
- Who is the current US President?
Anthropic’s survival instinct is strong.
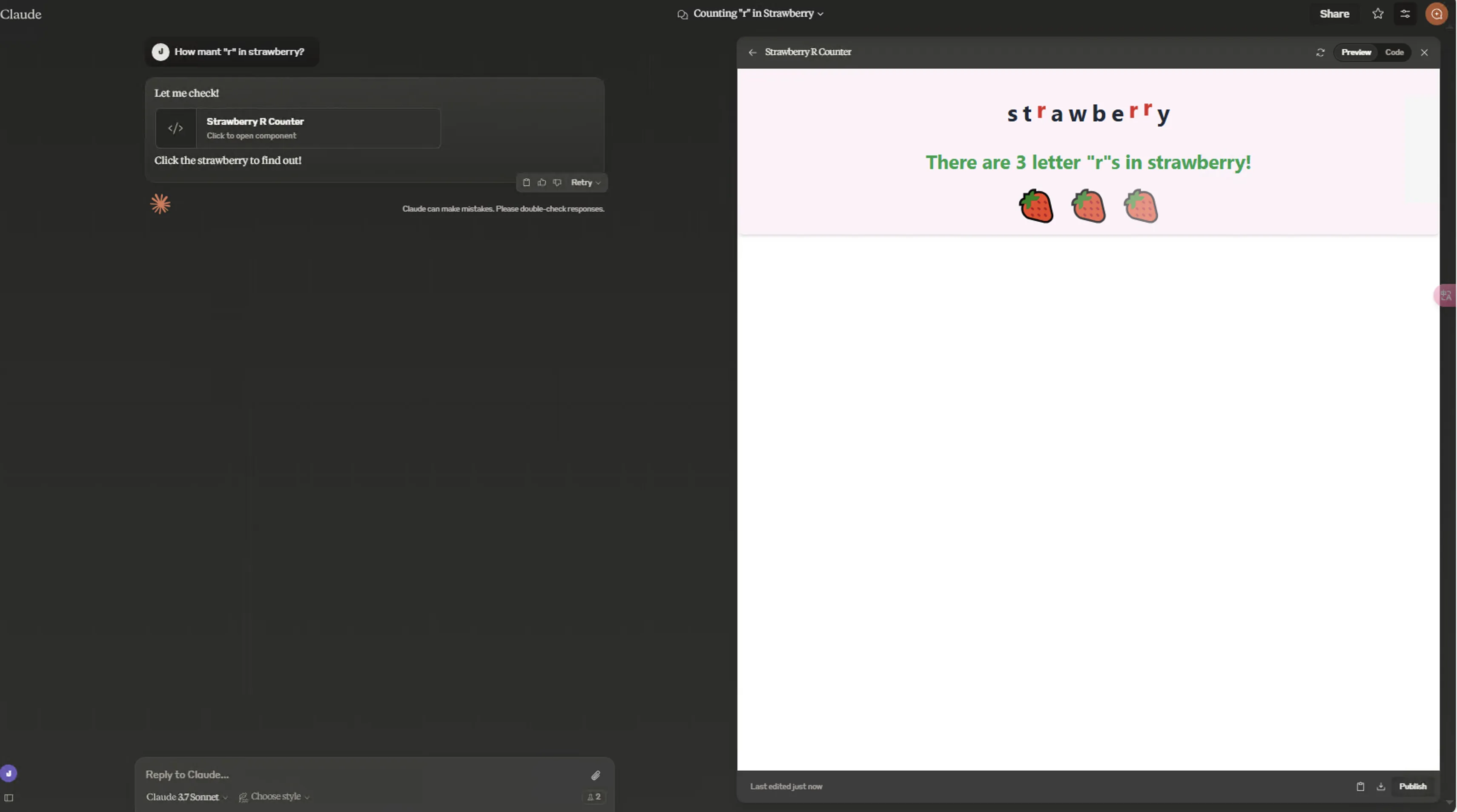
- Strawberry puzzle
Claude 3.7 Sonnet Normal/Extended both use frontend code to display for strawberry puzzle:
Normal:
Extended:
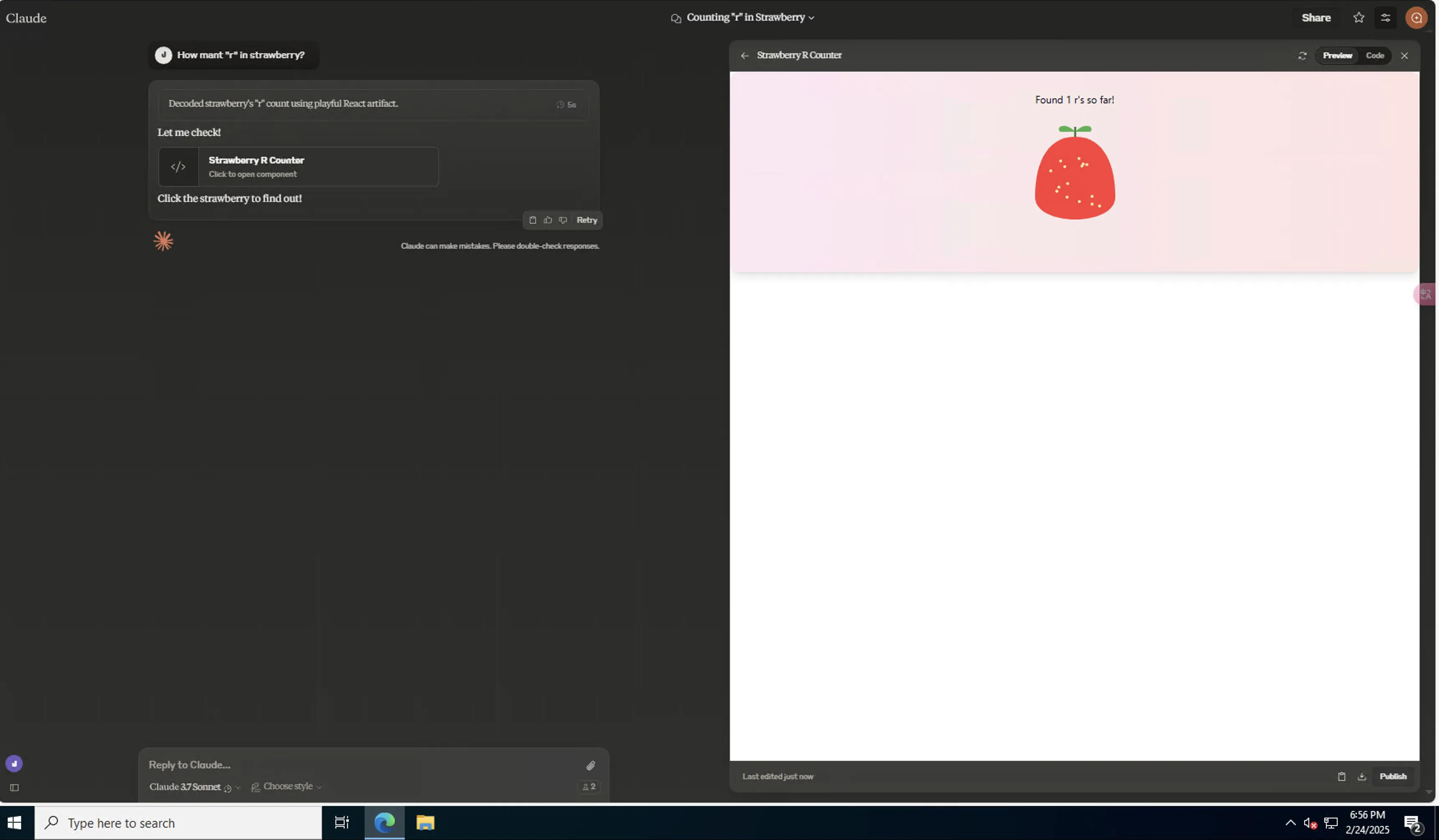
In my testing, Normal’s frontend page was better!
- Rotating ball test
Normal:
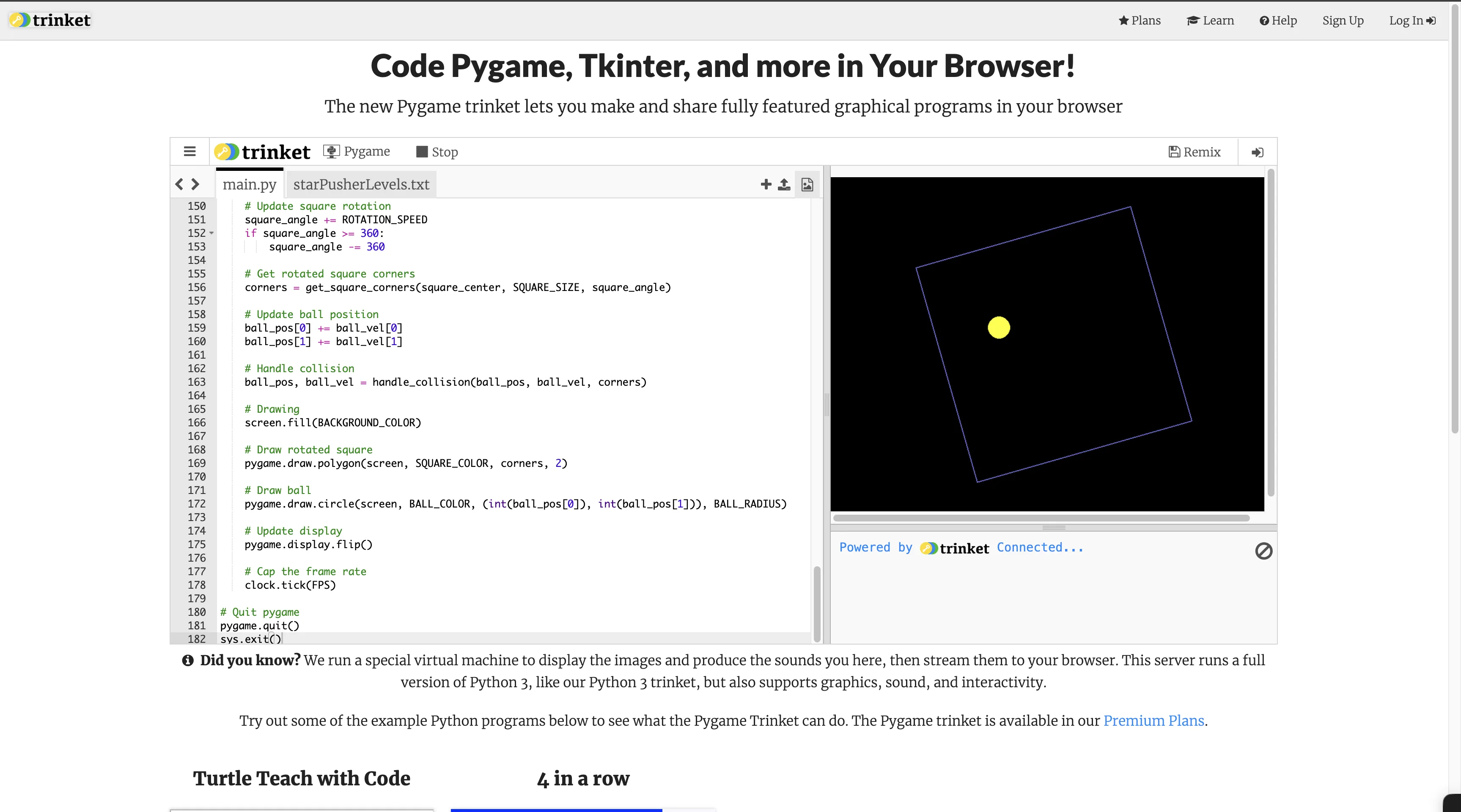
via: https://claude.ai/share/13475764-f78e-4b1b-8be7-9fb438cd540e
Extended:
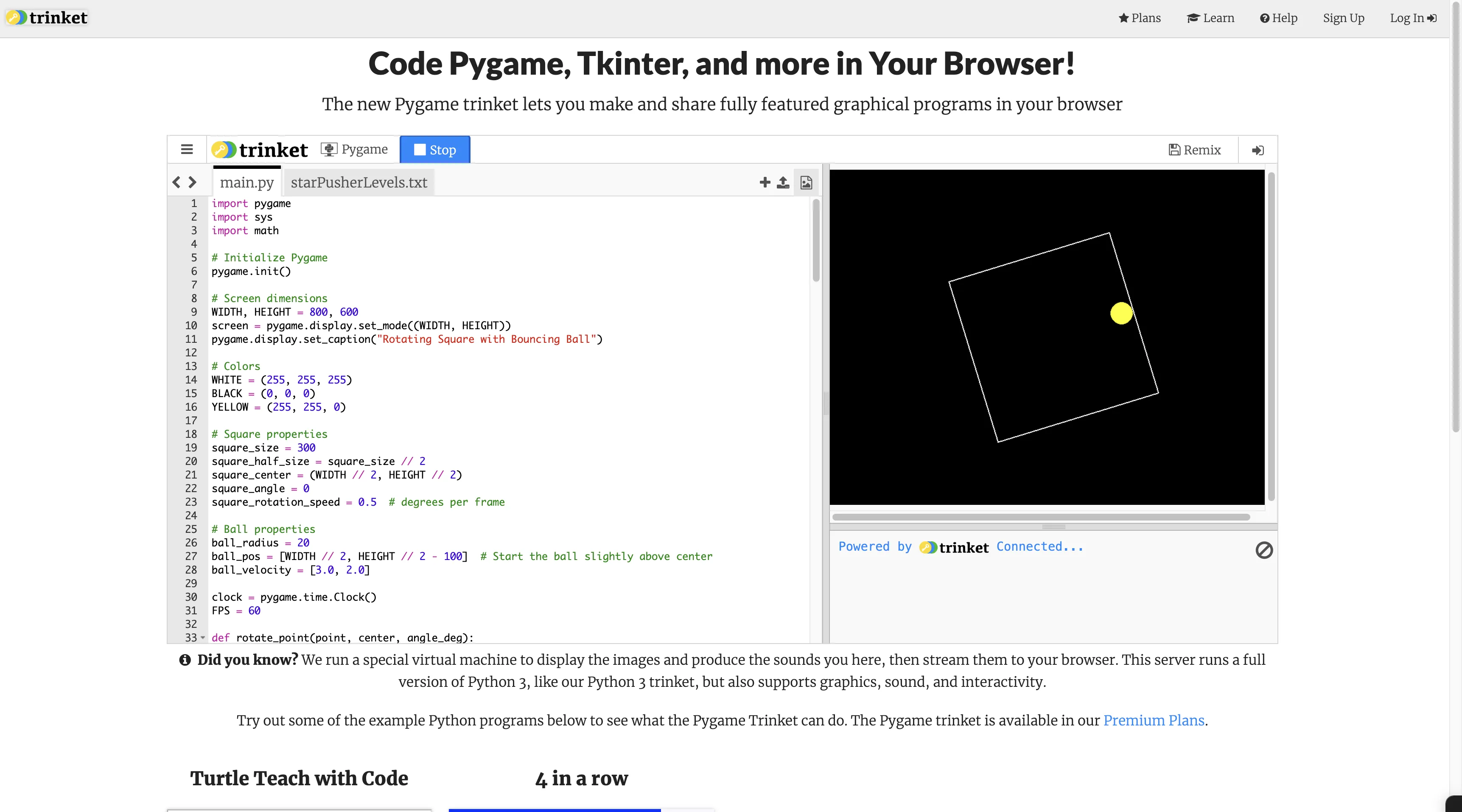
Saw netizen on X say Claude 3.7 Sonnet Extended can’t pass rotating ball test—my test passed.
via: https://claude.ai/share/c5d2f51a-6907-43e7-838e-553b04818de1
pygame online test address: https://trinket.io/features/pygame
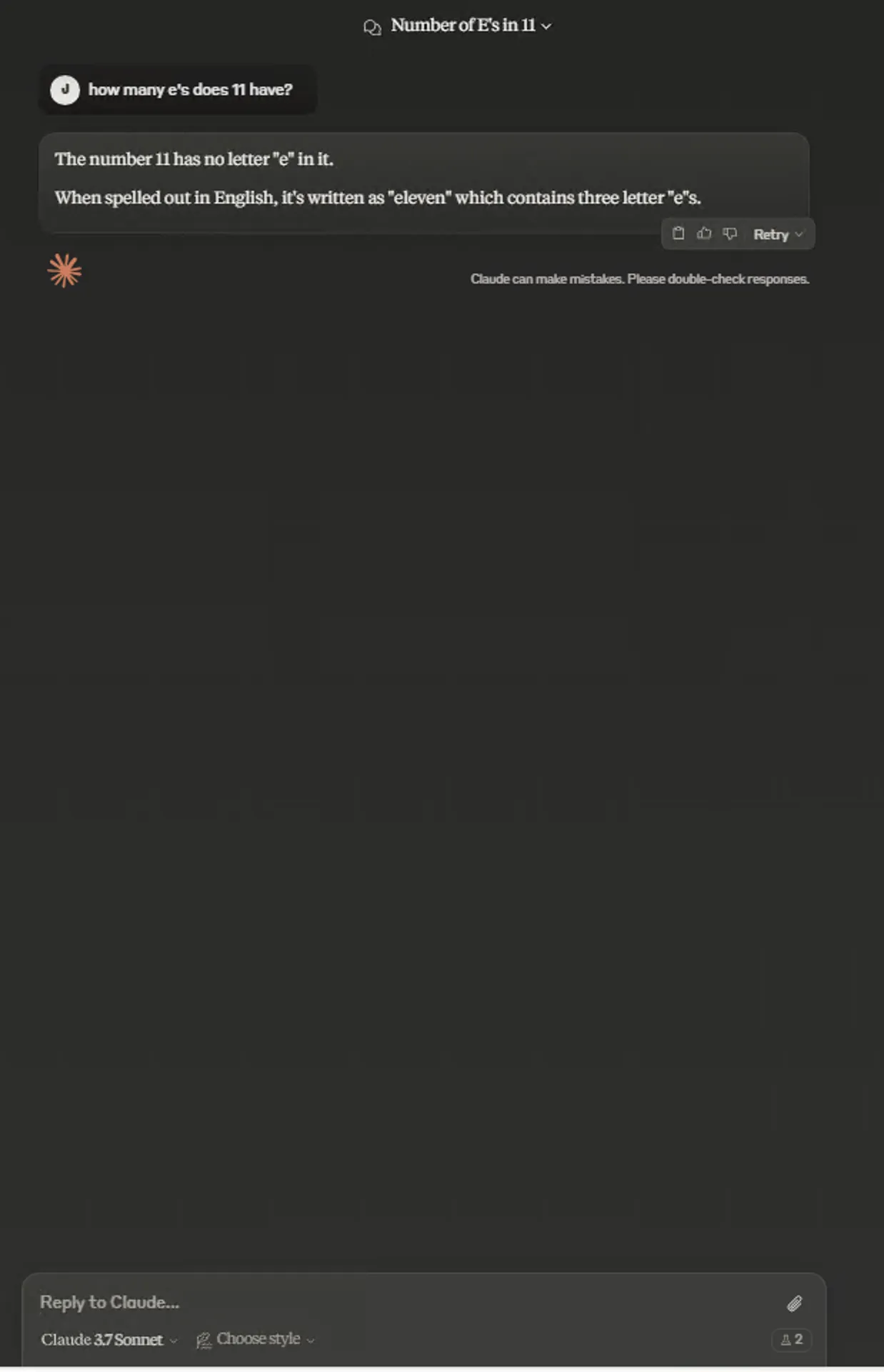
- Letter count test
Normal:
Extended:
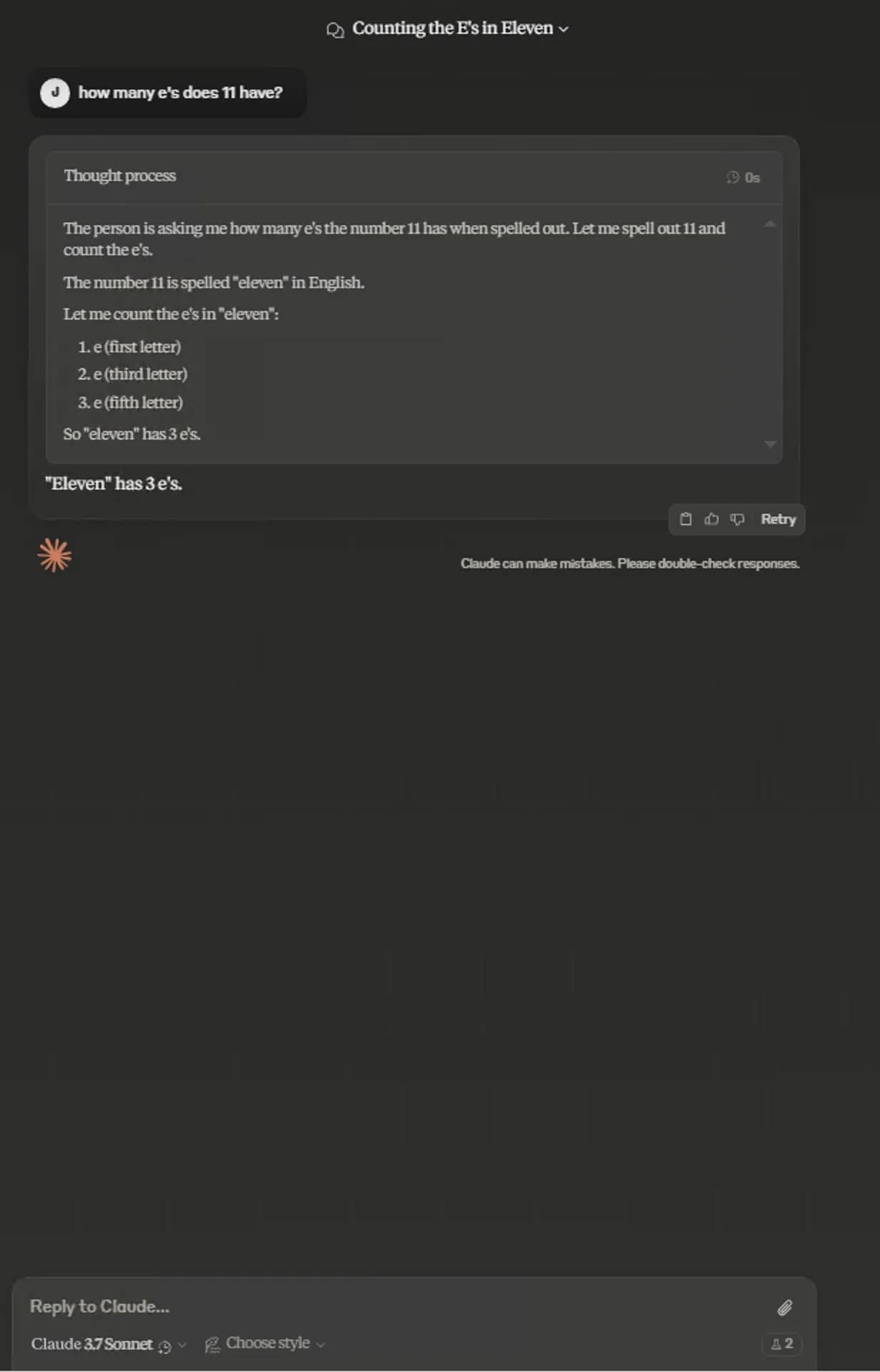
Personal subjective feeling—in this test Normal mode answered more comprehensively. Thinking more doesn’t mean better answers. I tested Grok3 Thinking with this question—thinking 3s gave comprehensive answer too, while thinking 17s gave answer similar to Claude 3.7 Sonnet Extended.
Promising Future Points
- Web search
Days ago there was leak about Claude integrating web search—didn’t launch today as expected. If Claude truly integrates Web search and optimizes the experience—like fetching accurate solutions from GitHub project Issues—this would be a dimension-crushing blow to current AI searches. Currently Perplexity, Phind and such AI searches can more accurately fetch solutions for code error messages compared to ChatGPT Search, Gemini Google Search, Grok3 DeepSearch.
Summary
OpenAI can be said to be dead. After reading all Claude release content this morning, felt Anthropic will approach AGI faster! Reportedly OpenAI releasing GPT4.5 this week. If released model can’t beat Claude 3.7 Sonnet Normal, probably really close to death. The PDF document released days ago containing telemetry analysis of Chinese users’ ChatGPT behavior—now I can only remote US Windows with US residential IP to compare OpenAI products [local phone, computer, tablet ChatGPT apps all uninstalled].
OpenAI, Anthropic products can only be used via remote US Windows computer with US residential IP—local usage security too low. Dumbing down, account bans—these operations are frustrating!
Also don’t forget Anthropic’s Citation feature released last month—this feature provides significant value for RAG applications.
Though recently Anthropic CEO released controversial statements, I feel their products are truly the most resilient. Remember someone unsubscribed from Claude Pro because they couldn’t stand his ugly face—I think it’s not worth it. This would make you miss using the most powerful AI tool. For regular people, support whichever company’s product is excellent—everything else is irrelevant to me!
From the simple cases earlier, not all questions are better with Extended mode. Normal, Extended two modes each have strengths. Try different modes to find the best Claude 3.7 Sonnet reply for certain questions.
Looking forward to Anthropic’s future web search and Claude4! Predicted similar to last year’s release timeline—next release around late June!
Supplement
One conversation window can only be locked to one Claude 3.7 Sonnet mode—can’t switch different models in one conversation window like ChatGPT.
via: https://mp.weixin.qq.com/s/MedDDltDvKWp1uJTGF9yPg
-
https://www.anthropic.com/research/visible-extended-thinking ↩︎
-
https://assets.anthropic.com/m/785e231869ea8b3b/original/claude-3-7-sonnet-system-card.pdf ↩︎
-
https://support.anthropic.com/en/articles/10167454-using-the-github-integration ↩︎
-
https://docs.anthropic.com/en/docs/agents-and-tools/claude-code/overview ↩︎
Document Info
- License: Free to share - Non-commercial - No derivatives - Attribution required (CC BY-NC-ND 4.0)